
Hoy les traigo el resumen de un artículo científico publicado recientemente en Nature, sobre Medicina Digital. Se están empezando a usar los grandes modelos de lenguaje (LLMs) de Inteligencia Artificial (IA) para hacer resúmenes de los registros clínicos de los pacientes. Y se está tratando de evaluar si estos resúmenes son precisos, cuáles son los riesgos, y cómo se pueden evitar los problemas que pudieran surgir.
Enlace al artículo original, en inglés: "Evaluating clinical AI summaries with large language models as judges", por Emma Croxford y colegas. Publicado en Nature, en Noviembre 7 de 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos a este análisis profundo. Estamos aquí para abordar problemas de información que son realmente abrumadores para que tú no tengas que hacerlo, y si hay una industria ahogada en datos, tiene que ser la sanidad, ¿verdad?
Beto
Absolutamente, está por todas partes.
Alicia
Piensa en cuando un paciente ingresa en el hospital: hay registros electrónicos de salud, los EHRs ("Electronic Health Records"), que pueden hincharse hasta proporciones épicas.
Beto
Verdaderamente épicas.
Alicia
La investigación que vemos hoy dice que uno de cada cinco registros de pacientes tiene una longitud comparable a Moby Dick.
Beto
Sí, Moby Dick — eso son más de 200.000 palabras. Una historia clínica realmente compleja y, a menudo, desorganizada.
Alicia
Y los médicos y enfermeras se supone que de alguna manera deben sintetizar todo eso bajo una enorme presión de tiempo.
Beto
Exacto, y no se trata solo de eficiencia: es, fundamentalmente, sobre la seguridad del paciente. El simple volumen aumenta dramáticamente el riesgo de que se pase por alto una información verdaderamente crucial.
Alicia
... lo que puede llevar a decisiones erróneas, quizás incluso peligrosas.
Beto
Precisamente subóptimas o peor.
Alicia
Así que es como un tsunami de información y necesita una solución moderna.
Y la promesa, por supuesto, es lo que todo el mundo comenta: la IA generativa, los grandes modelos de lenguaje (LLMs). Se están desarrollando para resumir esos enormes registros.
Beto
... con el objetivo claro de reducir la carga cognitiva de los clínicos, facilitarles la vida y hacer la atención más segura.
Alicia
Ese potencial suena transformador.
Beto
Realmente lo es, pero aquí está el meollo del problema que vamos a analizar hoy: ¿cómo sabes realmente si ese resumen generado por IA es seguro, es exacto, es siquiera útil?
Alicia
Porque si el resumen inventa algo: alucina una alergia crítica, por ejemplo, ...
Beto
... o deja fuera algo vital como un evento cardíaco reciente ...
Alicia
... entonces la IA no está ayudando en absoluto; en realidad podría causar daño.
Beto
Ese es el escenario de pesadilla: daño activo.
Alicia
De acuerdo, entonces nuestra misión para esta inmersión profunda es hurgar en este material: ¿podemos, de forma fiable y quizás tan importante eficientemente, usar un LLM para juzgar el trabajo de otra IA?
Beto
Sí, ¿podemos construir un LLM efectivo como juez? Esa es la pregunta.
Alicia
Y para quienes nos escuchan, ¿por qué importa esto?
Beto
La importancia aquí es la escala. Si podemos probar que este enfoque funciona, nos da una vía rápida, fiable y coste-efectiva para superar el gran cuello de botella: la revisión humana, que es lenta y cara. Esas métricas automatizadas antiguas simplemente no son suficientes.
Alicia
Así que esto podría desbloquear el uso seguro y escalable de la IA generativa en áreas de alto riesgo como la medicina.
Beto
Ese es el objetivo.
Alicia
Desempaquemos un poco más el desafío: síntesis de datos clínicos — sabemos que los registros son enormes, de hecho gigantescos. Pero ¿cuáles son las vulnerabilidades específicas? ¿Por qué es tan arriesgado que los LLM resuman este tipo de datos?
Beto
Como dijiste, estos resúmenes requieren una precisión increíble, casi perfecta idealmente, y ahí es donde los LLM pueden tropezar. En general vemos tres modos clave de fallo cuando afrontan EHRs.
Alicia
¿Cuáles son?
Beto
Primero, alucinaciones: la IA simplemente inventa hechos que no estaban en el registro original;
Alicia
Escalofriante. Número dos.
