
Esta encuesta explora el floreciente campo de la inteligencia de código multimodal, donde los modelos traducen entradas visuales como capturas de pantalla, gráficos y diagramas en código ejecutable. Mientras que los sistemas tradicionales se basan en texto, estos marcos avanzados utilizan la percepción visual como requisito central para automatizar tareas en el desarrollo frontend, la visualización de datos y el diseño asistido por computadora. La investigación clasifica el panorama en cuatro dominios clave: interfaces gráficas de usuario, visualización científica, gráficos estructurados y tareas fronterizas como la robótica y la generación de videos. Al establecer una taxonomía formal, los autores distinguen entre las diversas funciones del código como artefacto renderizado, estructura editable o política ejecutable. Un hallazgo principal es que, si bien la similitud visual es una métrica común, el verdadero progreso requiere métodos centrados en la verificación que prueben la interacción funcional y la corrección semántica. En última instancia, las fuentes abogan por un cambio hacia sistemas basados en evidencia que puedan validar el código de manera confiable a través de la ejecución de múltiples señales y múltiples estados.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence", por Xuanle Zhao y colegas. Publicado el 16 de Junio de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Imaginen tomar una foto de una encimera desordenada, y entregar esa foto a una IA, para que instantáneamente escriba el código, para operar un brazo robótico, que simplemente limpie la superficie.
Alicia
Correcto, sin ningún tipo de entrada de texto.
Beto
Exacto. Sin manuales, sin teclear, solo ver un espacio físico y hacer algo al respecto. Eso no es ciencia ficción, por cierto. Es la vanguardia de la programación en este momento.
Alicia
De verdad lo es.
Beto
Porque probablemente estén acostumbrados a tener una ventana abierta, hablar con un chatbot de IA y escribir una rápida indicación de texto para arreglar un error, o escribir un simple script de Python.
Alicia
Y eso ya se siente como magia para mucha gente.
Beto
Lo hace totalmente. Pero intenten pedirle a ese mismo modelo de texto espacial que construya un panel de control complejo de múltiples capas, o que intente recrear perfectamente un gráfico científico denso y fuertemente anotado, solo describiéndolo con palabras.
Alicia
Oh, se desmorona casi de inmediato.
Beto
Correcto. Escribir todos los requisitos espaciales, todas las reglas de diseño, las sombras. Es como intentar pintar una obra maestra usando solo una máquina de escribir.
Alicia
Sí, hemos pasado la última década tratando el texto como la interfaz definitiva para la IA. Pero el texto, si bien es fantástico para la lógica abstracta, es una banda de baja capacidad, dolorosamente baja para describir la realidad espacial visual.
Beto
Lo que nos lleva a nuestra pila de fuentes para esta inmersión profunda de hoy. Estamos viendo una masiva encuesta de investigación de 2026 titulada "Más allá del NL2Code, una encuesta estructurada sobre la inteligencia de código multimodal".
Alicia
Y la autoría de esto es increíble. Es una coalición global de investigadores de potentes instituciones, lugares como la Universidad de Tsinghua, Stanford, Apple y la Universidad de Hong Kong.
Beto
Un grupo realmente contundente. Y nuestra misión hoy es explorar cómo la IA está cerrando lo que llaman "una brecha de modalidad". Es decir, pasar de solo leer indicaciones de texto a modelos que pueden ver imágenes, gráficos, entornos.
Alicia
Y luego traducir esas entradas visuales directamente a código ejecutable.
Beto
Sí.
