
Para aquellas personas que están empezando a aprender sobre Inteligencia Artificial (IA), hoy les traigo un resumen que menciona los grandes modelos de lenguaje (LLMs), cómo surgieron, historia, qué tecnologías hay detrás de ellos, cómo se usan, desafíos y futuras direcciones.
El artículo científico fue inicialmente publicado en Febrero del 2024, pero ha sido actualizado, pues este campo ha seguido avanzando muy rápidamente. Les incluyo el enlace, para aquellos interesados en profundizar en el tema: "Large Language Models: A Survey", por Shervin Minaee y colegas. Actualizado el 23 de Marzo de 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Bienvenido de nuevo a otro análisis profundo. Si sientes que últimamente te estás ahogando en siglas — GPT, LLaMA, PaLM, RAG, CoT — te prometo que no estás solo.
Alicia
Para nada.
Beto
El mundo de los grandes modelos de lenguaje, LLMs, se mueve a una velocidad imposible.
Alicia
Es un ritmo vertiginoso, y el campo se está acelerando más rápido que casi cualquier otro sector en la historia de la tecnología.
Así que nuestra misión hoy es bastante sencilla. Queremos cortar todo ese ruido. Te vamos a dar una única hoja de ruta estructurada para entender de verdad los modelos centrales, comparar las grandes familias y mirar críticamente los trucos que la gente usa para convertir estas cosas en herramientas útiles.
Beto
Exacto. Este análisis profundo trata de convertir esa confusión en conocimiento con confianza. Vamos a trazar la historia, mirar bajo el capó y averiguar qué los hace tan potentes. Y también, qué causa sus problemas más molestos, como las alucinaciones.
Empecemos por el principio, los fundamentos. Cuando hablamos de modelado de lenguaje, esto no es un concepto nuevo desde 2022. En realidad volvemos décadas atrás.
Alicia
Así es — 70 años, de verdad. La idea de predecir la siguiente palabra en una secuencia empezó con pensadores como Claude Shannon en los años 50.
Beto
¿Los 1950s? ¡Vaya!
Alicia
Él aplicaba la teoría de la información al texto. Pero si trazas el viaje desde ahí hasta hoy, realmente puedes ver cuatro grandes olas de investigación.
Beto
Vale, cuéntanos esas olas. ¿Cuál fue el enfoque inicial?
Alicia
La primera ola fue lo que llamamos modelos estadísticos de lenguaje ("Statistical Language Models", SLMs). Fueron los n-gramas originales. Funcionaban puramente con frecuencia y probabilidad. Así que un modelo trigram preguntaría, basado en las dos palabras anteriores, ¿cuál es la probabilidad de que la siguiente palabra sea "casa"?
Beto
¿Y cuál era el gran defecto? Suena tan frágil.
Alicia
Lo era. Increíblemente limitado por la llamada "escasez de datos". Si tu modelo nunca había visto la frase "elefante morado con lunares", no podía predecirla.
Beto
No tenía concepto de relación entre palabras.
Alicia
Ninguno. Ni siquiera entendía que "violeta" y "púrpura" podrían estar relacionados. Cada palabra era una cosa totalmente aislada.
Beto
Entonces, si no puede manejar sinónimos, ¿cómo se arregla eso?
Alicia
Eso nos lleva a la segunda ola: "modelos de lenguaje neuronales" ("Neural Language Models", NLMs). Aquí fue donde los "embeddings" de palabras lo cambiaron todo.
Beto
"Embeddings" de palabras.
Alicia
Sí. En vez de que las palabras sean símbolos, se mapeaban a vectores, como coordenadas en un espacio enorme. Si el vector de "perro" estaba cerca del vector de "canino", el modelo sabía que eran similares.
Beto
Por primera vez tenemos entendimiento semántico real.
Alicia
Sí, pero esos primeros modelos neuronales todavía eran bastante específicos para tareas. Los entrenabas para un trabajo concreto.
Beto
Lo que lleva a la tercera ola.