Beto
Omisiones: dejar fuera detalles críticos, quizá un cambio de medicación o resultados de pruebas recientes;
Alicia
También muy malo. Y el tercero que mencionaste es especialmente relevante porque tratamos historiales clínicos largos y desordenados:
Beto
El efecto “perdido en el medio”. Básicamente, el rendimiento del modelo se degrada cuando el texto de entrada se vuelve muy, muy largo — piénsalo como intentar recordar una novela de 200.000 palabras pero solo recordar claramente el primer capítulo y el último.
Alicia
Todo lo importante del medio ...
Beto
Cambios en la dieta del paciente, progresión de síntomas, resultados de pruebas específicas — se pierde o se diluye simplemente porque la entrada fue tan larga.
Alicia
El estudio apunta que la longitud mediana de esas notas clínicas combinadas era de más de 5.000 tokens, así que los modelos definitivamente están operando en esa zona de peligro.
Beto
Absolutamente, están en el meollo, lo que significa que cualquier herramienta de evaluación tiene que ser sensible a esos modos de fallo específicos: alucinaciones, omisiones y ese problema de “perdido en el medio”.
Alicia
Y esto nos lleva de forma natural a la evaluación en sí: ¿cómo comprobamos a los comprobadores? El estándar de oro es obviamente la revisión clínica humana: un médico lee el resumen y las notas fuente.
Beto
Sí, eso es lo ideal.
Alicia
Pero la investigación encontró que tardaba en promedio unos 10 minutos — 600 segundos — en revisar un solo resumen.
Beto
No es factible a escala: supone una enorme presión de recursos y anula por completo el juego de eficiencia que esperas de la IA en primer lugar.
Alicia
Entonces, sí, podríamos hacer que humanos revisen cada uno, pero tampoco podemos volver a las métricas automatizadas antiguas, ¿verdad? Cosa como ROUGE, BERTScore.
Beto
Exacto: este es un punto crucial. Esas herramientas fueron diseñadas para tareas de lenguaje mucho más simples — por ejemplo comparar titulares de noticias para ver si usan palabras similares — no para razonamiento clínico complejo. Operan a un nivel superficial, como la superposición de palabras.
Alicia
Pueden marcar si la frase “ataque” aparece tanto en la fuente como en el resumen, pero pasan por alto cuándo ocurrió, cómo se trató o si el resumen siquiera tiene sentido lógico conectando síntomas con diagnóstico.
Beto
Precisamente: no captan la veracidad contextual, la coherencia lógica ni, crucialmente, la relevancia clínica — son heurísticos y por eso no correlacionan bien con lo que un médico humano considera un buen resumen seguro.
Alicia
Los investigadores necesitaban algo mejor: una regla más precisa.
Beto
Empezaron con una herramienta validada llamada "Provider Documentation Summarization Quality Instrument" — un nombre largo — y la llaman PDSQI-9.
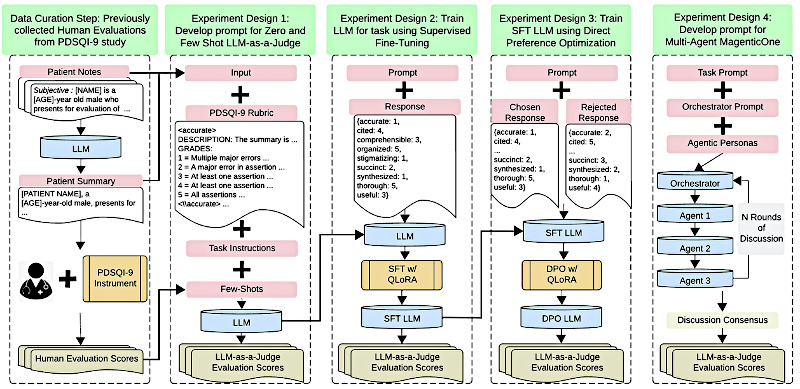
Alicia
Es una rúbrica con cosas concretas a buscar: nueve atributos.
Beto
Exactamente. Nueve atributos. Esto fue la base tanto para las evaluaciones de los expertos humanos como para entrenar al LLM como juez.
Alicia
¿Puedes enumerar esos nueve atributos?