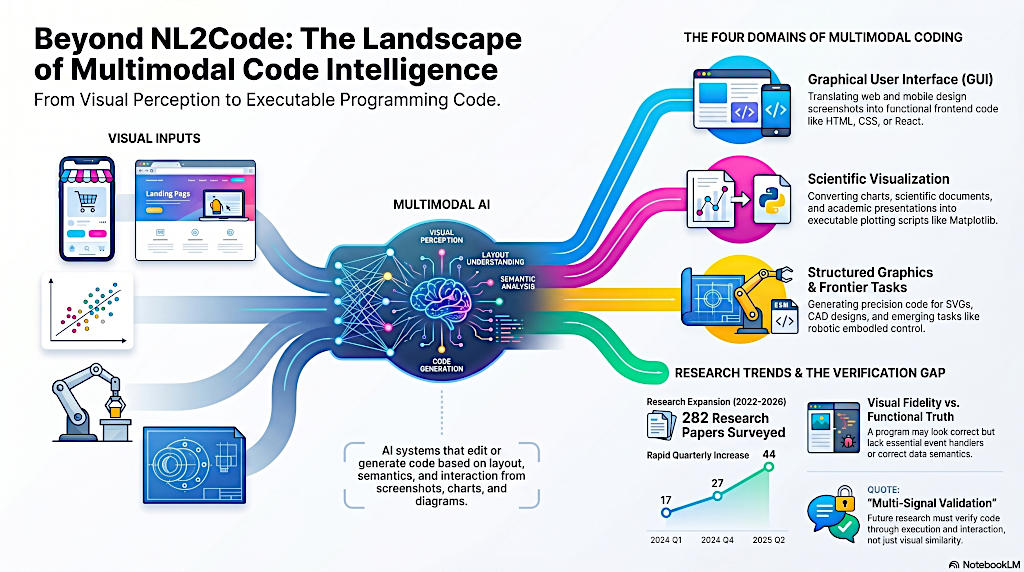
El Panorama de Inteligencia de Código Multimodal
Beto
Bien, desglosemos esto.
¿Por qué está el lenguaje tradicional a código, golpeando un muro en el mundo real?
Alicia
Bueno, para entender el muro, tenemos que mirar la arquitectura de cómo estos modelos más antiguos procesan la información. Durante años, el enfoque ha estado estrictamente en alinear la intención lingüística con la sintaxis formal.
Beto
Así que escribes algo como, "escriba una función para calcular la secuencia de Fibonacci".
Alicia
Exacto. Y el modelo mapea la secuencia de tus palabras, tus tokens de texto, a la lógica de un lenguaje de programación. Y eso funciona maravillosamente para el procesamiento de datos de "backend".
Beto
Correcto.
Alicia
Pero la programación moderna no se trata solo de lógica abstracta. Requiere jerarquías espaciales, reglas de diseño estrictas, geometría compleja, ...
Beto
... lo que tiene mucho sentido. Confiar únicamente en el texto para describir la disposición precisa de una aplicación móvil moderna, es como intentar explicar cómo construir una escalera de caracol por teléfono.
Alicia
Sí, por teléfono sin dejar que los carpinteros vean un plano.
Beto
Exacto. Puedes decir que "el peldaño sube y se curva a la derecha con una inclinación de 30 grados", pero sin ver la geometría, van a construir algo completamente deformado.
Alicia
La relación estructural inherente se pierde en la traducción. Y ese es el concepto formal que los investigadores definen como "la brecha de modalidad".
Beto
La brecha de modalidad.
Alicia
Correcto. El texto es fundamentalmente secuencial y lineal. Lo lees palabra por palabra.
Las señales visuales, por otro lado, son de alta capacidad y paralelas. Una sola imagen codifica información estructural densa, relaciones espaciales, restricciones estéticas, todo a la vez.
Beto
¿Así que obtienes toda la información en una sola mirada?
Alicia
Exacto. La brecha existe porque estás tratando de forzar una realidad 2D o 3D de alta capacidad a través de un cuello de botella textual unidimensional.
Beto
Vaya.
Alicia
Así que el cambio hacia los modelos de lenguaje grandes multimodales, o MLLMs, se trata de eliminar ese cuello de botella por completo. Tratan la percepción visual no como una característica adicional divertida, sino como un requisito previo central para sintetizar código.
