
Bueno, la Inteligencia Artificial (IA) ha avanzado tanto que ahora estamos usando agentes, basados en LLMs, para diseñar software. Es es el tema de este artículo reciente. El estudio analiza sistemáticamente 124 artículos, categorizándolos según la tarea de SE ("Software Engineering", ingeniería de software) que abordan (como la generación de código, la depuración y las pruebas) y los componentes de diseño del agente, como la planificación, la percepción, la memoria y el uso de acciones y herramientas.
Enlace al artículo, en inglés, para aquellos interesados en profundizar en el tema: "Large Language Model-Based Agents for Software Engineering: A Survey", por Junwei Liu y colegas, publicado en Diciembre 3 del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Bienvenidos a un nuevo análisis profundo donde convertimos investigación densa en conocimiento inmediato.
Hoy nos estamos sumergiendo en un campo que, de hecho, está reescribiendo por completo las reglas del desarrollo de software mientras hablamos. Hablamos de agentes basados en grandes modelos de lenguaje en ingeniería de software.
Alicia
Es un espacio enormemente dinámico y se está moviendo increíblemente rápido. Probablemente estés familiarizado con los modelos de lenguaje grandes (LLMs) autónomos, esos brillantes pero algo estáticos generadores de texto que pueden redactar un correo o resumir un artículo por ti.
Pero los Agentes basados en LLM son criaturas completamente diferentes. Piénsalos como entidades de IA que usan un LLM como su núcleo cognitivo, su controlador central. Pero, y esto es clave, tienen la capacidad de percibir el entorno y usar recursos y herramientas externas.
Beto
Así que no es solo un cerebro de lenguaje. Es un cerebro de lenguaje con manos y ojos.
Alicia
Exactamente. Esa es una manera perfecta de decirlo. Y eso les permite abordar metas de ingeniería del mundo real muchísimo más complejas que requieren trabajo iterativo, acceso a datos externos e interacción con un entorno de desarrollo real como ejecutar un compilador o incluso hacer clic en un botón.
Beto
Y nuestra misión hoy es darte una instantánea comprensiva del estado actual. El material fuente que sintetizas para esta inmersión profunda está basado en una enorme encuesta de investigación. Y aquí está el dato que realmente subraya la urgencia: el número acumulado de artículos en solo esta área explotó; había 124 para septiembre de 2024. Así que esto no es algún ataque teórico en el futuro. Esto es la vanguardia ahora mismo. Y vamos a desglosar exactamente cómo funcionan estos agentes y qué pueden hacer realmente.
La Arquitectura Central
Bien, desgranémoslo con el segmento uno: La arquitectura central. ¿Qué es lo que transforma un brillante modelo de lenguaje en un agente autónomo orientado a la acción?
Alicia
Pues bien, la diferencia fundamental es que el LLM está incrustado dentro de un bucle cerrado. Este cerebro controlado por el LLM está interactuando constantemente con el entorno. Y para hacerlo con éxito necesita cuatro capacidades distintas: planificación, memoria, percepción y acción.
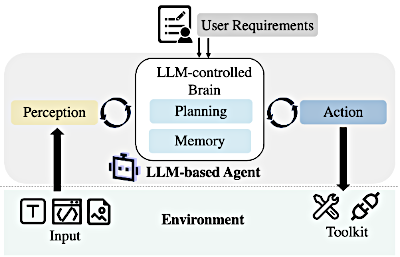
Marco básico de los agentes basados en LLMs
Planificación
Beto
Empecemos por la planificación. Porque la ingeniería, por su propia definición, trata de seguir un proceso. ¿Cómo aborda un agente una tarea realmente compleja como, digamos, construir una interfaz web básica para X, cuando el LLM en sí mismo trata principalmente con lenguaje?
Alicia
La planificación es lo que permite al agente descomponer ese objetivo gigantesco y complejo en subtareas manejables. Ya sabes, cosas como crear el esquema de la base de datos, luego escribir el endpoint de la API y luego construir los componentes del front-end.
Beto
Sí, descomponerlo.
Alicia
Exacto. Y vemos dos comportamientos primarios aquí. Primero, el agente puede generar un plan inicial desde el principio. A menudo usa estas estrategias de razonamiento; probablemente hayas oído hablar de "Chain of Thought", CoT (Cadena de Pensamiento).
