
Hoy les traigo un resumen a otro modelo de razonamiento nuevo, Kimi K2, de código abierto, especializado para crear agentes autónomos. Está ganando popularidad debido a sus puntajes altos en los benchmarks y su diseño innovador.
Enlace al artículo científico, para aquellos que quieran profundizar en el tema: "Kimi K2: Open Agentic Intelligence", por el Equipo Kimi. Publicado el 28 de Julio del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Entonces, si has estado observando la evolución de los grandes modelos de lenguaje, sabes que el juego ha cambiado fundamentalmente. Ya no nos impresiona un modelo que solo puede predecir la siguiente palabra.
Beto
Para nada. Ese frente entero se ha movido. Realmente estamos entrando de lleno en esta era de lo que la gente llama "inteligencia agentiva".
Alicia
Y ese es el cambio de paradigma clave, ¿no?
Beto
Lo es. Una inteligencia agentiva significa que avanzamos hacia modelos que pueden, de forma autónoma, percibir, planificar, razonar y — esta es la parte crucial — actuar en entornos complejos.
Alicia
Es la diferencia entre un modelo que es un brillante analista y uno que es un colaborador capaz que realmente puede llevar un proyecto a cabo.
Beto
Exacto. Ejecutar un proyecto de múltiples pasos por su cuenta.
Alicia
Y liderando esa carga en el mundo del código abierto, haciendo esas capacidades accesibles a todo el mundo, es el tema del análisis de hoy. En Kimi K2 estamos abriendo el informe técnico sobre este enorme modelo de "Mezcla de Expertos" (MoE), y, sinceramente, las especificaciones son salvajes.
Beto
Oh, son absolutamente salvajes. Kimi K2 presume de este tamaño colosal: 1,04 billones de parámetros. Pero ese número es un poco engañoso, ¿no? Porque lo diseñaron con este increíble giro de eficiencia. Es ultra-escaso.
Alicia
Así que para cualquier token individual que procesas, solo se activan una fracción de esos parámetros.
Beto
Una fracción diminuta. Solo 32.000 millones de parámetros se activan realmente.
Alicia
Así que obtienes la potencia de rendimiento de un “cerebro” de billón de parámetros sin el coste de cómputo demencial que normalmente asociarías con eso. Es genial.
Beto
Lo es. Esa optimización es básicamente la piedra angular de todo el proyecto.
Alicia
Nuestra misión hoy, entonces, es desmenuzar el recorrido de Kimi K2. Específicamente, queremos ver las tres innovaciones clave que les permitieron preentrenar este modelo de forma estable a esa escala masiva, y luego cómo lo entrenaron para obtener resultados de vanguardia, especialmente en tareas prácticas como uso de herramientas y programación.
Resultados de Kimi K2
Beto
Y para enmarcar el contexto para quien nos escucha: el equipo de Kimi estaba afrontando un desafío que realmente todos los grandes laboratorios están enfrentando ahora mismo.
- Primero, ¿cómo gestionas escala masiva y alta eficiencia al mismo tiempo?
- Segundo, ¿cómo mantienes que el modelo siga aprendiendo cuando, francamente, el suministro de nuevos datos humanos de alta calidad está estancándose?
Alicia
Rápido. ¿Verdad? Si quieres que un modelo aprenda a actuar en el mundo, tiene que aprender activamente. A través de la interacción, probando y fallando; no puede aprender pasivamente de texto estático para siempre. El propio entrenamiento tuvo que convertirse en una innovación.
Beto
Bien. Desempaquetemos este plano para la estabilidad porque sin él, todo el proyecto de billón de parámetros simplemente explota.
Tenemos la arquitectura: 3,04 billones de parámetros en total, solo 32.000 millones activados. Está usando este diseño MoE ultra-escaso, activando solo ocho de 384 expertos disponibles por pasada.
Alicia
Eso lo hace altamente paralelizable. Ahí es donde obtienes la velocidad y la eficiencia. Pero al escalar ese tipo de arquitectura, especialmente en preentrenamiento, la estabilidad se convierte en una preocupación enorme y constante. El más pequeño error numérico puede simplemente compondar de forma loca.
Beto
Ese es exactamente el desafío que enfrentaron. Querían usar el optimizador token-eficiente Muon, que generalmente es más rápido y mejor converge.
Alicia
Pero es notorio por esto: puede conducir a inestabilidad catastrófica en el entrenamiento, lo que llaman "exploding attention-logits". ¿Puedes desglosarlo?