Beto
Sí:
- citado (hace referencia a la fuente),
- exacto (factualmente correcto),
- completo (¿faltó algo?),
- útil (clínicamente útil),
- organizado (flujo lógico),
- comprensible (fácil de entender),
- sucinto (¿es lo bastante breve?),
- sintetizado (¿está conectado con sentido?) y
- estigmatizante (¿usa lenguaje sesgado?).
Alicia
Es muy completo.
Beto
Lo es, y la parte realmente ingeniosa de por qué funciona tan bien es que este instrumento fue diseñado específicamente teniendo en cuenta esos modos de fallo de los LLM.
Alicia
Así que está construido para atrapar las formas específicas en que los LLM suelen equivocarse.
Beto
Correcto. Pusieron mucho énfasis en el atributo “exacto” para controlar alucinaciones y en el atributo “completo” para controlar omisiones: es una prueba afinada para este propósito.
Alicia
Ahora vayamos a los resultados: aquí es donde se pone emocionante. La estrella — el LLM como juez que destacó — fue un modelo llamado gpt-o3-mini, y usaron algo llamado "five-shot prompting".
Beto
Sí. Solo para aclarar para todos: cuando decimos gpt-o3-mini aquí no nos referimos a la versión cotidiana del chatbot; es una variante específica, optimizada para tareas de razonamiento, con alta precisión y baja latencia.
Alicia
OK. Y "Five-shot prompting"?
Beto
Significa que le dieron a la IA cinco ejemplos detallados de cómo aplicar correctamente la rúbrica PDSQI-9 antes de pedirle que evaluara un nuevo resumen — mostrarle ejemplos de trabajo bien hecho.
Alicia
Entonces, ¿qué tan bien lo hizo ese gpt-o3-mini comparado con los expertos humanos?
Beto
Mostró una alineación realmente fuerte. La cifra clave aquí es el coeficiente de correlación intraclase, ICC, que mide qué tan consistentemente distintos evaluadores puntúan lo mismo — más alto es mejor, significa más acuerdo. Piensa en ello como comparar jueces puntuando una competición: un ICC por encima de 0,8 básicamente significa que el juez IA está puntuando con un rigor y consistencia similares a los jueces médicos humanos.
Alicia
¿Cuál fue el ICC de referencia de los expertos humanos?
Beto
Lograron un excelente ICC entre sí de 0,867 — muy consistente — y gpt-o3-mini, el LLM como juez, obtuvo 0,818.
Alicia
Vaya, eso está realmente cerca del punto de referencia humano; notablemente cercano. Pero es válido preguntarse: en medicina, “realmente cercano” ¿es suficientemente cercano? Ese pequeño hueco — 0,867 frente a 0,818 — ¿podría ocultar problemas de seguridad?
Beto
Esa es la pregunta correcta que siempre se debe hacer. El hallazgo clave, no obstante, es que la consistencia de puntuación del juez IA fue lo bastante alta como para considerarse fiable para este propósito de evaluación. Significa que puede sustituir o al menos aumentar al revisor humano sin romper fundamentalmente la validez del instrumento PDSQI-9. La fiabilidad es suficientemente eficiente para permitir escalado ...
Alicia
... y control de calidad — esas cifras son, francamente, alucinantes.
Hablemos de eficiencia.
Beto
Sí, aquí está la gran ventaja.
Alicia
Los humanos tardaban en promedio 600 segundos (10 minutos) por evaluación de resumen; el LLM como juez, gpt-o3-mini, ...
Beto
... tardó en promedio solo 22 segundos para hacer el mismo detallado scoring según PDSQI-9.
Alicia
Veintidós segundos: eso supone una reducción del 96 % en tiempo de trabajo. Es enorme.
Beto
Y en coste, cuando lo ajustan por el uso de servicios en la nube compatibles con IPA (según el texto original), el coste promedio para una de estas evaluaciones altamente fiables fue de cinco centavos.
Alicia
Cinco centavos. ¿Qué significa eso para un gran sistema hospitalario que genera miles o quizá millones de resúmenes?
Beto
Cambia completamente la economía: pasas de potencialmente millones en costes de revisión humana a quizá decenas de miles anuales con un sistema automatizado. Es un cambio operacional gigantesco.
Alicia
Hace que el aseguramiento de la calidad sea realmente factible a escala.
Beto
Exacto: proporciona una forma escalable y económicamente viable de comprobar estos resúmenes por seguridad y exactitud antes de que lleguen a un médico ocupado.
