
Las fuentes proporcionadas ofrecen un análisis exhaustivo de los Modelos de Lenguaje por Difusión (DLM), un marco generativo emergente que constituye una potente alternativa a los modelos autorregresivos (AR) tradicionales. A diferencia de la generación secuencial token a token, los DLM utilizan un proceso iterativo de eliminación de ruido para generar texto en paralelo, reduciendo significativamente la latencia de inferencia y capturando un contexto bidireccional más rico. La investigación clasifica estos modelos en arquitecturas de espacio continuo, espacio discreto e híbridas, detallando sus estrategias únicas para el preentrenamiento, el ajuste fino supervisado y el aprendizaje por refuerzo. Más allá de la lingüística, el texto destaca la creciente versatilidad de los DLM en aplicaciones multimodales, como la síntesis unificada de imágenes y texto, y tareas de razonamiento complejas. Si bien las fuentes reconocen los obstáculos actuales en la eficiencia computacional y el manejo de secuencias largas, enfatizan la rápida evolución y el potencial comercial de este paradigma en la búsqueda de la inteligencia artificial general.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "A Survey on Diffusion Language Models", por Tianyi Li, y colegas. Publicado el 4 de Junio de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Normalmente, cuando hablamos de una computadora escribiendo texto, hay esta suposición subyacente de que opera en una sola línea de archivo. Algo así como un mecanógrafo muy, muy rápido. Le das a una IA una instrucción (un "prompt") y ella simplemente lanza la respuesta, de izquierda a derecha, palabra por palabra.
Beto
Sí, es un proceso completamente secuencial. Hemos construido estos sistemas increíblemente complejos, pero su mecanismo de salida fundamental es básicamente una cinta de ticker digital.
Alicia
Correcto. Una palabra sigue estrictamente a la siguiente. Es predecible y, honestamente, tiene todo el sentido para nosotros porque es exactamente como escribimos tú y yo. Quiero decir, yo no escribo el final de una oración antes de averiguar el principio.
Beto
No, por supuesto que no. Y ese sesgo biológico está incorporado en casi todos los modelos de IA importantes hoy en día. Pero si miras la vanguardia de la investigación de IA ahora mismo, esa línea de archivo única está siendo desmantelada.
Alicia
¡Oh, vaya!
Beto
Sí, estamos viendo un panorama generativo que está operando en todas direcciones a la vez.
Alicia
De acuerdo, desglosémoslo.
Bienvenidos a un nuevo análisis profundo. Si están escuchando ahora y usan ChatGPT para redactar un correo electrónico o, si son desarrolladores construyendo sobre modelos de lenguaje grandes ("large language models", LLM), conocen los conceptos básicos de cómo se siente la generación de texto por IA.
Beto
Pero hoy, nuestra misión es mirar por el horizonte.
Alicia
Exacto. Estamos explorando una encuesta muy completa sobre algo llamado "modelos de lenguaje de difusión" ("Diffusion Language Models", DLM). Está reunida por un equipo de investigadores de VILA Lab, MBZU-AI, y Tsinghua University. Y lo que estamos viendo es una convulsión estructural fundamental en la forma en que las máquinas crean lenguaje.
Beto
Una convulsión que está intentando resolver los enormes cuellos de botella de velocidad y eficiencia que actualmente están frenando todo el campo de la IA.