Beto
Sí, piensa en ello como un avión yendo supersónico. A medida que empujas los límites de velocidad y escala, la presión, los cálculos internos, todo empieza a volverse violentamente inestable. Ahora imagina que muy dentro del mecanismo de atención del modelo, las partes que deciden qué es importante empiezan a crecer exponencialmente. Y eventualmente simplemente obtienes un pico de pérdida completo. Tu entrenamiento se arruina.
Alicia
Entonces, ¿cómo resolvió esto el equipo de Kimi? ¿Cuál fue su cortafuegos técnico?
Beto
La solución es la innovación número uno. El optimizador MuonClip es un matrimonio realmente ingenioso. Mantuvieron la velocidad del algoritmo Muon, pero integraron este mecanismo quirúrgico de estabilidad que llamaron QK-Clip.
Alicia
QK-Clip suena como un seguro de seguridad. ¿Cómo funciona?
Beto
Es una intervención muy elegante. Funciona reescalando los pesos de las proyecciones de queries y keys justo después de una actualización de parámetros. Pero aquí está la parte ingeniosa: no lo hace todo el tiempo.
Alicia
Oh, solo cuando es necesario.
Beto
Exactamente. Solo interviene si el max-logit de atención — ese pequeño valor que señala inestabilidad — excede un umbral preestablecido. Para Kimi K2, fijaron ese umbral, τ, en 100. Es mínimo. Solo interviene en el último segundo para acotar suavemente el crecimiento.
Alicia
Si construyes sistemas a esta escala, la prueba de estabilidad es probablemente el detalle más importante en todo este informe. Y aquí es donde se vuelve asombroso. La documentación dice que el entrenamiento de Kimi K2 no tuvo picos de pérdida en todo el proceso de consumir 15,5 billones de tokens.
Beto
Hagamos una pausa en eso. 15,5 billones de tokens. Es una cantidad de datos casi inconcebible. Y mantener total estabilidad numérica a lo largo de toda esa corrida es, simplemente, sin precedentes para un MoE de este tamaño. MuonClip claramente funcionó.
Alicia
Absolutamente. Esa estabilidad luego les liberó para perseguir la innovación número dos, que se trata de maximizar la inteligencia que podían exprimir de cada token individual.
Beto
Como dijimos, los datos humanos de alta calidad son finitos. Podrías repetirlos, claro. Pero eso solo lleva al sobreajuste con rendimientos decrecientes.
Alicia
Estás peleando ese trade-off. Necesitas exponer al modelo lo suficiente a los datos para que aprenda, pero no tantas veces que simplemente lo memorice todo y no pueda generalizar.
Beto
Y su solución fue generar nuevo contenido a partir de sus datos existentes.
Alicia
Y ahí es donde entra la reformulación de datos.
Beto
Precisamente. Diseñaron una estrategia de generación de datos sintéticos. No se limitaron a traducir o resumir. Pasaron los datos por una canalización de reformulación de alta calidad, enfocándose en dominios como conocimiento y matemáticas.
Alicia
Así que son los mismos hechos presentados en diferentes estilos, tonos y perspectivas.
Beto
Exacto. Variaciones de alta fidelidad del texto original.
Alicia
Eso suena un poco abstracto, pero sus propios estudios de ablación hacen la propuesta de valor cristalina. Tomaron una tarea estándar de conocimiento, QA simple. Si simplemente repetían los datos crudos 10 veces y entrenaban el modelo durante 10 épocas, ¿cuál fue el resultado?
Beto
La precisión fue 23,76%. Eso es tu rendimiento decreciente clásico.
Alicia
OK. Pero luego probaron la estrategia de reformulación.
Beto
Compáralo. Reformularon los datos 10 veces y luego entrenaron el modelo por solo una época en esos datos sintéticamente aumentados. La precisión saltó a 28,94%.
Alicia
Wow. Eso es un incremento de casi cinco puntos porcentuales en precisión con una décima parte del tiempo de entrenamiento. Y no estás arriesgando sobreajustar al material original. Simplemente demuestra que la reformulación sintética es una forma poderosa y viable de aumentar tus datos.
Beto
Bien. Ahora pasamos del pre-entrenamiento central, de construir este cerebro estable y eficiente, a la fase de post-entrenamiento. Y aquí es donde enseñan al modelo a convertirse en un agente sofisticado. Capaz de planificación de múltiples pasos y uso de herramientas externas. Aquí es donde el caucho realmente se encuentra con la carretera.