Beto
Así escribe su propia lista de tareas antes de empezar. Algo así como un plano fijo.
Alicia
Plano fijo, sí. Pero la segunda capacidad es, quizá, más crítica para cualquier tipo de fiabilidad en el mundo real. Y esa es la capacidad de ajustar ese plan generado sobre la marcha. Si intenta escribir la API y una prueba falla, el plan tiene que modificarse en función de ese feedback externo. No importa si ese feedback es un error del compilador o, ya sabes, una instrucción de un humano. Está reevaluando constantemente su enfoque en base a la realidad.
Memoria
Beto
Y me imagino que ese tipo de proceso iterativo de múltiples pasos requiere un sistema de memoria bastante robusto. ¿Cómo mantienen estos agentes el contexto a lo largo de un proyecto largo y complejo sin olvidar lo que hicieron cinco pasos antes?
Alicia
La memoria es absolutamente esencial. Registra pensamientos históricos, acciones, observaciones del entorno, todo. Básicamente lo categorizamos en dos tipos principales: Para el trabajo inmediato, la tarea en curso, tenemos memoria a corto plazo. Esto almacena cosas como registros simples de diálogo o, de manera más eficiente, algo llamado "registros de acción‑observación‑crítica".
Beto
¿Puedes aclarar eso, qué son exactamente los registros de acción‑observación‑crítica?
Alicia
Claro, piénsalo como un diario de aprendizaje muy detallado o quizá un registro de errores sofisticado:
- Registra qué hice — esa es la acción —,
- qué ocurrió — la observación —, como "la prueba falló con el error X"—, y luego,
- lo que concluí — la crítica —. Tipo: "Ok, el error probablemente está en la línea 42".
Esta memoria a corto plazo es crítica para la tarea actual.
Beto
Entendido. Y eso contrasta con la memoria a largo plazo, que se parece más a un archivo de proyecto.
Alicia
Correcto. La memoria a largo plazo es donde el agente guarda cosas como trayectorias destiladas, grafos de conocimiento o datos vitales, como los resultados finales exitosos de proyectos pasados. Esos datos no son realmente para depurar la subtarea inmediata, sino para la planificación futura, transfiriendo lo que ha aprendido entre proyectos completamente distintos.
Percepción
Beto
Bien, lo siguiente es la percepción. ¿Cómo ve el agente lo que está pasando? Empezamos esta conversación asumiendo que el texto es la entrada principal, pero ¿qué pasa con la realidad visual del software, especialmente en interfaces de usuario?
Alicia
Pues, aunque leer código y requisitos sigue siendo la entrada predominante — esa es la principal forma en que toman información —, la investigación apunta claramente hacia la creciente importancia de la entrada visual. Específicamente, en un dominio como las pruebas de GUI, los agentes empiezan a usar modelos especializados como SegLink++ y Screen Recognition para procesar capturas de pantalla.
Beto
¿Así que el agente puede literalmente mirar una captura de pantalla de una aplicación?
Alicia
Sí, exactamente. Esto le permite localizar con precisión widgets (componentes visuales), ya sabes, "dónde está el botón de enviar" o "qué elemento muestra un mensaje de error". Y luego combina ese contexto visual con la entrada textual para, bueno, para una efectividad mucho mayor en tareas como navegación web automatizada o pruebas de aplicaciones.
Acción
Beto
Y por último, acción. Aquí es donde culmina todo el ciclo. Cómo el agente realmente modifica el entorno.
Alicia
La acción es esa capacidad para interactuar. Y el mecanismo más esencial aquí es la habilidad para controlar y utilizar herramientas externas. Si el agente necesita compilar código, ejecutar pruebas, acceder a una base de datos o buscar en la web documentación de una API, usa su capacidad de acción para operar esa herramienta externa. Esto es lo que verdaderamente extiende al LLM más allá de ser solo una utilidad de lenguaje hacia un agente funcional y ejecutor.
Colaboración - Multi-Agentes
Beto
Esa funcionalidad ya es bastante compleja cuando un agente trabaja solo, pero construir software del mundo real es un deporte de equipo. Y eso nos lleva naturalmente al segmento dos: colaboración. La fuente señala que las tareas complejas a menudo requieren sistemas multiagente.