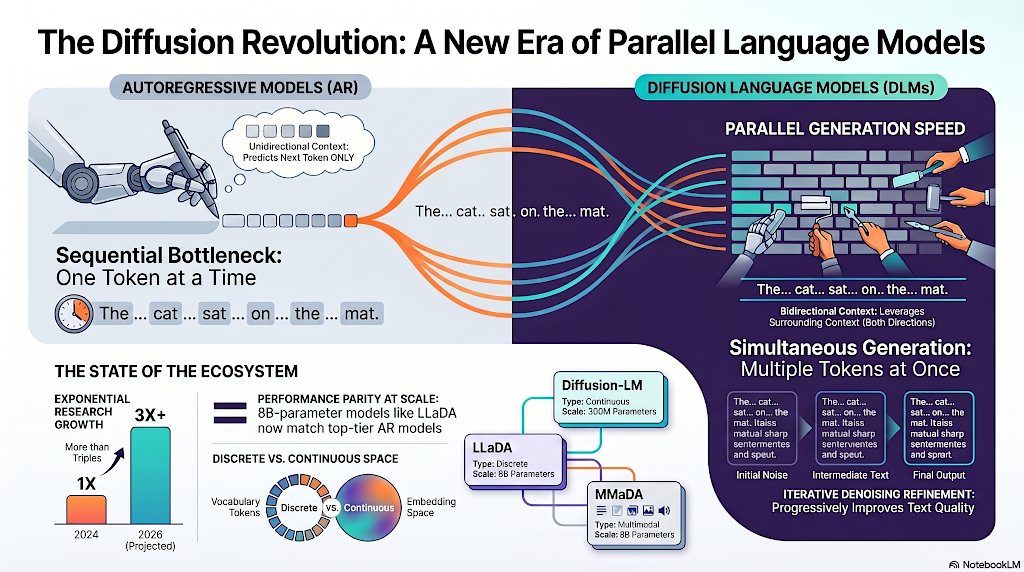
La Revolución de la Difusión: Una Nueva Era de Modelos de Lenguaje Paralelos
Alicia
Correcto. Porque ahora mismo, los campeones reinantes de la IA son lo que llamamos "modelos autorregresivos", o AR ("auto-regressive models"). Como dijimos, generan texto de forma secuencial, estrictamente de izquierda a derecha, un solo "token" a la vez.
Beto
Que es realmente como el texto predictivo en el teclado de su teléfono. Lo han escalado hasta un grado masivo usando miles de millones de parámetros.
Alicia
Sí.
Beto
Y para ser justos, eso es increíblemente efectivo para crear oraciones coherentes. Pero si retrocedemos y miramos el lado de la computación física de esto, crea un problema masivo llamado "cuello de botella de inferencia" ("inference bottleneck").
Alicia
De acuerdo. Un cuello de botella de inferencia. Desglósalo para nosotros.
Beto
Piensa en cómo funciona un chip de computadora. Las GPU modernas están diseñadas para hacer miles de cosas simultáneamente. Pero con un modelo autorregresivo, esa máquina tiene que esperar a que el número tres de la palabra esté completamente finalizada antes de que pueda siquiera empezar a hacer los cálculos para la palabra número cuatro.
Alicia
Porque la palabra número cuatro depende totalmente del contexto de la palabra número tres.
Beto
Lo entiendes bien. Simplemente no puedes paralelizar ese proceso de generación. Es un límite matemático estricto en la eficiencia y velocidad computacional.
Alicia
Así que es básicamente un atasco de tráfico.
Beto
Exacto. Podrías construir una supercomputadora del tamaño de una ciudad. Pero para una solicitud única, todavía estás atascada esperando en esa línea de archivo única.
Alicia
Así que los modelos AR están chocando contra un límite de velocidad física. Necesitamos un nuevo paradigma. Y mirando el grupo de investigación reunido hoy, la respuesta parece ser los modelos de difusión.
Ahora, si están al tanto del espacio de la IA, probablemente conocen los modelos de difusión del mundo de la IA visual. Estos son los motores detrás de herramientas como Stable Diffusion, que generan imágenes, o Sora para generar video.
Beto
Y la forma en que operan de forma nativa es simplemente fascinante. Un modelo de difusión no dibuja una imagen línea por línea, o píxel por píxel.
Alicia
No, la esboza.
Beto
Comienza con un lienzo de puro ruido matemático aleatorio y estático, simplemente abstracto. Luego, a través de un proceso iterativo de múltiples pasos, des-ruidifica progresivamente ese estático. Paso a paso, filtra la aleatoriedad hasta que emerge una imagen cristalina a partir del caos.
Alicia
De acuerdo, permíteme usar una analogía aquí. Así que un modelo AR es como una máquina de escribir, chasqueando una letra a la vez. Pero un modelo de difusión es más como un escultor que talla un bloque entero de mármol ruidoso a la vez.
Beto
Oh, esa es una forma brillante de visualizarlo. El escultor no está puliendo la parte superior de la cabeza por completo antes de siquiera empezar a cincelar los hombros.
Alicia
Correcto.
Beto
Está mapeando y refinando toda la forma simultáneamente.
Alicia
De acuerdo, eso tiene todo el sentido para un objeto físico o una imagen. Pero espera. El texto no es un bloque continuo de píxeles. Puedo imaginar fácilmente colores ruidosos o estática literal en una pantalla de televisión. ¿Pero cómo tienes una palabra ruidosa?
Beto
Correcto. Porque las palabras son discretas.
