
Acaba de salir un modelo de lenguaje de razonamiento (RLM) poderosísimo, y es código abierto: Se trata de la versión v3.2 de DeepSeek. Se desempeña a la par con los grandes modelos comerciales de IA (OpenAI GPT, Anthropic Claude, Google Gemini) pero a una fracción de su costo de desarrollo, y trae nuevos avances en su arquitectura.
Enlace al artículo en inglés, para los que quieran profundizar en el tema: "DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models", por DeepSeek AI. Publicado el 2 de Diciembre del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos de nuevo a un análisis profundo. Hoy estamos cavando en una pila de artículos sobre DeepSeek V3.2, un nuevo gran modelo de lenguaje abierto que está intentando hacer algo bastante monumental.
Beto
Lo es. Sí, “monumental” es la palabra correcta. Las fuentes que tenemos enmarcan este modelo como una especie de contraataque directo.
Alicia
¿Un contraataque a qué?
Beto
A esa brecha de rendimiento que se está ensanchando. La que existe entre los sistemas de código abierto y los grandes modelos propietarios de frontera; hablamos de GPT-5, Gemini 3.0 Pro, ese nivel.
Alicia
Y esa brecha, lo que los investigadores llaman "la divergencia", ha sido un verdadero punto crítico para la comunidad de código abierto, ¿no es así? Siempre da la sensación de que están intentando ponerse al día.
Beto
Exacto. Las fuentes dicen que esta divergencia se reduce a tres problemas centrales: límites arquitectónicos, recursos insuficientes y ese desfase para agentes que llaman “agentic generalization”.
Alicia
Es muchísimo para cubrir, pero tenemos que empezar por el hallazgo principal. Es realmente algo.
Beto
Sí, porque esto realmente cambia las reglas del juego para los modelos abiertos. La versión de alta computación, DeepSeek V3.2 Special, ha alcanzado una capacidad de razonamiento que es genuinamente comparable a Gemini 3.0 Pro.
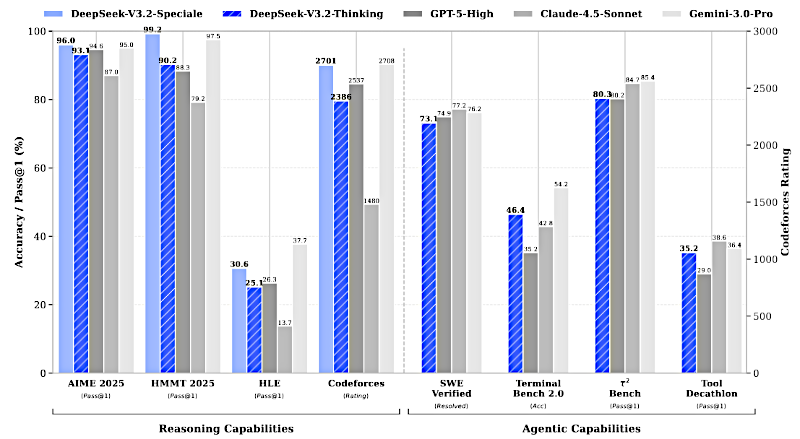 Benchmarks comparando DeepSeek v3.2 frente a otros modelos comerciales.
Benchmarks comparando DeepSeek v3.2 frente a otros modelos comerciales.
Alicia
Y la prueba que ofrecen para eso es simplemente, es impactante.
Beto
Lo es. Las fuentes muestran que obtiene medallas de oro tanto en la Olimpiada Internacional de Matemáticas 2025 (IMO) como en la Olimpiada Internacional de Informática (IOI).
Alicia
Medallas de oro. En olimpiadas de matemáticas y de programación, eso es el tipo de logro que hace que toda la industria se detenga y preste atención. Es un salto masivo en razonamiento bruto.
Beto
Un salto enorme.