Alicia
Exacto. La tercera ola fueron los modelos de lenguaje preentrenados ("Pre-Trained Language Models", PLMs). El gran cambio aquí fue: ¿por qué entrenar un modelo para una sola tarea? Preentrenemos un modelo masivo en enormes cantidades de texto con un propósito general y luego ajústalo (fine-tune) de forma económica para cualquier tarea específica.
Beto
Así, el entrenamiento se volvió independiente de la tarea y mucho más eficiente.
Alicia
Muchísimo más eficiente. Y eso nos lleva a la cuarta ola en la que estamos hoy: los grandes modelos de lenguaje ("Large Language Models", LLMs).
Beto
Y la característica definitoria es simplemente la escala increíble.
Alicia
Correcto. Decenas a cientos de miles de millones de parámetros. Pero esa escala habría sido totalmente imposible sin una invención clave.
Beto
¿Te refieres a la arquitectura transformer?
Alicia
Exacto. Introducida en 2017, es el motor detrás de todos los LLM modernos. Reemplazó por completo la vieja forma secuencial de procesar con algo llamado "self-attention" (auto-atención).
Beto
Oímos "autoatención" todo el tiempo. ¿Puedes concretarlo un poco más para nosotros? ¿Por qué eliminar el procesamiento secuencial fue un cambio de juego?
Alicia
Vale. Piénsalo de este modo: los modelos antiguos procesaban la información como si leyeras un libro en voz alta, una palabra a la vez. Para entender la palabra "él" tenía que recordar lentamente cada palabra que vino antes.
Beto
Muy lento.
Alicia
Súper lento. No podías empezar en la página 100 hasta que hubieras terminado la 99. El transformer con autoatención es como poder leer todo el documento al mismo tiempo.
Beto
¿Así que ve todo el contexto a la vez?
Alicia
Al instante. Calcula la relación entre cada palabra y todas las otras palabras en la entrada inmediatamente.
Beto
Esta enorme paralelización es lo que nos permite usar las GPUs tan eficientemente. Y esa computación en paralelo es la única razón por la que pudimos escalar hasta entrenar en, básicamente, Internet entero.
Alicia
Eso es todo. La inteligencia viene de la escala y la escala viene del transformer que lo hace económicamente factible. Y así obtuvimos estos solucionadores generales de tareas como ChatGPT o el Co-pilot de Microsoft.
Beto
Bien. Ahora que tenemos el habilitador técnico — el transformer — entremos en los grandes jugadores. Tenemos tres familias dominantes: GPT, LLaMA y PaLM. Y cada una parece tener una filosofía bastante diferente.
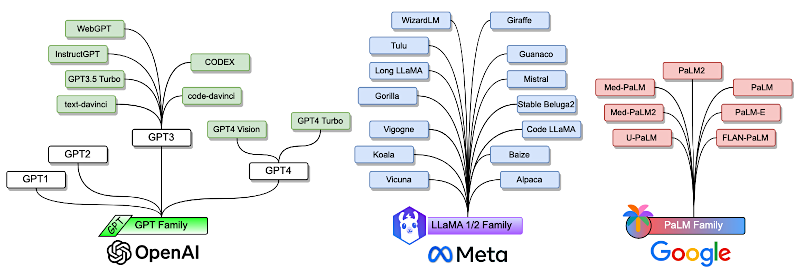
Alicia
Así es. Empecemos con la que desató la histeria actual: la familia GPT de OpenAI.
Estos modelos usan, digamos, una arquitectura solo-decoder. Son autorregresivos.
Beto
Significa que están construidos para predecir la siguiente palabra o token.
Alicia
Exacto. Continúan la historia. El salto de GPT-2 a GPT-3 fue masivo. GPT-3 con 175.000 millones de parámetros fue realmente el primer LLM en mostrar lo que ahora llamamos "habilidades emergentes". Hablaremos de eso luego.
Beto
Pero el verdadero cambio para los consumidores fue InstructGPT y ChatGPT.
Alicia
Así fue. Y ahí es donde entra RLHF ("Reinforcement Learning from Human Feedback").
Beto
Aprendizaje por refuerzo con retroalimentación humana.