Alicia
Son absolutamente críticos. Sí, especialmente para abordar tareas que requieren dominios de conocimiento especializados y diversos. Y la arquitectura imita a los equipos humanos de una manera realmente notable. A los agentes se les asignan roles distintos, experiencia especializada, y se comunican constantemente para compartir progreso. Esto les permite trabajar de forma colaborativa, atacando diferentes subtareas, o incluso competitivamente, donde pueden debatir la mejor solución antes de ejecutarla.
Beto
Eso suena justo como un equipo de ingeniería real discutiendo elecciones de diseño en una sala de reuniones. ¿Qué tipos de roles suelen adoptar estos agentes?
Alicia
Los roles se basan en una taxonomía que, tienes razón, refleja a los equipos humanos. Hay roles de gestor responsables de la descomposición inicial de la tarea y la asignación. Están los arquitectos y diseñadores que manejan la estructura del sistema a alto nivel. Luego los desarrolladores que realmente escriben el código. Y, de manera crucial, los roles de garantía de calidad como revisores de código y testers. Estos roles crean esa especialización y rendición de cuentas.
Beto
Cuando colaboran, ¿cómo se estructura realmente esa interacción? Me imagino algo lineal para tareas pequeñas. Pero si están debatiendo o refinando algo, deben necesitar algo más complejo.
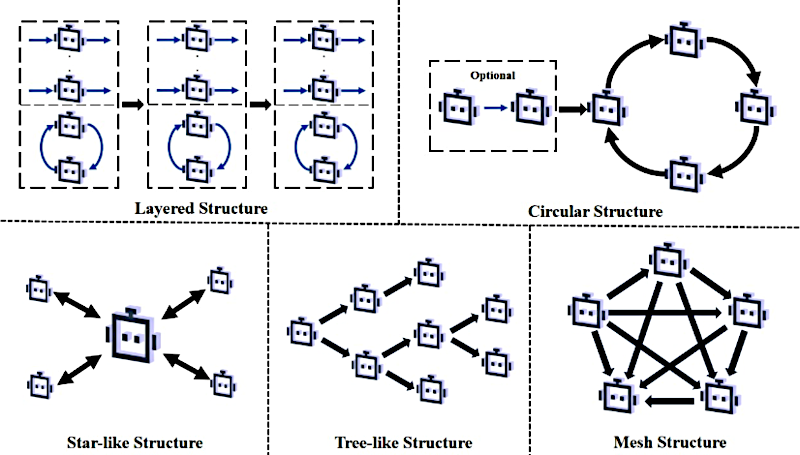
Mecanismos de colaboración en sistemas multi-agente
Alicia
Exacto. La estructura define el modo de colaboración. El más común es la estructura en capas, que es secuencial. Piénsalo como una línea de montaje. La salida de un agente alimenta la entrada del siguiente. El arquitecto pasa el diseño al desarrollador que pasa el código al tester.
Beto
Eso es eficiente, pero muy rígido. ¿Y qué pasa con ese feedback iterativo del que hablamos?
Alicia
Para eso necesitas la estructura circular. Esta está diseñada específicamente para ese feedback continuo y refinamiento. A menudo se ve como un bucle generación‑validación entre dos roles especializados. Así el desarrollador escribe el código y el tester lo valida, enviando informes de error de vuelta al desarrollador hasta que la tarea se completa.
Beto
¿Y cómo se pasa realmente la información entre ellos? ¿Solo tiran código terminado por encima del muro o realmente hablan?
Alicia
Vemos dos flujos principales. Primero está la transferencia unidireccional, que es muy impulsada por los datos. El siguiente agente simplemente toma la salida final del predecesor como su entrada fija. Ese es el modelo de la línea de montaje. Pero para el verdadero trabajo en equipo usan chat bidireccional. Aquí, los agentes comparten todo su historial de diálogo, lo que les permite participar en una discusión colaborativa, hacer preguntas aclaratorias y gestionar ese contexto compartido, mucho como una breve reunión de equipo.