Alicia
Vale, retrocedamos un segundo. Mencionamos esa divergencia. Para ti, el oyente, recuérdanos ¿por qué se abrió tanto esa brecha en primer lugar?
Beto
Las fuentes son bastante claras en esto. Todo se reduce a limitaciones en la escala. La primera es lo que llaman la "limitación arquitectónica".
La mayoría de los modelos abiertos más antiguos se construyeron sobre mecanismos de atención “vainilla”. Y eso significa que chocas con el notorio problema de O(L2).
Alicia
Y para quien necesite un repaso, ¿por qué es ese costo O(L2) tan devastador para estos modelos grandes?
Beto
Pues porque el coste computacional para manejar una secuencia crece de forma cuadrática con la longitud L. Así que si duplicas el número de tokens que el modelo está mirando, el coste no se duplica. Se cuadruplica. Y eso se convierte en un cuello de botella imposible muy rápido. Mata tu eficiencia para secuencias largas y hace que el despliegue sea increíblemente caro.
Alicia
Ese problema arquitectónico crea directamente la segunda limitación, ¿verdad? El problema de asignación de recursos.
Beto
Precisamente. Si cuesta una fortuna ejecutar el modelo a escala, no puedes permitirte invertir en las etapas post-entrenamiento ...
Alicia
... que realmente importan, que es donde los modelos propietarios han estado vertiendo dinero.
Beto
Absolutamente. Han podido dedicar computación masiva al post-entrenamiento, hablamos de gran escala de aprendizaje por refuerzo (RL) y los modelos abiertos simplemente se estrellaron contra un muro económico. No podían seguir el ritmo.
Alicia
Y eso lleva al tercer problema, el atraso de agentes. Los modelos podían, ya sabes, responder preguntas, pero no podían realmente hacer cosas.
Beto
Sí, una deficiencia marcada en seguir instrucciones, usar herramientas, generalizar a tareas nuevas, todas las cosas que necesitas para un agente verdaderamente útil. Deepseek sabía que tenían que resolver los tres para siquiera tener una oportunidad.
Alicia
Así que empecemos con esa primera solución, atacar el cuello de botella cuadrático con algo que llaman "DeepSeek Sparse Attention" o DSA. Suena súper técnico, pero ¿hay una manera fácil de pensar en cómo recortaron esa complejidad?
Beto
Sí, DSA es la gran solución arquitectónica, y cambia completamente la economía. En lugar de O(L2) — pesadilla cuadrática — lo reducen a O(LK). Y K es simplemente una fracción diminuta de la longitud total L.
Alicia
¿Puedes darnos una metáfora para eso?
Beto
Claro, piénsalo así. La forma antigua, la atención vanilla, es como un bibliotecario que tiene que leer cada palabra en cada página de cada libro de la biblioteca, solo para responder una pregunta cada vez.
Alicia
Increíblemente lento y caro.
Beto
Es exhaustivo. Pero DSA es como un bibliotecario hiper eficiente. Tiene un indexador relámpago que calcula rápidamente una puntuación de relevancia, como leer las tarjetas del índice. Y luego solo recupera las K entradas clave-valor principales.
Alicia
Así que solo lee los párrafos más importantes, no toda la biblioteca.
Beto
Exacto. Solo presta atención a los K tokens más importantes, no a los L tokens.
Alicia
Pero recortar así, ¿no suele perjudicar el rendimiento? ¿Cómo sabemos que el modelo sigue siendo igual de inteligente?
Beto
Esa es la pregunta crítica y las fuentes lo confirman. Esta esparcidad mantiene el rendimiento del modelo incluso en esos escenarios de contexto muy largos, hasta 128K tokens. Así que no tuvieron que sacrificar la precisión por velocidad.
Alicia
Y se ve directamente en el coste, ¿verdad? Los artículos tienen gráficos sobre costos de inferencia usando 800 GPUs. Y la caída no es sutil.