Alicia
Sí, una palabra es una cosa discreta. No puedes tener la mitad de la palabra "manzana". O es manzana, o no lo es.
Beto
Esto plantea una pregunta importante. Y honestamente, es exactamente el obstáculo que los científicos tuvieron que superar para crear modelos de lenguaje de difusión ("Diffusion Language Models") o DLMs.
Pero antes de entrar en la mecánica de cómo solucionan eso, veamos el porqué.
Alicia
¿Por qué pasar por el problema?
Beto
Exacto. Al tratar los textos como ese bloque de mármol, los DLMs obtienen ventajas increíbles. Primero es la generación paralela. Pueden generar párrafos enteros de texto a la vez.
Alicia
Sorteando ese cuello de botella de inferencia que mencionaste antes.
Beto
Correcto. Segundo es el contexto bidireccional. Cuando un modelo AR escribe el comienzo de una oración, está efectivamente ciego. No tiene idea de cómo terminará la oración.
Alicia
Porque aún no ha llegado allí.
Beto
Exacto. Pero un DLM ve el final de la oración mientras refina el comienzo.
Alicia
Oh, así que está escribiendo teniendo en cuenta todo el destino.
Beto
Sí. Y tercero, que es quizás lo más poderoso. La capacidad de refinar y corregir sus propios errores iterativamente.
Alicia
Espera, ¿en serio? ¿Puede editarse a sí mismo?
Beto
Sí. Si un DLM comete un error lógico al principio del proceso de generación, no está bloqueado. Puede corregir ese error en un paso posterior de des-ruido antes de presentarle el resultado final.
Alicia
Mientras que un modelo AR, una vez que escribe una palabra, está permanentemente comprometido con ella.
Beto
Exacto. No hay tecla de retroceso para un modelo autorregresivo.
Alicia
OK. Esa autocorrección suena como un superpoder absoluto. Pero me trae de vuelta a mi pregunta sobre el texto ruidoso. Para entender cómo consiguen esto realmente, la investigación nos muestra dos modalidades distintas de difusión que los científicos han hackeado para trabajar con lenguaje: continuo y discreto.
Beto
Empecemos con el enfoque temprano, que fueron los DLMs continuos. Para sortear el hecho de que las palabras son discretas, lo que significa que son unidades distintas y separadas, los investigadores decidieron mapear las palabras en un espacio de incrustación continuo.
Alicia
¿Qué significa exactamente? Convertir palabras en coordenadas matemáticas abstractas.
Beto
Sí. Imagina un mapa gigante multidimensional, donde las palabras con significados similares están ubicadas cerca unas de otras. Así que en lugar de lidiar con la palabra "manzana", el modelo lidia con las coordenadas numéricas para la manzana.
Alicia
De acuerdo. Está bien.
Beto
Así que modelos como Diffusion-LM y GENIE ejecutan todo el proceso de difusión. La adición de ruido y el desruido en este espacio matemático abstracto solo mueve coordenadas. Luego, en el último paso, toman esas coordenadas matemáticas finales y las redondean a la palabra humana real más cercana en el diccionario.
Alicia
Es ingenioso, pero imagino que ese proceso de redondeo puede ponerse muy desordenado. Quiero decir, si tus cálculos te dejan a mitad de camino entre manzana y naranja, el modelo solo tiene que adivinar qué palabra discreta debe generar.
Beto
Y esa desorganización es exactamente por qué el campo cambió a la segunda modalidad, que es realmente el gran avance aquí: los DLMs discretos.
Los investigadores se dieron cuenta de que los espacios matemáticos abstractos eran demasiado perjudiciales ("lossy").
Alicia
Entonces, ¿qué hicieron en su lugar?
Beto
Construyeron una familia de modelos como D3PM, DiffusionBERT y más recientemente, LLaDA-V, que descartaron por completo las coordenadas abstractas. Operan directamente sobre los "tokens" reales, el texto mismo.
Alicia
Pero ¿cómo añades ruido a una palabra real sin usar coordenadas?
Beto
A través de un proceso de corrupción estructurada.
Alicia
Un proceso de corrupción estructurada. Así que en lugar de añadir estática matemática, corrompes el texto intercambiando palabras reales con un "token" de máscara literal.
Beto
Exacto.
Alicia
Es como un gran juego de la rueda de la fortuna o el juego de la vida loca. Empiezas con una oración que está completamente llena de espacios en blanco. Luego, el modelo mira todo el tablero y comienza a llenar los espacios en blanco por todas partes, todo a la vez, hasta que la oración está completa.