Alicia
Sí. RLHF fue revolucionario. Ya no se trataba solo de predecir la siguiente palabra a partir de Internet. Era un método de ajuste para alinear el modelo con la intención humana. Enseñó al modelo a seguir instrucciones, a ser útil, a evitar salidas tóxicas.
Beto
Convirtió a un predictor en un asistente.
Alicia
Es una forma perfecta de decirlo.
Y luego, por supuesto, tienes GPT-4, el pico actual.
Beto
Que es otra bestia completamente distinta.
Alicia
Se estima que tiene alrededor de 1.76 billones de parámetros. Es increíblemente inteligente. Ha quedado en el 10% superior en un examen de barra simulado. Y es multimodal.
Beto
Puede ver.
Alicia
Puede ver. Toma texto e imágenes. Y la filosofía aquí es clara: código cerrado, alto rendimiento, y acceso vía API.
Beto
Perfecto.
Ahora compáralo con la familia LLaMA de Meta. Tomaron un camino completamente diferente: código abierto.
Alicia
La filosofía de LLaMA desafió la idea de que más grande siempre es mejor. Su primer modelo LLaMA-13B causó conmoción en la comunidad.
Beto
¿Por qué?
Alicia
Porque mostraba que, en muchos "benchmarks" (exámenes comparativos), superaba al mucho más grande GPT-3. Su apuesta fue eficiencia sobre la fuerza bruta del tamaño.
Beto
Meta diciendo que "podemos obtener mejores resultados con un modelo más pequeño si lo entrenamos más inteligentemente".
Alicia
Precisamente. Y al liberar los pesos del modelo, desataron una ola de innovación comunitaria. Surgieron modelos como Alpaca y Vicuna 13B.
Beto
Y Vicuna fue un gran hito.
Alicia
Un gran hito. Logró más del 90% de la calidad de ChatGPT. Pero el costo de entrenamiento fue de apenas unos 300 dólares.
Beto
300 dólares. Es una locura.
Alicia
Fue una democratización total. Y seguimos viendo eso: modelos más pequeños y súper eficientes como Mistral 7B superando a modelos más grandes usando trucos arquitectónicos inteligentes. Demuestra que un diseño inteligente puede vencer al tamaño bruto.
Beto
¿Y dónde encaja la familia PaLM de Google?
Alicia
La jugada inicial de Google fue la escala masiva. PaLM apareció con 540.000 millones de parámetros. Pero su enfoque ha cambiado hacia el rendimiento especializado por dominio.
Beto
Como con PaLM 2.
Alicia
Exacto. PaLM 2 se centró en razonamiento y habilidades multilingües. Pero el mejor ejemplo es MedPaLM 2: un modelo afinado específicamente para el dominio médico.
Beto
¿Y cómo rindió esa especialización?
Alicia
Dramáticamente. Obtuvo hasta 86.5% en el dataset MedQA. Básicamente alcanzó un nivel de conocimiento clínico de experto. Muestra el poder de tomar un modelo general y convertirlo en un especialista verdadero.
Beto
Entonces, para resumir: tienes al pionero de código cerrado persiguiendo la supremacía multimodal con GPT.
Alicia
Al disruptor de código abierto que defiende la eficiencia con LLaMA.
Beto
Y al especialista de escala masiva que apunta al especialidad por dominio con PaLM. Es una carrera realmente dinámica.
Alicia
Pasemos ahora a la experiencia real de usar estos modelos. ¿Qué hace que hablar con un LLM se sienta tan diferente? La gente habla de habilidades emergentes. ¿Qué son exactamente?
Beto
Bien. El hallazgo clave es que estas habilidades no fueron programadas. Emergen de forma no lineal una vez que un modelo supera cierto umbral de tamaño.
Alicia
Así que no obtienes solo un 10% más de rendimiento si duplicas el tamaño; de repente obtienes una habilidad completamente nueva.
Beto
Una habilidad completamente nueva. Y hay tres habilidades emergentes clave.
La primera es el "aprendizaje en contexto", o ICL (In-Context Learning").
Alicia
Significa que el modelo puede aprender una tarea nueva solo a partir de unos pocos ejemplos que pones directamente en el prompt, lo que llamamos "few-shot prompting". No hace falta re-entrenar el modelo.