Beto
Así que pónganse en el lugar de un desarrollador o diseñador, piensen en cómo cambia su flujo de trabajo. Imaginen estar en una cafetería con un boceto de una interfaz de aplicación en una servilleta.
Alicia
Justo como cajas y flechas dibujadas a mano.
Beto
Sí, solo un diseño de distribución de una barra de navegación. En lugar de escribir un documento de especificación de 10 páginas detallando cada margen, relleno y código hexadecimal a una IA, ¿qué pasaría si simplemente le mostraran la servilleta?
Alicia
Y el modelo realmente entendiera las relaciones espaciales lo suficiente como para generar toda la parte frontal y la estructura.
Beto
Es salvaje de pensar. Pero lograr que un modelo mire una servilleta y escriba código funcional que deba requerir metodologías de entrenamiento específicas, ¿cierto?
Alicia
Oh, absolutamente. No se trata solo de alimentar una imagen en una red neuronal y esperar lo mejor. Los investigadores mapean cómo los modelos están sintetizando este código multimodal en tres tareas distintas.
Beto
Bien, vamos a desglosarlas.
Alicia
La primera es lo que llaman "generación directa multimodal". Esta es la base. El modelo reconstruye un artefacto visual, esencialmente desde cero.
Beto
Así que le proporcionas un contexto visual como una captura de pantalla de una interfaz de usuario, junto con una indicación de texto.
Alicia
Correcto. Y el objetivo es que la IA sintetice toda la base de código que, cuando se ejecuta, produce exactamente ese artefacto visual.
Beto
Quiero hacer una pausa en el mecanismo allí porque suena simple. Pero por dentro, ¿cómo mira realmente una IA una cuadrícula plana de píxeles y la traduce en líneas anidadas de HTML y CSS?
Alicia
Implica tokenización visual. El modelo utiliza un codificador de visión para rebanar la imagen en una cuadrícula de pequeños parches.
Beto
Como si la estuviera cortando en un mosaico.
Alicia
Exacto. Analiza los patrones de píxeles en cada parche, los bordes, los colores, el texto, y mapea esas características visuales a un espacio matemático que el modelo de lenguaje pueda comprender. Luego el modelo hace referencia cruzada de esos tokens visuales con su vocabulario de lenguajes de programación. Así que ve un parche con un rectángulo azul que contiene texto blanco, reconoce la posición espacial, y traduce ese token visual en la sintaxis para un elemento de contenedor CSS.
Beto
Eso tiene perfecto sentido. Pero en el mundo real, nadie genera una aplicación perfecta a la primera.
Alicia
Muy cierto.
Beto
Normalmente, tienes una base, tienes una página web funcional, y solo necesitas ajustarla. Lo que nos lleva a la segunda tarea que los investigadores identifican, que es "la edición de código guiada por instrucciones".
Alicia
Sí. Y aquí es donde aprovechamos las capacidades de seguimiento de instrucciones de estos modelos. En lugar de empezar desde una pizarra en blanco, tienes un estado visual existente en su código subyacente, y quieres modificarlo.
Beto
Así que proporcionas al modelo una instrucción textual combinada con una indicación visual dirigida.
Alicia
Correcto. En este caso, podrías subir una imagen de tu aplicación actual, dibujar un cuadro delimitador rojo alrededor de un menú de navegación específico, y decir: "cambia el color de fondo del elemento en esta caja a gris pizarra e incrementa el relleno".
Beto
Y luego el modelo tiene que generar el código editado que renderice ese nuevo estado específico.
Alicia
Exacto.
Beto
Eso se siente increíblemente intuitivo. Es el equivalente digital de señalar una pantalla mientras estás sentado junto a un colega. No dices: "ve a la línea 452 del CSS y ajusta el contenedor flex". Simplemente señalas y dices: "haz que esa parte sea más ancha".
Alicia
Correcto. Pero la IA tiene que conectar esa caja roja con el código real.