Alicia
Lo es. Este es el meollo de la inteligencia agentiva porque estas capacidades de alto nivel — planificación, uso de herramientas, recuperación de errores— son realmente raras en los datos web. Quiero decir, los humanos no suelen escribir todo su proceso paso a paso cuando usan, por ejemplo, un software complejo. Así que tienes que sintetizar esos datos.
Beto
Por eso construyeron una canalización de síntesis de datos agentiva increíblemente robusta. Es como una máquina de tres etapas para generar estos problemas de práctica para la IA.
La etapa uno es simplemente construir el universo de herramientas. Crearon un repositorio masivo. Tiene más de 3.000 herramientas MCP (Model Context Protocols) reales. Y luego lo complementaron con más de 20.000 herramientas sintéticas.
Alicia
Y estas cubren de todo, ¿verdad? Comercio financiero, control de robots.
Beto
Todo. Comercio financiero, APIs de control robótico, aplicaciones de software complejas. Es increíblemente diverso.
Alicia
Bien. Eso es la etapa uno. La etapa dos es generar los escenarios. No puedes simplemente tener una herramienta. Necesitas una razón para usarla.
Beto
Correcto. Hay miles de agentes virtuales distintos con prompts de sistema diferentes como “eres un asesor financiero cauteloso” o “eres un solucionador de bugs agresivo”. Y luego emparejaron esos agentes con tareas que tenían rúbricas de éxito explícitas.
Alicia
Y luego la etapa tres es la generación de trayectorias. Esto es simular los diálogos ida y vuelta reales.
Beto
Exacto. Usan un simulador de herramientas sofisticado que actualiza el estado del entorno después de cada llamada a la herramienta para que se sienta realista.
Alicia
Pero la simulación tiene sus límites. No puedes realmente simular la realidad desordenada de escribir código que simplemente falla, ¿puedes?
Beto
No puedes. Absolutamente no. Y por eso hicieron este enfoque híbrido vital. Para tareas de programación y software donde necesitas ejecución verificable, usaron sandboxes de ejecución reales.
Alicia
Así que el modelo realmente ejecuta el código, ¿verdad?
Beto
Sí. El sandbox ejecuta el código. Proporciona errores de compilación reales o retroalimentación de éxito. Asegura que el modelo esté aprendiendo de la autenticidad desordenada del mundo real de programar.
Alicia
Así que una vez que tuvieron ese tesoro de datos agentivos auténticos, pasaron al fine-tuning con aprendizaje por refuerzo (RL). ¿Por qué es tan crítico RL aquí comparado con, digamos, solo "afinamiento supervisado" ("supervised fine-tuning", SFT)?
Beto
SFT enseña imitación. RL enseña toma de decisiones secuencial. El comportamiento agentivo trata sobre una secuencia de acciones que conducen a una meta y SFT simplemente no captura bien esa consecuencia a largo plazo.
Alicia
Es miope.
Beto
Lo es. RL permite al modelo aprender no solo qué hacer a continuación, sino qué acciones conducen a una alta recompensa en toda la tarea y mejora la generalización y la eficiencia de tokens porque el modelo aprende a priorizar acciones que realmente mueven la aguja.
Alicia
Eso tiene sentido perfecto.
Y esto nos lleva a la innovación número tres. El marco RL conjunto, que usa de forma inteligente dos tipos diferentes de recompensas según la tarea.
Beto
Correcto. Para dominios objetivamente verificables, piensa en matemáticas, STEM (ciencia, tecnología, ingeniería, matemáticas), programación, usan lo que llaman "recompensas verificables" (RLVR). Estas son recompensas duras. El resultado es medible por máquina, como un intérprete de código que indica éxito o un solucionador matemático que confirma una respuesta.
Alicia
Pero, ¿qué pasa cuando la tarea es subjetiva, como escribir una historia o responder una pregunta abierta donde no hay una única respuesta correcta?
Beto
Ahí entra la recompensa de rúbrica de autocrítica. Para esas tareas subjetivas, el modelo básicamente se convierte en su propio juez. Genera múltiples salidas y luego realiza evaluaciones críticas por pares contra un conjunto de rúbricas realmente complejo.
Alicia
¿Así que se está calificando a sí mismo?
Beto
De una forma muy sofisticada. Las rúbricas incluyen valores centrales, como la claridad, pero también reglas prescriptivas diseñadas para evitar comportamientos negativos como “reward hacking” o respuestas ambiguas.
Alicia
El modelo se está enseñando alineamiento usando su propio sistema de puntuación interna. Es meta-aprendizaje en su máxima expresión.