Beto
Ese es el mecanismo. El proceso de entrenamiento hacia adelante reemplaza las palabras con máscaras. Y el proceso inverso, la generación, es el modelo aprendiendo a adivinar lo que pertenece debajo de esas máscaras, desmascarando progresivamente las palabras de mayor confianza a través de múltiples pasos.
Alicia
De acuerdo, me encanta esto porque realmente imita el comportamiento humano. Es como cuando estás en una fiesta muy ruidosa y alguien te está hablando. Literalmente podrías solo escuchar tres palabras de una oración de diez palabras, pero tu cerebro mira el contexto de la sala, el tono del orador y esas tres palabras, y llena los espacios en blanco instantáneamente.
Beto
Esa es una comparación muy precisa. Es resolución de contexto paralela.
Alicia
Entonces, ¿qué significa todo esto? Tengo que hacer una objeción aquí, porque enmascarar palabras es un truco ingenioso. ¿Pero realmente está funcionando fuera de un laboratorio?
Beto
Oh, absolutamente.
Alicia
Quiero decir, ChatGPT, Llama, Claude, estos modelos autorregresivos son increíblemente inteligentes. ¿Puede el modelo de MadLib competir realmente con miles de millones de dólares en infraestructura AR?
Beto
Los datos de rendimiento son asombrosos. La encuesta detalla cómo los modelos recientes, específicamente unos como Dream-7B en LLaDA-8B, que son entrenados desde cero usando este exacto proceso de enmascaramiento discreto, están logrando un rendimiento a la par con pesos pesados como LLAMA3-8B.
Alicia
Espera, ¿en serio?
Beto
Sí, Dream-7B supera a muchos modelos AR del mismo tamaño exacto. Así que el paradigma es oficialmente competitivo. Ya no es solo un experimento de laboratorio.
Alicia
Eso es salvaje, pero espera, estoy chocando contra un muro lógico aquí. Si estos modelos están generando todo a la vez por toda la página, ¿cómo pueden realizar un razonamiento complejo?
Beto
¿Qué quieres decir?
Alicia
Bueno, piensa en cómo un modelo AR resuelve un problema de matemáticas. Usa algo llamado "cadena de pensamiento" ("Chain of Thought", CoT). Piensa paso a paso, como "lleva dos, luego multiplica por cuatro, por lo tanto la respuesta es..." Si le hago a un DLM una pregunta matemática compleja y escupe toda la respuesta en paralelo, ¿no pierde ese proceso lógico paso a paso?
Beto
Ese es la paradoja definitiva de los modelos de lenguaje de difusión. ¿Cómo se enseña a un pensador paralelo a hacer lógica secuencial?
Alicia
Correcto.
Beto
Y la solución a esto es ingeniosa. Primero, desarrollan un método llamado "difusión del pensamiento", o DOT ("diffusion of thought"). En lugar de generar pasos de razonamiento secuencialmente en la pantalla, DOT entrena al modelo para refinar su razonamiento intermedio en paralelo durante todo el proceso de des-ruido.
Alicia
¿Así que el pensamiento todavía está sucediendo?
Beto
Sí, solo está sucediendo a través de los pasos iterativos invisibles de la difusión en lugar de, de izquierda a derecha por la página.
Alicia
Oh, ya veo. Así que el borrador grueso de la lógica se establece a lo largo de todo el párrafo y luego se afina y verifica los hechos con el tiempo.
Beto
Sí. Y eso conduce a un marco aún más fascinante llamado DCoLT, que significa la "cadena de difusión de pensamiento lateral" ("Diffusion Chain of Lateral Thought").
Alicia
Pensamiento lateral. Esa es una frase increíble.
Beto
Resalta realmente una profunda diferencia psicológica en cómo operan estos modelos. Los modelos AR usan pensamiento vertical, profundizando paso uno, paso dos, paso tres. Pero los DLMs usan pensamiento lateral, mirando el problema de manera holística, explorando múltiples ideas interconectadas simultáneamente, y dejando que la solución lógica se consolide.
Alicia
Suena increíblemente humano, honestamente. Como a veces no resuelves el problema complejo siguiendo una línea lógica recta. La respuesta simplemente encaja cuando retrocedes y miras el panorama completo.
Beto
Exacto.