Beto
Sí. ¿Cómo lo hace?
Alicia
Lo fascinante aquí es la pura complejidad de esa conexión. El modelo no solo está haciendo un simple reemplazo de texto. Está realizando lo que los investigadores llaman "anclaje espacial".
Beto
Anclaje espacial. OK.
Alicia
Tiene que mirar las coordenadas de tu cuadro delimitador, mapear esas coordenadas al elemento de interfaz de usuario específico renderizado en la pantalla, y luego encontrar las líneas exactas y el modelo de objeto de documento subyacente, el árbol DOM que dicta ese elemento.
Beto
Vaya.
Alicia
Y una vez que encuentra el código correcto, realiza síntesis de código contrafactual.
Beto
Espera. La "síntesis de código contrafactual" es un gran jerga. ¿Significa básicamente que la IA está imaginando un escenario de "qué pasaría si ..." para averiguar qué líneas de código deben cambiar?
Alicia
Esa es una gran manera de decirlo. El modelo tiene que proyectar un estado futuro hipotético. Algo así como, "si cambio esta variable de relleno de 10 píxeles a 20 píxeles, ¿qué pasará con el resto de la página?"
Beto
Correcto. Porque cambiar una cosa generalmente rompe otra.
Alicia
Exacto. Tiene que sintetizar la diferencia de código que muestre tu objetivo visual sin empujar accidentalmente un bloque de texto vecino fuera de la pantalla. Es una edición contextual quirúrgica.
Beto
Lo que cualquiera que haya intentado centrar un `div` en CSS, sabe que es una pesadilla total. Cambias un margen y de repente tus pies se superponen con tu encabezado.
Alicia
Muy cierto.
Beto
Así que tenemos generación directa desde cero, y edición guiada por instrucciones para ajustes. ¿Cuál es la tercera tarea?
Alicia
La tercera es "el refinamiento de código basado en referencias", que se centra mucho en la depuración automatizada.
Beto
Depuración basada en imágenes.
Alicia
Sí. En este escenario, le alimentas al modelo un código defectuoso, un borrador de código que compila pero produce el diseño visual incorrecto, junto con una imagen de cómo debería verse la salida final. Se forza a la IA a depurar su propia lógica comparando la salida rota de su código actual con la referencia visual perfecta. Utiliza la discrepancia visual como señal para arreglar el código estructural.
Beto
Así que esencialmente está jugando un juego de alto riesgo de encontrar la diferencia. Mira el código renderizado, mira la imagen objetivo, notas que una barra lateral está a la izquierda en lugar de a la derecha y luego vuelve al código para invertir la dirección flex.
Alicia
Precisamente. Y demuestra que la retroalimentación visual es una herramienta de depuración crítica, no solo para los humanos, sino para los modelos de IA que aprenden a codificar.
Beto
Ok, así que tenemos cómo generar, editar y depurar basado en entradas visuales. Pero ¿dónde se está implementando esto realmente en el mundo? Porque los investigadores no solo hablan de esto en teoría, ¿cierto?
Alicia
No, para nada. Mapean cuatro dominios distintos donde la codificación multimodal está acelerando actualmente.
Beto
Y el panorama se está expandiendo rápidamente. El primer dominio, y probablemente el que tiene más tracción, es la interfaz gráfica de usuario o GUI.
Alicia
Correcto, esto implica traducir diseños visuales estáticos como capturas de pantalla, maquetas o archivos de diseño a código funcional de front-end, principalmente para web y móvil.
Beto
Y para entrenar estos modelos, los investigadores han construido conjuntos de datos de referencia masivos. El artículo destaca proyectos como WebSight, Web2Code y Design2Code.
Alicia
WebSight es un conjunto de datos particularmente fascinante. Está diseñado para entrenar modelos en cómo traducir perfectamente una imagen a código funcional de React o HTML.