Beto
Lo es. Y añadieron dos optimizaciones clave más en el algoritmo RL mismo.
Alicia
La primera suena como una buena lección para todos nosotros: control de presupuesto.
Beto
Ah, sí. Es restricción editorial. Hicieron cumplir un presupuesto máximo de tokens por muestra durante el entrenamiento RL. Esto es crítico porque impide que el modelo genere tokens sin fin. El equivalente IA de divagar. Lo obliga a ser conciso y eficaz.
Alicia
Así que no hay relleno ni titubeos. La eficiencia se recompensa.
Beto
Exactamente. Y en segundo lugar, usan la pérdida PTX, que es una pérdida auxiliar. Esto es básicamente para combatir el olvido catastrófico. Asegura que el modelo no olvide todo lo valioso que aprendió durante el pre-entrenamiento mientras se especializa en estas nuevas tareas agentivas. Mantiene su poder de generalización.
Alicia
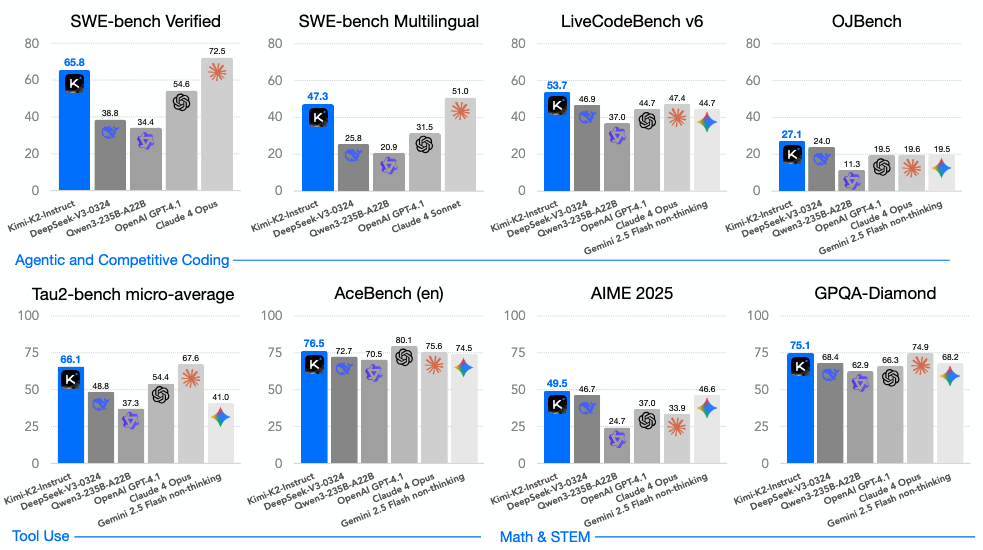
Entonces, ¿qué significa todo esto cuando miramos las puntuaciones brutas de rendimiento? El veredicto es bastante claro. Kimi K2 Instruct es estado del arte entre los modelos de código abierto. Y está cerrando de manera decisiva la brecha con gigantes propietarios como Claude 4 y GPT-4.1.
Beto
Y su entrenamiento especializado para agentes realmente brilla en esas tareas multi-paso complejas. Pero para quien nos escucha, deberíamos aclarar un término que hemos estado usando: modelos “no reflexivos”.
Alicia
Sí. Definámoslo.
Beto
En el contexto de estos benchmarks, “non-thinking” (no reflexivo) se refiere simplemente a la ejecución en una sola pasada. El modelo recibe el prompt, recibe la tarea y genera la respuesta final de una sola vez.
Alicia
Sin segundas oportunidades.
Beto
Sin autocorrección interna, sin reflexión, sin marcos multi-agente. Muchos modelos propietarios usan ahora esos pasos internos de reflexión para subir sus puntuaciones. Las puntuaciones de Kimi K2 se logran sin esa muleta, lo que las hace aún más impresionantes.
Alicia
Bien. Con ese contexto, miremos los benchmarks de ingeniería de software. Y SWE-bench Verified, que es esta prueba agentiva brutalmente difícil.
Beto
Trata de arreglar bugs del mundo real, es dura.
Alicia
Kimi K2 alcanzó una tasa de éxito en un solo intento del 65,8%.
Beto
Eso es simplemente, es absolutamente dominante en ese ajuste de “una sola pasada”. Para poner ese 65,8% en perspectiva, aplasta el 38,8% de DeepSeek-V3, e incluso supera el 54,6% de GPT-4.1 en el mismo setting no reflexivo.
Alicia
Entonces está demostrando esta habilidad sin precedentes en reparación compleja de código.