Beto
Para nada. Miras el coste por millón de tokens y es una disminución dramática, especialmente cuando llegas a secuencias más largas. Una vez superas los 64K tokens más o menos, DeepSeek es simplemente mucho más barato de ejecutar. Eso es lo que hace que una ventana de contexto de 128K sea realmente práctica para modelos abiertos.
Alicia
Bien, arreglaron la arquitectura, bajaron el coste. Y eso abre la puerta para abordar el segundo desafío: escalar realmente la inteligencia con más computación.
Beto
Sí, no podían limitarse a ser baratos. Tenían que ser inteligentes. Y eso significó poder permitirse dedicar mucho dinero al problema.
Alicia
Y lo hicieron. El artículo dice que adoptaron un protocolo de RL escalable y comprometieron un presupuesto de post-entrenamiento de más del 10% del costo de pre-entrenamiento.
Beto
10%. Es una cifra colosal. Quiero decir, históricamente los modelos abiertos podían usar uno o dos por ciento para fine-tuning. Esto es una inversión masiva. Y todo se centró en el razonamiento profundo.
Alicia
Pero simplemente lanzar más computación al RL suele ser una receta para el desastre. Se vuelve inestable, los modelos colapsan, olvidan cosas.
Beto
Oh, absolutamente.
Alicia
Aquí es donde la ingeniería es realmente impresionante, ¿no? Tuvieron que incorporar estrategias novedosas en su algoritmo GRPO, group relative policy optimization.
Beto
Aquí es donde tenemos que traducir un poco la jerga, porque las correcciones que hicieron son realmente quirúrgicas. Y son esenciales para mantener todo esto estable.
Alicia
Dame la analogía de conducir un coche de carreras.
Beto
Bien. Piensa en el proceso de RL como enseñar a una IA a conducir un coche de carreras muy complejo. Si el alumno de repente hace un movimiento salvaje e impredecible, necesitas una forma de sacarlo de la pista antes de que choque toda la simulación.
Alicia
Vale, eso tiene sentido. ¿Cuáles fueron sus principales herramientas de estabilidad?
Beto
Primero fue la estimación KL no sesgada. Arreglaron algo llamado estimador K3. En términos simples, dejaron de permitir que el sistema se mintiera sobre lo buenas que eran sus decisiones, especialmente cuando intentaba algo nuevo con baja probabilidad de éxito.
Alicia
Así que es un aprendizaje controlado y con incentivo, sin maniobras bruscas.
Beto
Exacto. Y eso permite una convergencia controlada mucho más estable. Luego, para lidiar con el problema de chocar el coche, usaron "enmascaramiento de secuencias fuera de política" ("off-policy sequence masking").
Alicia
Lo que significa ...
Beto
... que cuando estás entrenando con estos lotes enormes de datos, inevitablemente obtienes algunos ejemplos donde el modelo simplemente falla por completo. Quiero decir, se sale totalmente de la política. En lugar de dejar que esos ejemplos malos descarrilen todo el proceso de entrenamiento, simplemente los enmascaran.
Alicia
Filtras los datos tóxicos.
Beto
Los filtras antes de que puedan desestabilizarlo todo. Es un truco práctico y listo para la estabilidad a escala.
Alicia
Y como este es un modelo de mezcla de expertos, un MoE, tuvieron otras complicaciones que atender.
Beto
Sí, los MoE tienen esa capa extra de enrutamiento donde el modelo tiene que elegir a qué experto enviar un problema. Esa elección, esa ruta, puede causar inestabilidad si cambia. Así que introdujeron "keep routing".
Alicia
Que simplemente fuerza a que el camino del experto permanezca igual.
Beto
Preserva la ruta del experto que se usó durante el muestreo inicial. Asegura consistencia. Y de forma similar, tienen la "keep sampling mask", que hace lo mismo para métodos de muestreo como "top-p" o "top-k". Simplemente mantiene las matemáticas coherentes.