Alicia
Pero enseñar a una máquina a hacer eso debe ser una pesadilla, especialmente cuando introduces el aprendizaje por refuerzo.
Beto
Oh, es un obstáculo técnico extremo. El "aprendizaje por refuerzo" ("Reinforcement Learning", o RL) es esencialmente cómo alineamos estos modelos para que sean útiles y lógicos. Es cómo les damos una calificación durante el entrenamiento. En los modelos AR, nuestros algoritmos recompensan al modelo basándose en la probabilidad de registro ("log probability") paso a paso de sus palabras generadas.
Alicia
Pausemos allí, porque la probabilidad de registro suena intimidante. Desglosemos eso para el oyente.
Beto
Claro. Así que en el RL estándar, el modelo obtiene una calificación por cada palabra individual basada en la probabilidad de la elección correcta en ese paso secuencial exacto. Si el paso uno es correcto, obtiene puntos. Si el segundo paso sigue lógicamente al primero, obtiene puntos.
Alicia
Porque es fácil calificar un examen de matemáticas cuando el estudiante muestra su trabajo línea por línea.
Beto
Exacto. Pero a los DLMs les falta esa probabilidad de registro secuencial. No generan una ruta única de izquierda a derecha. Así que si toda la respuesta emerge de una vez, ¿cómo asignas crédito a los pensamientos individuales que la llevaron a ese resultado?
Alicia
Sí, pensé que lo usaban.
Beto
Para resolver esto, los investigadores hackearon el sistema con algoritmos como diffu-GRPO y UniGRPO.
Alicia
GRPO. Ese es un acrónimo que estamos viendo por todas partes últimamente. "Optimización de política relativa de grupo" ("Group Relative Policy Optimization"). ¿Cómo funciona para la difusión?
Beto
Bueno, sin ahogarnos en las matemáticas, diff-GRPO usa estrategias de enmascaramiento únicas durante el proceso de calificación. En lugar de calificar una secuencia de izquierda a derecha, expone estratégicamente al modelo a sus propios errores generados en diferentes etapas del proceso de des-ruido.
Alicia
Significa que se detienen a la mitad.
Beto
Más o menos. Básicamente, ocultan partes de la respuesta final y le preguntan al modelo: "¿Si estuvieras a mitad de camino, cómo corregirías este fallo específico?".
Alicia
Espera, lo forzan a mirar sus propios errores a mitad de la idea.
Beto
Sí. Al obligar al modelo a evaluar y corregir su lógica defectuosa parcialmente formada de una iteración anterior, aprende a razonar lateralmente. Aprende la autocorrección. Es una forma brillante de aplicar RL sin depender de una secuencia de izquierda a derecha.
Alicia
De acuerdo, aquí es donde se pone realmente interesante. Les prometimos la velocidad deslumbrante. Pero ejecutar un proceso de difusión, incluso uno lateral, una y otra vez para refinar una oración suena agotador para una computadora.
Beto
Es computacionalmente pesado, sí.
Alicia
Correcto. Si se necesitan mil pasos de des-ruido para obtener un párrafo perfecto, ¿no estamos cambiando un cuello de botella secuencial por una carga computacional masiva?
Beto
Ese es el elefante en la habitación. Si los DLMs van a ser útiles en el mundo real, tienen que ser eficientes. Y la ingeniería actúa para garantizar que sean rápidos, es increíble.
Veamos el decodificado paralelo. Técnicas como Fast-dLLM y Dimple usan algo llamado "decodificación consciente de la confianza" ("confidence-aware decoding"). A medida que el modelo comienza a resolver el texto a partir de las máscaras, evalúa activamente su propia confianza. Si está 99% seguro de que la palabra "THE" pertenece en un lugar específico durante el paso dos, la desmascara permanentemente.
Alicia
La bloquea como si estuviera haciendo un crucigrama. Incrustas inmediatamente las respuestas fáciles, las que sabes que son correctas, para que tu cerebro pueda concentrarse completamente en las pistas difíciles.
Beto
Esa es una analogía perfecta.
Alicia
Sí.
Beto
Y al eliminar esos "tokens" resueltos de la ecuación, la GPU de repente tiene todo este ancho de banda liberado para concentrarse en los espacios en blanco de baja confianza. Eso reduce drásticamente el número de pasos requeridos.
Alicia
Esa es una asignación de recursos realmente inteligente. ¿Qué más están haciendo?