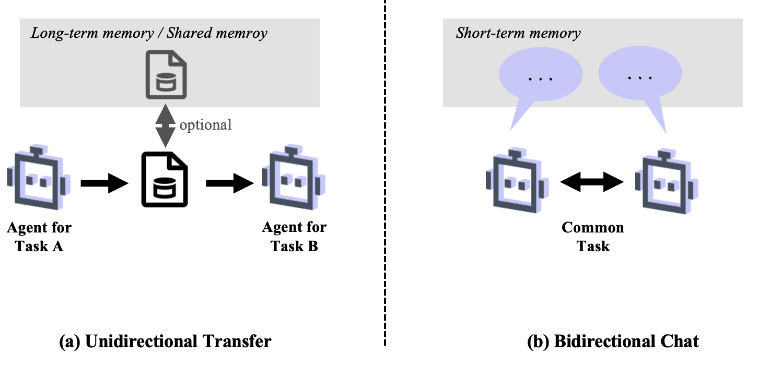
Flujos principales
Beto
Pero aún con toda esta interacción IA–IA, el humano sigue siendo crucial, especialmente para definir requisitos y control de calidad. ¿Dónde encaja la coordinación humana de agentes en todo este ciclo de vida?
Alicia
Los humanos sirven como esas guías esenciales durante las fases críticas. Vemos entrada humana durante la planificación, donde una persona puede revisar un flujo de trabajo autogenerado si ve una ruta más lógica o más segura. La vemos durante los requisitos, aclarando ambigüedades. Incluso hay sistemas como ClarifyGPT diseñados para identificar proactivamente requisitos vagos y hacer al usuario humano preguntas específicas antes de escribir una sola línea de código.
Beto
¿Entonces el agente, en esencia, obliga al humano a ser un mejor cliente?
Alicia
Precisamente. Y esto continúa a lo largo del desarrollo, donde los humanos pueden corregir errores o guiar ediciones complejas de código, hasta la evaluación, que a menudo requiere pruebas de aceptación manuales del producto final para asegurar que el usuario puede identificar los requisitos necesarios. Es decir, una persona es quien juzga finalmente si satisface esos requisitos imprecisos.
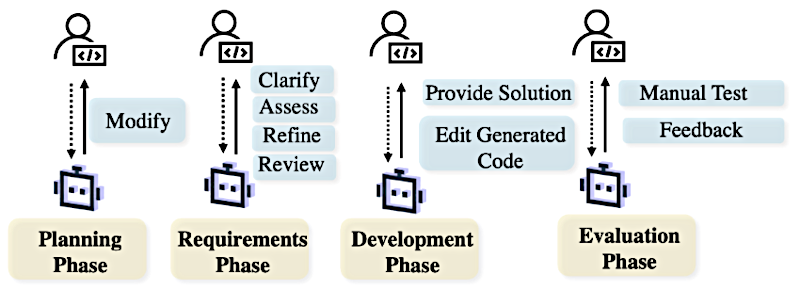
Colaboración Humano-Agente en SE
Beto
Esa integración de la guía humana es fascinante.
Aplicaciones Claves
Pasemos al segmento tres y entremos en algunas aplicaciones clave dentro del ciclo de vida del software, empezando por la generación de código.
Generación de código
Alicia
Bueno, la generación de código es donde las capacidades de planificación y acción realmente brillan. Necesitamos distinguir entre dos enfoques de planificación aquí. Uno es la ingeniería de prompts, como la Cadena de Pensamiento (CoT) que mencionamos, donde el plan es fijo y determinado desde el principio. Cualquier LLM estándar puede hacer eso.
Beto
Pero el enfoque verdaderamente novedoso que pertenece a los agentes ...
Alicia
Sí, son las estrategias agénticas. Estas adaptan dinámicamente el plan en función de pensamientos históricos, observaciones del entorno, resultados de pruebas, lo que sea. Si el agente encuentra un error en el paso tres, no se queda bloqueado. Revisa los pasos cuatro a diez. Y este enfoque flexible requiere esa configuración completa de agente basado en LLM que hemos estado describiendo.
Retroalimentación
Beto
Ese enfoque dinámico debe depender muchísimo del "feedback" (retroalimentación). ¿Qué tipos de retroalimentación usan estos agentes para refinar su salida una y otra vez?
Alicia
Hay cuatro tipos básicos que impulsan ese refinamiento.
Primero, feedback del modelo. Esto implica ya sea reflexión pura — un agente revisando el trabajo de otro, como un marco de salvaguarda de auditorio — o autorreflexión. Que está diseñada para imitar la clásica técnica del "rubber‑duck debugging" (depuración con el patito). El agente literalmente habla del problema consigo mismo, revisando su propio razonamiento.
Beto
Lo cual es una forma fantástica de detectar errores lógicos antes de que se conviertan en fallas.
Alicia
Lo es.