Beto
Y comprensión, sí.
Alicia
Y sus capacidades generalizadas de uso de herramientas mantienen esa ventaja. En τ2Bench alcanzó 66,1% y en ACEBench 76,5%. Estos números simplemente confirman su fortaleza, no solo en codificación, sino en uso de herramientas impulsado por agentes en escenarios de múltiples turnos de todo tipo.
Beto
Pero tienes razón, no es solo un especialista. Es un generalista muy sólido. Sus puntuaciones de razonamiento son fenomenales. En GBQA-Diamond, que es esencialmente un benchmark de razonamiento a nivel de posgrado, alcanza 75,1%. Eso lidera todas las demás líneas base no reflexivas.
Alicia
Lo que muestra que el preentrenamiento fundamental, los datos y la arquitectura, están a un nivel muy alto.
Beto
Lo están.
Alicia
Pero mientras estas puntuaciones técnicas son esenciales para nosotros, la validación final para ti, el aprendiz, es la preferencia real del usuario. Quiero decir, ¿realmente se siente mejor usarlo?
Beto
Ese es el verdadero test. Y para eso miramos el ranking LMS-YS Arena, que se basa en miles de comparaciones directas cara a cara por usuarios reales.
Alicia
¿Y qué destaca ahí?
Beto
En el leaderboard del 17 de julio de 2025, Kimi K2 Instruct se ubicó como el modelo de código abierto número uno disponible al público. Y quedó quinto en el ranking general del gráfico completo, compitiendo directamente contra todos los modelos propietarios, basado en más de 3.000 votos de usuarios. Eso confirma su calidad práctica y utilidad tanto en inglés como en chino. Quiero decir, esa es la señal más fuerte que puedes obtener de que la tecnología es prácticamente efectiva.
Alicia
Entonces, ¿cuál es la síntesis general aquí?
Kimi K2 representa realmente esta integración exitosa de escala masiva — esos billones de parámetros — con estabilidad radical de entrenamiento gracias a MuonClip, y luego este aprendizaje autodirigido altamente sofisticado ...
Beto
... a través de datos sintéticos de reformulación y ese marco RL conjunto.
Alicia
Para ti, el curioso, este modelo significa un gran paso. La IA de código abierto está avanzando tan rápido. Está pasando de la generación simple de texto y entrando profundamente en dominios prácticos orientados a tareas: ingeniería de software, razonamiento complejo, uso de herramientas.
Beto
Estas son capacidades que están siendo accesibles mediante pesos abiertos. Está nivelando el campo de juego a lo grande.
Alicia
Sin embargo, el equipo de Kimi fue muy honesto sobre las limitaciones internas que encontraron, lo cual siempre señala hacia dónde debe ir la investigación a continuación.
Beto
Absolutamente. Señalaron que el modelo a veces genera demasiados tokens en tareas de razonamiento realmente difíciles, o cuando la definición de la herramienta está dada o es poco clara; ese control de presupuesto ayuda, pero no es perfecto.
Alicia
¿Lo que puede llevar a salidas truncadas o subóptimas?
Beto
Correcto. Y también, aunque sobresale dentro de un framework agentivo de codificación, tratar de hacerle construir un proyecto de software completo y multiarchivo con un prompt de una sola pasada, todavía no es su mejor caso de uso. Aún necesitas ese entorno agentivo envolvente.
Alicia
Y eso nos lleva a un pensamiento final provocador, que se centra en la tensión en ese marco RL conjunto, específicamente el mecanismo de recompensa de autocrítica que detallaste antes.
Beto
Es una elección de diseño fascinante. Ese sistema, por su propia naturaleza, penaliza intencionalmente la auto-cuestionación y el lenguaje ambiguo.
Alicia
Así que no le gustan los “tal vez” o los “parece que...”.
Beto
No, recompensa la decisión, la finalización confiada de la tarea. Y a medida que construimos estos agentes altamente capaces, exigimos confianza, ¿no? Necesitamos que hagan el trabajo.
Alicia
Que sean decididos. Pero la pregunta sigue: si los entrenamos para penalizar la titubez y la auto-cualificación, ¿cómo equilibramos esa necesidad de acción confiada con la honestidad intelectual de mostrar una incertidumbre calibrada? Especialmente cuando una situación es genuinamente ambigua o los datos están incompletos.
Beto
Esa tensión, esa tensión entre confianza e incertidumbre. Eso es lo que va a definir la próxima ola de desarrollo avanzado de agentes.



{kind=link}