Beto
Luego está la "caché de características" ("feature caching"). Un sistema llamado FreeCache aborda la memoria interna de la red neuronal. Durante el proceso de des-ruido, muchas de las señales eléctricas de la red, sus activaciones y las capas ocultas, no cambian mucho de paso 500 a paso 501.
Alicia
Oh, lo entiendo. Así que en lugar de recalcular toda la red neuronal cada vez, simplemente reutiliza las partes estables de su memoria. Como si estuvieras horneando cinco pizzas, no apagas el horno y lo precalientas desde cero para cada pizza. Mantienes el calor central estable y solo te concentras en los nuevos ingredientes.
Beto
Eso es exactamente lo que está sucediendo a nivel de silicio.
Pero el verdadero golpe maestro en la investigación es una técnica llamada "destilación de pasos" ("step distillation").
Alicia
Oh, destilación de pasos.
Beto
Recuerda que dijimos que la difusión podría tardar mil pasos. La destilación de pasos enseña a un modelo a saltarse la fila. Tomas un DLM masivo y totalmente entrenado y lo usas como profesor. Luego entrenas un modelo estudiante más pequeño para que observe al profesor y comprima todo ese proceso de mil pasos en una fracción del tiempo.
Alicia
Un modelo estudiante.
Beto
Correcto. El artículo menciona específicamente un modelo llamado DLM1.
Alicia
Espera, voy a desafiar eso. ¿Me estás diciendo que un modelo estudiante puede comprimir mil pasos iterativos en solo unas pocas pasadas? ¿No pierde toda la capacidad de pensamiento lateral y autocorrección que acabamos de pasar diez minutos hablando si salta el proceso iterativo?
Beto
Es una preocupación completamente válida, pero piénsalo de esta manera. El modelo profesor mapea la compleja ruta de mil pasos a través del desierto para encontrar el destino lógico perfecto. El modelo estudiante no está recorriendo esa misma ruta. Está mirando el mapa que hizo el profesor y aprendiendo el atajo, la línea recta. Logra exactamente el mismo destino. Aprende el resultado del pensamiento lateral sin necesidad de tener el tiempo para hacer la reflexión misma.
Alicia
Vaya. ¿Y qué tan rápido es este modelo estudiante DLM1?
Beto
Comprime el proceso masivo de múltiples pasos en una sola pasada hacia adelante. Logra hasta una aceleración de 500 veces con calidad casi de profesor.
Alicia
Una aceleración de 500 veces que destroza por completo el límite de velocidad AR. Estás obteniendo la conciencia bidireccional holística de un modelo de difusión, pero a la velocidad de la luz.
Beto
Sí. Y si conectamos esto con la imagen más grande, fundamentalmente cambia lo que la IA es capaz de hacer en tiempo real.
Imagina una traducción en tiempo real o agentes autónomos complejos operando con latencia cero.
Alicia
De acuerdo, hemos conquistado el texto. Es rápido, es inteligente, razona lateralmente. Pero el verdadero santo grial de la IA moderna ya no es solo texto. Es multimodal. Es mezclar imágenes, video y texto en un solo cerebro. Ahora sabemos que los modelos de difusión gobiernan de forma nativa el mundo visual. Entonces, ¿qué pasa cuando combinamos DLMs de texto con modelos de difusión visual?
Beto
Obtenemos algo increíblemente cercano a una arquitectura verdaderamente unificada.
Alicia
Permíteme hacer una objeción aquí también, porque ahora mismo si usamos un modelo autorregresivo para texto, como GPT-4 y queremos ver una imagen, tenemos que sujetar un codificador de visión completamente separado a él. Es como un monstruo de Frankenstein, un cerebro de texto tratando de hablar con un cerebro de visión. ¿Necesitaron los DLMs ser Frankenstein juntos así también?
Beto
Las versiones tempranas lo necesitaron, sí. Pero el sueño unificado se está materializando ahora mismo con modelos como Muddit y FUDOKI. Porque el texto e imágenes ahora están usando exactamente los mismos mecanismos subyacentes, la difusión, puedes eliminar el enfoque de Frankenstein. Muddit elimina literalmente la necesidad de un codificador de visión explícito.
Alicia
Espera, sin codificador de visión. ¿Cómo mira una ecuación matemática una foto de un perro y la procesa de forma nativa?
Beto
Lo hace convirtiendo imágenes en códigos discretos, usando algo llamado VQ-VAE.
Alicia
De acuerdo, VQ-VAE. Traducimos eso del argot. Sé que estamos convirtiendo imágenes en texto como "tokens", ¿pero cómo?