Beto
Increíble. Es como mostrar a un niño los primeros dos movimientos de un juego y que de repente entienda la regla.
Alicia
Es una analogía perfecta.
La segunda es seguir instrucciones.
Debido a ese ajuste de alineamiento del que hablamos, estos modelos ahora pueden entender y seguir instrucciones realmente complejas para tareas que nunca antes habían visto.
Beto
Eso es la base de lo que hace que ChatGPT se sienta como un asistente real.
Alicia
Y la tercera, la que los hace parecer verdaderamente inteligentes, es el razonamiento.
Beto
Razonamiento multi‑paso.
Alicia
Sí, a menudo impulsado por una técnica llamada "Chain of Thought" ("cadena de pensamiento"), o "CoT". Es la capacidad del modelo para tomar un problema complejo, como un rompecabezas matemático, y descomponerlo en pasos intermedios, igual que haría una persona.
Beto
Aquí viene la paradoja: si estos modelos pueden razonar y aprender en contexto, ¿por qué inventan cosas? ¿Por qué esta máquina lógica casi sobrehumana a veces inventa tonterías que suenan plausibles?
Alicia
Esa es la limitación crítica: las alucinaciones. Es importante definirlas como la generación de contenido que es no sensato o que no es fiel al material fuente. Incluso tenemos categorías para eso.
Beto
Dinos las categorías.
Alicia
- Tienes alucinaciones "intrínsecas", donde el modelo dice algo que contradice directamente el material fuente — comete un error factual claro.
- Luego tienes alucinaciones "extrínsecas". Son afirmaciones que no se pueden verificar a partir de la fuente. Detalles que suenan plausibles que el modelo simplemente inventó porque pensó que encajaban en la historia.
Beto
Si le pido que resuma un documento y se inventa una fecha que no estaba, eso es extrínseco. Si tiene la fecha en el documento y la pone mal, eso es intrínseco.
Alicia
Es una gran forma de pensarlo.
Pero la razón fundamental de por qué ocurre esto es crucial. Alucinan porque en su núcleo son modelos probabilísticos.
Beto
Solo están prediciendo el siguiente token.
Alicia
Ese es su único objetivo. Generan el texto que estadísticamente es más probable que siga, no el texto que se ajusta a una noción abstracta de verdad. Su objetivo es la coherencia, no la correspondencia con la realidad. Son narradores brillantes, no bibliotecarios fiables.
Beto
Dado que el modelo base es un narrador brillante pero a veces poco fiable, la frontera ya no es solo hacer los modelos más grandes. Se trata de diseñar el entorno alrededor del modelo.
Alicia
Absolutamente. El primer nivel es cómo hablamos con él mediante prompt engineering avanzado. Esto es cómo desbloqueas esas habilidades de razonamiento. Y el método más básico que todos deberían usar es "chain of thought" (CoT).
Beto
Pedirle que piense paso a paso.
Alicia
Solo decirle que piense paso a paso o que muestre su trabajo.
Y la investigación muestra que proporcionar unos pocos ejemplos de buen razonamiento paso a paso — lo que llaman "CoT manual" — es mucho más efectivo.
Beto
Le da una plantilla a seguir.
Alicia
Exacto. Luego te vuelves más sofisticado. Hay una técnica llamada "reflexión". Con ella realmente pides al LLM que critique y revise su propia salida según ciertos criterios. Lo conviertes en su propio editor.
Beto
Es un truco fascinante.
¿Qué hay de conseguir que suene más autoritario?
Alicia
Eso es "prompting de experto". Indicas al modelo que simule un rol: "actúa como un destacado jurista constitucional" o "genera esto como un analista financiero senior". El modelo entonces adopta el tono, la terminología y el dominio de conocimiento de esa persona.
Beto
Esos prompts mejoran el razonamiento. Pero para resolver el gran problema, las alucinaciones y el conocimiento desactualizado, tenemos que mirar fuera del modelo. Ahí entra la recuperación aumentada a la generación, "Retrieval Augmented Generation", RAG.