Beto
Pero espera, para entrenar a una IA para construir un sitio web, no puedes simplemente mostrarle fotos de internet. Tienes que mostrarle la imagen y el plano simultáneamente, ¿cierto?
Alicia
Sí. Conjuntos de datos como WebSight contienen millones de páginas web generadas sintéticamente. Por cada página, el conjunto de datos proporciona una captura de pantalla de cómo se ve en un navegador, emparejada directamente con el árbol DOM completo y el código fuente.
Beto
Así que al entrenar con estos millones de ejemplos uno al lado del otro, el modelo aprende el mapeo subyacente.
Alicia
Exacto. Aprende que una disposición específica de píxeles generalmente se correlaciona con una anidación específica de etiquetas `div` de HTML y cajas `flex` de CSS.
Beto
Eso maneja los diseños web estándar. Pero una interfaz de usuario es en su mayoría solo cajas dentro de otras cajas. ¿Qué pasa cuando los datos visuales no son solo estéticos, sino matemáticamente precisos?
Alicia
Eso nos lleva al segundo dominio, que es la visualización científica. Este es un desafío fundamentalmente diferente de una GUI.
Beto
¿Cómo así?
Alicia
Aquí, el objetivo es convertir gráficos estadísticos, gráficos de datos complejos y documentos científicos estructurados en scripts de trazado, como los que escribirías usando la biblioteca Matplotlib de Python.
Beto
Así que la IA tiene que mirar un gráfico, inferir las tendencias de los datos, leer los ejes y leyendas, y escribir el script que genere esa visualización precisa.
Alicia
Sí. Y hay puntos de referencia específicos para esto ahora, como MatplotBench y ChartMimic, que prueban exactamente esta capacidad.
Beto
Lo que significa que tiene que hacer ingeniería inversa de las matemáticas a partir de una imagen plana.
Por ejemplo, si subiera un diagrama de dispersión de un PDF de los 90, la IA no solo está dibujando puntos. Tiene que descubrir la escala X e Y. Mapear la ubicación de píxeles de cada punto a una coordenada y esencialmente reconstruir el arreglo de datos crudos que se utilizó para hacer el gráfico hace 30 años.
Alicia
Requiere un nivel profundo de razonamiento matemático y espacial. El modelo no solo está recreando una textura visual, está reconstruyendo la realidad estadística subyacente.
Beto
Es simplemente salvaje.
Alicia
Y esta dificultad se escala aún más en el tercer dominio, que es la gráfica estructurada. Aquí es donde entramos completamente en el reino de la geometría.
Beto
Correcto. Generar gráficos vectoriales escalables, o SVG, así como diagramas complejos y diseño CAD o de computadora.
Alicia
Sí. Los investigadores mencionaron herramientas como DeepCAD y Text2CAD que están empujando los límites aquí.
Beto
¿Por qué un SVG es más difícil de generar para una IA que una página web HTML estándar?
Alicia
Porque un SVG es esencialmente pura matemática, disfrazada de imagen. Cuando una IA genera una página web, puede confiar en contenedores de diseño relativos. Pero un SVG requiere definir vectores absolutos, curvas Bézier, coordenadas y relaciones geométricas continuas.
Beto
Así que una curva no es solo una colección de píxeles para la IA.
Alicia
No, tiene que ser definida por una ecuación polinómica en el código. El modelo no está organizando bloques visuales. Está definiendo marcos estructurales que literalmente pueden ser alimentados a una cortadora láser o a una tubería de fabricación 3D.
Beto
Eso es un salto increíble. Hemos pasado de generar maquetas de interfaz de usuario, a hacer ingeniería inversa de conjuntos de datos a partir de gráficos, a escribir los planos matemáticos para la fabricación física. ¿Qué podría quedar para el cuarto dominio?
Alicia
Bueno, los investigadores clasifican el cuarto dominio simplemente como "tareas fronterizas". Esta es la vanguardia absoluta.
Beto
¿Qué incluye?