Beto
Piénsalo como un diccionario visual. Un VQ-VAE, que significa "Autoencoder Variacional Cuantizado Vectorialmente" ("Vector Quantized Variational Auto-Encoder"), corta una imagen en una cuadrícula de pequeños parches.
Alicia
De acuerdo, una cuadrícula de parches.
Beto
Luego mira cada parche y asigna un "token" o palabra específica de un diccionario visual predefinido. Así que un parche de "pelaje marrón" podría ser el "token" número 42. Un "ojo negro brillante" podría ser el "token" 815.
Alicia
Oh, así que para el modelo, una imagen es solo un dialecto diferente de "tokens" discretos. Lee la foto del perro como una oración en un idioma extranjero.
Beto
Precisamente. Y como tanto la instrucción de texto, como la imagen, son ahora solo secuencias de "tokens" discretos, un transformador de difusión agnóstico procesa el texto y las imágenes simultáneamente de la misma manera exacta.
Alicia
Eso es increíblemente elegante. No está traduciendo entre dos cerebros diferentes. Es un cerebro que es nativamente fluido en ambos.
Beto
Y estos DLMs multimodales no son solo curiosidades teóricas. Los resultados del mundo real son impresionantes. MMaDA realmente supera a los modelos de generación de imágenes dedicados y profesionales como SDXL y la creación de imágenes.
Alicia
Espera, un modelo de lenguaje está superando a un generador de imágenes dedicado al hacer imágenes. Deja que eso se asiente.
Beto
Es notable. Y además, los DLMs generalmente están superando a los modelos AR en pruebas rigurosas de matemáticas y ciencias como GSM8K. Están demostrando que un enfoque paralelo unificado no solo es más rápido en muchos dominios complejos del mundo real. Es mediblemente más inteligente.
Alicia
Así que reuniéndolo todo. Lo que esto significa para todos nosotros que usamos estas herramientas todos los días es que estamos presenciando un salto evolutivo masivo en cómo las máquinas procesan y generan información. Estamos pasando del mecanógrafo secuencial de izquierda a derecha de los modelos autorregresivos al escultor paralelo, autocorrector y nativamente multimodal de los modelos de lenguaje de difusión.
Beto
Completamente.
Alicia
La próxima IA con la que interactúes podría ser exponencialmente más rápida, notablemente mejor para corregir sus propios fallos lógicos antes de que tú siquiera los veas y completamente fluida en texto e imágenes sin necesidad de un traductor. Es un cambio de paradigma total.
Beto
Es un cambio que redefinió los límites de la IA generativa.
Pero quiero dejarles un giro final contraintuitivo de la investigación. Algo que realmente los haga reevaluar todo lo que acabamos de discutir.
Alicia
Me encanta un buen giro. Sácalo.
Beto
Bueno, pasamos todo este tiempo maravillándonos por la libertad de los DLMs. La capacidad de generar "tokens" en cualquier orden, lateralmente, de una vez, esa flexibilidad que se supone que es el superpoder del pensamiento paralelo.
Alicia
Sí, ese era el punto.
Beto
Pero los investigadores que probaron un nuevo método de entrenamiento llamado JustGRPO encontraron algo impactante. Descubrieron que para tareas estrictas de razonamiento lógico, forzar la generación en cualquier orden flexible, realmente perjudica la precisión del modelo.
Alicia
Espera. ¿En serio? La libertad para pensar lateralmente realmente lo hace peor en la lógica.
Beto
Sí. Descubrieron que a veces, para razonar perfectamente, realmente tienes que renunciar a tu libertad y forzar un orden secuencial estricto. Nos invita a reflexionar sobre una profunda pregunta filosófica. ¿Requiere la lógica verdadera inherentemente restricciones secuenciales, incluso para una IA paralela avanzada?
Alicia
Eso es profundo.
Beto
¿Puedes realmente pensar lateralmente sobre un problema matemático complejo o el universo exige que un paso siga al otro?
Alicia
Vaya. Incluso cuando tienes el poder de tallar todo el bloque de mármol a la vez, a veces todavía necesitas seguir la línea del plano paso a paso. Esa es una idea increíble para terminar.
Gracias por acompañarnos en esta exploración del futuro de la IA. Sigan cuestionando, sigan aprendiendo, y nos encontraremos en el próximo análisis profundo.



{kind=link}