El segundo tipo es feedback de herramientas. Esto significa usar herramientas externas como analizadores estáticos para analizar la calidad del código o, crucialmente, herramientas de recuperación. Las herramientas de recuperación permiten al agente acceder a motores de búsqueda en línea o documentación privada de API. Y este acceso externo es vital para mitigar dos grandes problemas de los LLM: la aleatoriedad y las alucinaciones. Pueden verificar hechos contra fuentes fiables.
Beto
Así que las herramientas proporcionan los datos duros y el modelo proporciona la interpretación.
¿Cuáles son los otros dos tipos de feedback?
Alicia
El tercero es feedback humano, que ya mencionamos. Es crucial para clarificar ambigüedades y asegurar la intención.
Y el cuarto es feedback híbrido, donde vemos algunas de las innovaciones más serias. Esto combina los informes de error objetivos y precisos de una herramienta con el poder interpretativo del LLM.
Beto
¿Puedes darnos un ejemplo de cómo funciona ese feedback híbrido? Más allá de obtener un simple error de compilación.
Alicia
La fuente destaca un ejemplo brillante, un método llamado LDB ("Large Language Model Debugger"). La mayoría de los sistemas solo analizan la salida final del programa: "¿pasó la prueba o no?" LDB va mucho más profundo. Recopila y analiza el estado de ejecución intermedio. Eso significa que el agente monitoriza realmente los estados en tiempo de ejecución de variables y estructuras de datos antes y después de que se ejecute cada bloque de código.
Beto
Wow, eso es exactamente lo que hace un ingeniero humano cuando pone un punto de interrupción en su código.
Alicia
Es el equivalente más cercano que tenemos en IA. Al mezclar esa información de tiempo de ejecución, precisa y basada en datos, con la capacidad del LLM para razonar sobre la lógica del código, este enfoque híbrido conduce a un rendimiento y depuración demostrablemente mejores que simplemente analizar el resultado final de aprobado/fallido.
Beto
Esa profundidad realmente muestra que los agentes están yendo más allá de tareas individuales y empiezan a cubrir todo el proceso de desarrollo de extremo a extremo. ¿Cómo están adaptando los modelos de proceso humanos clásicos?
Alicia
Los están adaptando por pura necesidad. Adaptan el "modelo en cascada" forzando iteraciones para control de calidad, e incorporan la verificación en ciclo porque un proceso lineal LLM sin verificación no funciona. Y adaptan métodos ágiles como "desarrollo guiado por pruebas" (TDD) o "SCRUM". Cuando emulan SCRUM, por ejemplo, los marcos de agentes a menudo simplifican el proceso omitiendo, curiosamente, la reunión diaria SCRUM.
Beto
¿Espera, omiten la reunión diaria? ¿Por qué harían eso?
Alicia
Se reduce a los mecanismos de memoria compartida de los agentes. Dado que todos los agentes participantes tienen acceso a este historial continuo de diálogo y al archivo de contexto, la necesidad humana tradicional de una sincronización diaria para reiterar el progreso e identificar bloqueos se vuelve en gran medida redundante. Su comunicación es continua y asincrónica por diseño.
Limitaciones
Beto
Todo esto suena como un progreso fenomenal, pero cada análisis profundo revela puntos de fricción.
Veamos el segmento cuatro. ¿Cuáles son las limitaciones prácticas actuales? Las causas comunes de fracaso con las que los investigadores están lidiando. ¿Dónde fallan consistentemente estos agentes?
Alicia
Los fallos se agrupan en torno a la gestión de la complejidad y el contexto. En sistemas multiagente vemos fallos frecuentes de coordinación. Cuando se les encarga comunicarse para resolver problemas, pueden atascarse fácilmente en ciclos conversacionales infinitos. La fuente menciona casos donde los agentes simplemente se dicen repetidamente "gracias" o "adiós", porque los criterios de terminación no se gestionan con la suficiente estrictitud.
Beto
Eso es a la vez gracioso y profundamente frustrante. Imagina quemar miles de dólares en cómputo solo para escuchar robots agradecerse mutuamente para siempre.
Alicia
Es un problema muy real que subraya el desafío de la autonomía verdadera.
También vemos problemas mayores con feedback defectuoso que lleva a errores en cascada. Por ejemplo, en un estudio detallado sobre agentes de depuración, un asombroso 33% de los casos fallidos fueron causados por el fallo del feedback del modelo para identificar con precisión la ubicación del error.