Alicia
Cubre áreas tales como la programación visual, donde el código manipula elementos visuales dinámicamente en un lienzo, y la generación de video, donde la IA sintetiza código que dicta cambios temporales a través de fotogramas.
Beto
Es decir, codificar efectivamente un motor de física o un video para que exista con el tiempo.
Alicia
Exacto.
Beto
Ok, espera, tengo que intervenir aquí con un poco de objeción. Estamos hablando de todos estos puntos de referencia y dominios, especialmente volviendo a la primera, las cosas de la GUI. Si la IA puede mirar una captura de pantalla, escribir el HTML y el CSS, y renderizar una página web que se vea pixel perfecta a mi imagen de referencia original, el trabajo no está terminado.
Alicia
¿Qué quieres decir?
Beto
Quiero decir, si la salida se ve completamente idéntica al objetivo, ¿no hemos resuelto el problema de la codificación multimodal?
Alicia
Esa es la trampa exacta a la que los investigadores en esta encuesta están expuestos. La identifican como un gran obstáculo, llamándolo "el cuello de botella del espejismo" ("Mirage").
Beto
Un espejismo. ¿Cómo es eso? Si se ve como una página web funcional, ¿qué falta?
Alicia
Porque parecer una página web funcional no significa que opere como una. Alinearse puramente con el renderizado del navegador, juzgar la calidad del código generado solo por lo visualmente similar que sea la salida, a la imagen de referencia, es muy engañoso.
Beto
Ya veo.
Alicia
Un fragmento de código generado podría renderizar una interfaz que se ve absolutamente idéntica a tu maqueta. Visualmente puntúa 100% en una prueba de coincidencia de píxeles. Pero por dentro, puede ser una cáscara completamente hueca.
Beto
Así que la estructura DOM puede ser caótica.
Alicia
Exacto. Los botones visuales pueden estar allí, pero carecen completamente de manejadores de eventos ("event handlers"). Si un usuario intenta interactuar con el menú desplegable, no sucede nada porque las transiciones de estado faltan. El enrutamiento interno podría estar completamente roto.
Beto
Es como un set de película de Hollywood. La parte del salón se ve perfectamente real. La pintura es correcta. Las puertas que se abren están allí. Pero si abres las puertas y pasas, no hay ningún edificio real, solo un montón de vigas de madera sosteniendo la fachada. No hay plomería, ni cableado, ni interior.
Alicia
Esa es una analogía perfecta. La similitud visual es una línea base útil. Pero está profundamente incompleta si el código subyacente no funciona realmente en un entorno interactivo funcional.
Beto
Correcto.
Alicia
Una interfaz de usuario solo es correcta a lo largo de una secuencia de estados interactivos, no solo dentro de una instantánea de visualización estática.
Beto
Aquí es donde se pone realmente interesante, porque los investigadores no solo señalan el problema del set de película de Hollywood. Exploran lo que sucede cuando exigimos que el código haga algo de verdad. Y se enfocan ahora en este concepto increíble llamado "razonamiento y actuación centrados en el código".
Alicia
Sí. Y esto representa quizás el cambio de paradigma más profundo discutido en toda la encuesta. Los modelos más avanzados están trascendiendo la idea del código como meramente un producto final visual, ya sabes, un artefacto estático sentado en una pantalla. En cambio, están usando el código como un sustrato robusto para razonamiento avanzado y control ambiental. Están utilizando el código como una política ejecutable.
Beto
Una política ejecutable. Hagámoslo concreto. Porque suena un poco abstracto. ¿Cómo se ve una política ejecutable en la práctica?
Alicia
Veamos de nuevo las tareas fronterizas, específicamente el subdominio del "control incorporado" ("embodied control"). Imagina un brazo robótico autónomo estacionado en una cocina. Las cámaras del robot proporcionan una observación visual continua de su entorno. Ve una mesa desordenada con una tela apoyada en el borde.