Alicia
RAG quizá sea la técnica de aumento más importante que existe en el mundo real hoy. Ataca directamente el corte de conocimiento y el problema de fiabilidad.
Beto
¿Cómo lo hace?
Alicia
Piensa en el LLM como un estudiante brillante que solo estudió un libro de texto de hace dos años. RAG es el sistema que le da a ese estudiante acceso instantáneo a una biblioteca actualizada antes de responder tu pregunta.
Beto
¿Cómo funciona técnicamente?
Alicia
Envías una consulta. El sistema RAG usa esa consulta para buscar en una base de conocimiento externa y actualizada — una biblioteca, una base de datos, un motor de búsqueda —. Extrae los fragmentos más relevantes y verificables.
Beto
¿Y luego ocurre la magia?
Alicia
Sí. Esa información recuperada se inyecta de vuelta en tu prompt original. Se convierte en parte del contexto. El LLM responde usando ese texto externo y verificable para informar su respuesta.
Beto
Eso ancla la respuesta en la realidad y reduce las alucinaciones.
Alicia
Drásticamente. La ata al modelo a una fuente de verdad.
Beto
Todo esto conduce a la idea más compleja y, creo, más emocionante: los agentes LLM. (ver también)
Alicia
Correcto. Un agente es un concepto mucho más grande. Es un sistema autónomo construido sobre un LLM. Tiene un ciclo continuo: percibe su entorno, puede sensar cosas, juzga, decide y luego actúa.
Beto
RAG es solo una de las herramientas que un agente podría usar.
Alicia
Un agente podría tener un intérprete de código, una API meteorológica, cualquier cosa.
La técnica clave que le permite decidir qué herramienta usar se llama "ReAct".
Beto
ReAct: "Reason and Act" (razonar y actuar).
Alicia
Es una estructura de prompt que forza al LLM a entrelazar su razonamiento interno — su "chain of thought" (CoT), cadena de pensamiento — con pasos accionables externos. Puede razonar: "para responder esto necesito el precio de la acción de hoy", luego ejecuta la acción para llamar a una API, obtiene el resultado y razona sobre qué hacer después.
Beto
Convierte al LLM de una máquina pasiva de respuestas en un solucionador de problemas activo.
Alicia
Si te llevas una sola cosa de este análisis profundo, que sea esto: los LLMs de hoy están definidos por tres pilares:
- La arquitectura transformer,
- la escala masiva que nos dio habilidades emergentes, y,
- el ajuste especializado como RLHF que los hizo útiles.
Pero el futuro trata de resolver sus limitaciones mediante aumentos externos:
- haciéndolos fácticos con RAG, y,
- proactivos con agentes.
Beto
Esa es una síntesis perfecta.
Y para dejarte con un pensamiento final: mira más allá del simple conteo de parámetros. Eso impulsó la primera revolución, pero las próximas grandes fugas (avances) tienen que ver con la eficiencia arquitectónica y la modalidad.
Alicia
Debes vigilar lo que llaman "arquitecturas post-attention", cosas como los "modelos de espacio de estados" ("State Space Models") o SSMs, como Mamba. Prometen ser mucho más eficientes para manejar ventanas de contexto súper largas que las tareas complejas necesitan.
Beto
Y quizá aún más importante, mira las arquitecturas de "mezcla de expertos" ("Mixture of Experts"), MoE. Lo que se rumora que existe dentro de GPT-4.
Alicia
En vez de que todo el modelo gigante se dispare por cada token, MoE permite que el modelo use solo un subconjunto pequeño de parámetros expertos para una tarea dada, ...
Beto
... lo que reduce drásticamente el coste de ejecución.
Alicia
Es una señal crítica para el futuro. Los LLMs seguirán haciéndose más inteligentes, pero el foco está cambiando. Se mueve del tamaño bruto a hacerlos más rápidos, más baratos y mucho más accesibles. El modelo más grande quizá no sea el más importante mañana.
Beto
Seguiremos siguiendo esos avances por ti aquí mismo. Gracias por acompañarnos en esta inmersión profunda. Nos vemos la próxima vez



{kind=link}