Alicia
Entonces, el “qué” es impresionante: alta fiabilidad, super rápido, super barato. Ahora el “por qué”: ¿por qué ese modelo específico — gpt-o3-mini, el optimizado para razonamiento — lo hizo mucho mejor que otros modelos potentes?
Beto
El “por qué” es fascinante: parece deberse a la arquitectura del modelo orientada al razonamiento.
Alicia
¿Qué define a esos modelos de razonamiento?
Beto
Son modelos diseñados explícitamente para realizar un proceso interno paso a paso antes de dar la respuesta final — a menudo llamado "chain-of-thought reasoning" (CoT), razonamiento en cadena de pensamiento. Simular esos pasos intermedios parece crucial para tareas complejas de nivel experto como la medicina.
Alicia
Así que no es necesariamente solo potencia bruta como podría tener un gpt-4o estándar; es el proceso: un debate interno más deliberado.
Beto
Los modelos no orientados al razonamiento, incluso si son potentes, tienden a saltar más directamente a una conclusión y no “muestran su trabajo”, por así decirlo.
Alicia
Se vio claramente esta diferencia en cómo puntuaron ciertos ítems de PDSQI-9.
Beto
La diferencia fue más marcada en atributos que requieren integrar cosas, entender contexto y hacer juicios complejos.
Alicia
Puntuar lo “sucinto” fue relativamente fácil para la mayoría de modelos.
Beto
Relativamente, sí. Pero la divergencia real apareció en atributos como “citado”, “organizado” y, especialmente, “sintetizado”.
Alicia
“Sintetizado” trata de si el resumen conecta las piezas, no solo lista hechos — ¿crea una imagen clínica integrada?
Beto
Hay un gran ejemplo en el artículo que lo ilustra. En un caso, un modelo no orientado al razonamiento (gpt-4o) miró un resumen y le dio la máxima puntuación en síntesis (5/5); su razonamiento fue superficial: “el resumen parece bien agrupado, coherente, buen trabajo”.
Alicia
¿Y el modelo de razonamiento, gpt-o3-mini?
Beto
Dio al mismo resumen una puntuación mucho más baja en síntesis (2/5).
Alicia
¿Por qué tanta diferencia?
Beto
La diferencia grande fue que su razonamiento fue mucho más profundo: explicó por qué puntuó más bajo, señalando que el resumen “no generó una comprensión integrada ni priorización del problema agudo dirigida al proveedor objetivo”.
Alicia
No se limitó a decir “se ve bien”: estaba analizando si ofrecía conocimiento clínico.
Beto
Exactamente: estaba haciendo ese tipo de pensamiento crítico deliberativo que imita cómo un experto humano evaluaría, mucho más matizado.
Alicia
Algo más que sorprendió en los hallazgos fue sobre los sistemas multiagente — la idea de que si tienes varias IAs debatiendo y respondiendo (el enfoque tipo “magistrado”), esperarías que el consenso fuera mejor.
Beto
Es la intuición común: más cabezas mejor que una.
Alicia
Sin embargo, aquí los resultados mostraron lo contrario. El mejor ICC de un sistema multiagente fue 0,768, aún bueno pero inferior al juez individual gpt-o3-mini con 0,818.
Beto
Sugiere que el LLM único, correctamente instruido y orientado al razonamiento, fue de hecho un evaluador más discernidor que el grupo de IAs tratando de ponerse de acuerdo.
Alicia
A veces el consenso de grupo tiende a suavizar detalles críticos. ¿Dónde falló la dinámica de grupo?
Beto
Hubo un ejemplo particular en el que, para el atributo “organizado”, el sistema multiagente convergía en una puntuación perfecta de 5 — todos estaban de acuerdo en que estaba organizado — pero el resumen podía contener una afirmación colocada fuera de orden cronológico, rompiendo el flujo lógico.
El juez individual gpt-o3-mini detectó esa ruptura de coherencia y asignó una puntuación más realista, quizá un 3, mientras que el multiagente en su consenso pasó por alto esa sutileza crítica.
Alicia
Interesante. No obstante, el enfoque multiagente tuvo un beneficio curioso: asignar diferentes personas.
Beto
Al asignar diferentes “personas” a los agentes (uno programado para puntuar alto sistemáticamente, otro bajo, otro medio), el patrón general de puntuaciones del sistema multiagente produjo una distribución más parecida a la variabilidad humana.