Beto
Ok. Y se lo das con una instrucción simple de alto nivel como "limpia la mesa".
Alicia
Correcto. Un desafío clásico de robótica.
Beto
En sistemas más antiguos, imagino que la IA solo intentaría mapear el texto a controles de motor discretos.
Alicia
Exacto. Los paradigmas más antiguos podrían intentar producir comandos de motor crudos y aislados como "mover la articulación A, 15 grados, mover la articulación B, 10 grados". Pero en este nuevo paradigma multimodal, utilizando marcos como Open VLA, que la encuesta destaca específicamente, la IA hace algo completamente diferente. Sintetiza un guión de acción.
Beto
Espera. La IA está escribiendo dinámicamente un guión para sí misma en tiempo real, basado en lo que ve en la habitación.
Alicia
Sí. Toma la observación visual, procesa tu instrucción y escribe instantáneamente un script de Python que conducirá a sus propias acciones. El código que genera es el mecanismo para calcular movimientos espaciales.
Beto
Eso es increíble.
Alicia
El script contiene la lógica que dice: "identifica el cuadro delimitador de la tela en el campo visual; calcula las coordenadas 3D del mundo real; mueve el efector final a las coordenadas x, y, z; cierra la pinza".
Beto
Vaya.
Alicia
Identifica los límites de la superficie de la mesa. Ejecuta una trayectoria barrida a través de estos parámetros espaciales específicos. El código generado actúa como el cerebro de alto nivel, procesando la entrada visual y produciendo interacciones estructuradas con el entorno físico.
Beto
Eso cambia toda la perspectiva sobre lo que es realmente el código. El código no está construyendo un sitio web. El código es la cuerda de marioneta para el mundo físico, generado sobre la marcha basándose puramente en evidencia visual.
Alicia
Y nota cómo esto resuelve el cuello de botella del espejismo por completo dentro de este contexto. En el control incorporado, la fidelidad visual del código en sí no importa. No estás juzgando si el código se ve bien.
Beto
Correcto. Porque lo que importa es el logro de objetivos y la corrección funcional.
Alicia
Exacto. ¿Compiló el script? ¿Ejecutó el bucle? ¿Logró el robot limpiar la mesa sin tirar un vaso? El código empodera al agente con un espacio de acción estructurado y generalizable.
Beto
Fundamentalmente, cierra la brecha entre ver y hacer.
Lo que nos lleva a las conclusiones finales de esta masiva encuesta. Hemos viajado desde luchar por describir una interfaz de usuario y texto hasta modelos que hacen ingeniería inversa de matemáticas a partir de un gráfico, a robots que escriben sus propios scripts de Python para interactuar con el mundo real.
Alicia
Ha sido una evolución masiva.
Beto
Entonces, ¿a dónde dicen esta coalición global de investigadores que debemos ir desde aquí? ¿Cómo superamos los cuellos de botella restantes?
Alicia
Los investigadores proponen una agenda fuertemente centrada en la verificación para el futuro. Se dan cuenta de que ya no podemos simplemente generar código multimodal y confiar en la salida visual. Destacan tres evoluciones necesarias.
Beto
Ok, ¿cuál es la primera?
Alicia
La primera es la validación multi-señal. Acabamos de establecer que no podemos juzgar el código solo por el renderizado del navegador. Tenemos que combinar evidencia complementaria de corrección.
Beto
Así que necesitamos validar el renderizado visual, sí. Pero también necesitamos herramientas automatizadas para analizar la estructura DOM subyacente, verificar la integridad de los manejadores de eventos y verificar la precisión semántica de los datos.
Alicia
Exacto. Básicamente, traer a un inspector de edificios para que revise la plomería y la integridad estructural de la casa, no solo admirar el trabajo de pintura en el porche delantero.
Beto
La segunda dirección es la verificación multi-estado, ¿cierto? Porque el programa no es estático.