Beto
Así que el agente está confiado y precisamente equivocado, y eso desorienta todo el proceso de autocorrección.
Alicia
Exacto. Y suites de pruebas de baja calidad, ya sean creadas por el agente o preexistentes, engañan al agente de la misma manera. Si el feedback es basura, el proceso de refinamiento solo produce más basura.
Beto
Y si una tarea implica un refinamiento de muchos pasos a lo largo de semanas, la pura cantidad de historial de interacción debe volverse abrumadora.
Alicia
Ese es el desafío central de la gestión del contexto. A medida que ese historial de interacción crece, la capacidad del agente para razonar sobre ese contexto largo simplemente se degrada. El "cerebro" del LLM lucha para extraer eficientemente información útil de miles de líneas de pensamientos pasados y acciones fallidas, llevando a lo que los investigadores llaman "sobrecarga de contexto".
Beto
Entonces, si los agentes son tan complejos y los fallos tan sutiles, debe haber una gran brecha en cómo medimos siquiera su éxito. ¿Qué necesita cambiar sobre la evaluación?
Alicia
Hay una necesidad crítica y ampliamente reconocida de mejores evaluaciones y benchmarks mucho más desafiantes. Actualmente, muchos benchmarks a nivel de proyecto son menos complejos que las tareas empresariales del mundo real. Por ejemplo, en un benchmark como ProjectDev, la descripción media de requisitos de software es solo de 262 palabras. Incluso el ampliamente usado SWE‑bench Lite, a menudo implica tareas que un ingeniero humano experimentado podría completar en menos de una hora.
Beto
Esa escala es necesaria para la investigación, lo entiendo. Pero falla en capturar la complejidad de una enorme base de código heredada en una empresa.
Alicia
Precisamente. Y más allá de la complejidad, el enfoque actual de evaluación está casi exclusivamente en la tasa de éxito final. "¿Pasó la prueba?" Sí o no. Los investigadores llaman con urgencia a métricas finas para evaluar los pasos intermedios. Necesitamos métricas como la tasa de retroceso (backtracking), la proporción de acciones erróneas, o evaluaciones detalladas de los módulos internos de planificación y memoria. Necesitamos saber cómo fallaron, no solo que fallaron.
Beto
Finalmente, a medida que estos agentes pasan de los sistemas de laboratorio a producción, la cuestión de la confiabilidad debe volverse absolutamente primordial.
Alicia
Absolutamente. Avanzando, la comunidad tiene que ir más allá de métricas simples de efectividad. Necesitamos evaluar robustamente requisitos no‑funcionales como privacidad, seguridad, equidad y robustez general, especialmente porque, como hemos visto, estos agentes pueden exhibir comportamientos inestables e impredecibles. Asegurarlos como seguros y fiables es una gran frontera.
Beto
Para resumir nuestra inmersión: los agentes basados en LLM ofrecen un rendimiento superior y una aplicabilidad mucho más amplia en ingeniería de software comparados con los LLM independientes. Y esa superioridad está fundamentalmente habilitada por su capacidad de percibir el entorno, tanto visual como textualmente, de planificar dinámicamente y de ejecutar de manera iterativa usando herramientas especializadas, a menudo colaborando en sistemas multiagente estructurados.
Alicia
Y mirando hacia adelante, mientras la tentación y la investigación siempre empujan por máxima complejidad y máxima autonomía, el futuro de estos agentes demanda una mayor colaboración humano‑agente y, curiosamente, una integración más inteligente de la experiencia clásica en ingeniería de software. Lo fascinante es la observación de que algunos marcos de agentes, usando un flujo de trabajo relativamente simplista basado en las canalizaciones clásicas de localización de fallos y reparación que los ingenieros humanos perfeccionaron durante décadas, han demostrado superar a diseños de agentes totalmente autónomos y mucho más complejos.
Beto
Y aquí tienes una idea provocadora para masticar: si priorizamos la fiabilidad y la interpretabilidad por encima de todo, ¿cuánta autonomía máxima de un agente deberíamos sacrificar intencionadamente adhiriéndonos estrictamente a esos procesos clásicos humanos de ingeniería de software bien probados? ¿Debería la meta ser complejidad máxima e impredecible, o disciplina y fiabilidad guiadas por la tradición?



{kind=link}