Alicia
Entonces, simuló el rango natural de opiniones que obtendrías de un panel de médicos humanos.
Beto
Correcto. No fue necesariamente más exacto en promedio, pero reflejó mejor la variabilidad inherente al juicio humano.
Alicia
Vamos a los grandes aprendizajes: si una organización — un hospital o una empresa de tecnología — quiere usar la idea del LLM como juez, ¿cuál es la lección más crucial de esta investigación?
Beto
Se reduce a una cosa: las instrucciones que le das a la IA — la rúbrica. La calidad, la fiabilidad y la utilidad del LLM como juez están completamente ligadas a lo clara y precisa que sea la herramienta de evaluación.
Alicia
PDSQI-9 funcionó bien porque fue muy detallada.
Beto
Precisamente. Los atributos estaban meticulosamente definidos, las escalas de 1 a 5 tenían descripciones concretas para cada nivel. Si tu rúbrica es vaga o ambigua, la evaluación del LLM será defectuosa o potencialmente inútil. Aun con IA sofisticada, sigue siendo “basura entra, basura sale”.
Alicia
Tiene sentido. En la práctica, gpt-o3-mini fue la estrella, pero es un modelo propietario, basado en la nube. ¿Qué pasa con sistemas sanitarios que quieren evitar la dependencia en un proveedor, o tienen reglas estrictas de seguridad de datos que impiden el uso de la nube?
Beto
Es una preocupación real en salud, y la investigación lo examinó: buenas noticias. Aunque GPT-o3-mini fue el mejor, varios modelos de código abierto también rindieron muy bien: modelos como DeepSeek-Distilled-Qwen-2.5-32B y Mixtral-8x22B.
Alicia
Modelos open source que se pueden descargar y ejecutar localmente.
Beto
Exacto. Modelos open source que se pueden descargar y ejecutar en servidores locales seguros — alcanzaron ICCs por encima de 0,7.
Alicia
Son alternativas viables si no puedes o no quieres usar modelos propietarios en la nube.
Beto
Sí, absolutamente. Muestra que el enfoque no depende de un único proveedor o modelo.
Alicia
Un último punto de validación: este marco de LLM como juez no se probó en una sola tarea. Lo aplicaron a otras cosas.
Beto
Lo aplicaron a otra tarea clínica de evaluación — resumir la lista de problemas del paciente como parte del Shared Task Problem 2023 — y funcionó bien allí también, alcanzando una fiabilidad alta con ICC alrededor de 0,710.
Alicia
Esa validación cruzada es importante: sugiere que el método en sí es robusto.
Beto
Importantísimo. y no es un truco de una sola instancia; parece transferible a distintos tipos de desafíos de resumen clínico.
Alicia
Muy bien. Para resumir las conclusiones centrales: parece que hemos encontrado una forma, usando LLMs orientados a razonamiento junto con rúbricas claras, de obtener una validación rápida, barata y altamente fiable de resúmenes médicos generados por IA, asegurando seguridad antes de que lleguen a los clínicos.
Beto
Es la esencia: un camino escalable hacia una IA más segura en medicina.
Alicia
Hemos usado el LLM como juez efectivamente para control de calidad, comprobando el producto final. Mirando hacia adelante, ¿cuál sería el siguiente paso lógico para un futuro aún más seguro y eficiente?
Beto
Aquí viene una posibilidad provocadora y emocionante: ¿y si el LLM como juez no solo comprobara el trabajo después del hecho sino que participara activamente en mejorarlo durante su creación?
Alicia
¿Cómo funcionaría eso?
Beto
La siguiente frontera probablemente integrará el proceso generador y el proceso evaluador del LLM en un único sistema de lazo cerrado.
Alicia
"Lazo cerrado", significa ...
Beto
Significa que el LLM juez proporciona retroalimentación detallada de inmediato al LLM generador; el generador revisa el resumen según esa retroalimentación; y esto ocurre de forma iterativa en tiempo real hasta que el juez LLM confirme que cumple automáticamente un umbral predefinido de calidad y seguridad.
Así pasas de comprobar errores a posteriori a control de calidad automatizado y proactivo en tiempo real, incorporando la calidad desde el principio. Ese es el siguiente gran salto.



{kind=link}