Alicia
Correcto. Necesitamos probar rigurosamente cómo se comporta el código generado a través de diferentes interacciones y trayectorias de ejecución a lo largo del tiempo. Si un usuario hace clic en un botón, ¿se actualiza el estado interno correctamente?
Beto
O si redimensionas la ventana a una vista móvil, ¿responde el diseño dinámicamente?
Alicia
Exacto. Debemos verificar el comportamiento de manera interactiva, no solo en una sola pantalla estática.
Beto
Tiene sentido. No puedes probar un coche sin girar el volante.
¿Y la tercera evolución?
Alicia
La tercera es lo que llaman trazas de agentes verificables. A medida que estos modelos evolucionan hacia agentes autónomos como nuestro robot limpiando la mesa, tenemos que garantizar que cuando la IA toma una acción, esta esté anclada en evidencia visual real.
Beto
Así que necesitamos asegurarnos de que no solo esté alucinando una secuencia de pasos, porque leyó sobre pasos similares en sus datos de entrenamiento.
Alicia
Exacto. Necesitamos poder mirar la traza de razonamiento intermedia, los comentarios o registros de código reales que generó, y verificar exactamente por qué tomó su decisión.
Beto
Eso me recuerda a un profesor de matemáticas calificando un examen. El profesor no solo quiere la respuesta final al final de la página. Forza al estudiante a mostrar su trabajo paso a paso.
Alicia
Esa es una gran manera de pensarlo.
Beto
Si la IA deja un rastro de registros de código, dice: "identifico la tela que recogerá será 400 por 500, por lo tanto, establezco la variable objetivo en 400", podemos verificar su lógica.
Alicia
Correcto. Pero si simplemente establece el objetivo de la variable objetivo en 400 sin razón, sabemos que está alucinando.
Si conectamos esto con la imagen más grande, esa verificación es lo que permite que esta tecnología escale de forma segura.
Lo que revela esta encuesta es un cambio monumental en el desarrollo de software. Estamos pasando de la imitación de una sola salida, tratando de copiar ciegamente una imagen de una interfaz de usuario, y pasando hacia sistemas ejecutables y del mundo real, basados en evidencia.
Beto
Está quitando las ruedas de entrenamiento a la IA.
Alicia
De verdad lo está haciendo. Requiere un nivel fundamentalmente más profundo de inteligencia multimodal para pedirle a una IA que no solo dibuje una herramienta, sino que construya una herramienta, verifique su estructura y luego la use.
Beto
Lo que nos deja con un pensamiento final verdaderamente salvaje para reflexionar mientras escuchan en casa. Pasamos décadas pensando en la codificación como un acto de traducción. Tenemos una idea, y escribimos un lenguaje altamente estructurado en un teclado para explicar esa idea a una máquina.
Alicia
Correcto.
Beto
Pero si la IA puede eventualmente mirar un problema complejo del mundo real, digamos un atasco de tráfico capturado en una cámara de ciudad en vivo, o un piso de fábrica público, e instantáneamente generar el código ejecutable para reorganizar los sistemas de física a su alrededor, ¿en qué punto deja de ser la codificación un lenguaje que escribimos en un teclado, y comienza a ser la forma en que simplemente conversamos con el mundo físico?
Alicia
Nos obliga a replantear nuestra interacción completa con la tecnología. En un futuro cercano, puede que dejemos de pensar en términos de sintaxis, variables y funciones por completo, y empecemos a pensar puramente en términos de intención visual y resultados físicos.
Beto
El código simplemente se convierte en el tejido conectivo invisible.
Alicia
Exacto.
Beto
Es un paradigma completamente nuevo. Ya no estarás charlando con un bot en una pantalla, sino que estarás presentando un plano visual a un arquitecto que construye la realidad a tu alrededor.
Gracias por acompañarnos en esta inmersión profunda en la brecha de modalidad. Nos vemos la próxima vez.





{kind=link}