Alicia
Todo este trabajo de ingeniería increíble solo para mantener el entrenamiento estable bajo esta inmensa presión computacional.
Beto
Y esa inversión masiva y focalizada es lo que nos da la variante medalla de oro. DeepSeek-V3.2-Speciale.
Alicia
... la central de razonamiento ...
Beto
... es el resultado de toda esa inversión. Entrenada exclusivamente con datos de razonamiento, optimizada para pruebas, lógica y deducción. Y como dijimos, está alcanzando la paridad con Gemini 3.0 Pro, ganando esas competencias — incluso superó el rendimiento reportado de GPT-5 en un benchmark de alta dificultad, alcanzando 99.2% de exactitud.
Alicia
Así que la gran conclusión es que los modelos abiertos ahora pueden alcanzar ese techo de razonamiento ...
Beto
... que antes parecía exclusivo de los laboratorios propietarios. Sí.
Alicia
De acuerdo, pero aquí tenemos que ser críticos. El rendimiento es fenomenal, pero el material fuente apunta a una compensación crucial: la eficiencia en tokens.
Beto
Ese es el gran asterisco en esa medalla de oro. Tienes razón. DeepSeek V3.2, especialmente, puede obtener una clasificación competitiva en Codeforces de 2701, pero necesita muchos más tokens para hacerlo.
Alicia
Y cuando dices “muchos más”, hablamos de una diferencia enorme.
Beto
Así es. Para obtener esas soluciones de programación necesitó alrededor de 77,000 tokens. Gemini 3.0 Pro obtuvo una valoración ligeramente superior, 2708, con solo 22,000 tokens.
Alicia
Así que es una diferencia de 4 a 1 en coste de tokens para conseguir básicamente el mismo resultado.
Beto
Exacto. Es como ver a dos estudiantes brillantes tomar un examen. Uno es un genio que simplemente escribe la elegante respuesta corta. El otro también es brillante, pero te muestra cada paso intermedio, páginas de borrador, múltiples intentos.
Alicia
Mismo resultado, pero un coste muy distinto para llegar allí.
Beto
Muy distinto.
Alicia
Entonces espera un momento. Si se necesitan cuatro veces más tokens para obtener la misma respuesta, ¿eso no anula completamente los ahorros en costes que lograron con la arquitectura DSA?
Beto
Ese es el dilema de despliegue, ¿no? La eficiencia de generar un token es alta, pero la eficiencia de la inteligencia dentro de esos tokens todavía queda rezagada. DeepSeek puede ser tan inteligente, pero tiene que “pensar en voz alta” mucho más, generando muchos más pasos de borrador, lo que cuesta más en tiempo de inferencia para estos problemas realmente difíciles.
Alicia
Así que demostraron que los modelos abiertos pueden ser igual de inteligentes, pero todavía no tan eficientes en ser inteligentes.
Beto
Esa es una forma perfecta de decirlo. Y los propios investigadores reconocen que mejorar la eficiencia de tokens es un foco principal para su trabajo futuro.
Alicia
Pasemos al tercer gran reto que abordaron: las capacidades de agente, conseguir que el modelo realmente use herramientas y generalice esas habilidades.
Beto
Correcto. Y para eso necesitas ingentes cantidades de datos de entrenamiento de alta calidad. No podían simplemente rasparlos.
Alicia
Entonces, ¿qué hicieron?
Beto
Construyeron una increíble canalización de síntesis a gran escala. Generaron automáticamente más de 1,800 entornos distintos y 85,000 prompts complejos. La clave fue que las tareas estaban diseñadas para ser difíciles de resolver, pero fáciles de verificar.
Alicia
¿Dando al IA una retroalimentación realmente clara para el aprendizaje por refuerzo (RL)?
Beto
Exacto. Y estas no eran tareas simples. Mira el ejemplo de planificación de viajes en el artículo. No es solo “reservar un vuelo”.
Alicia
No, es mucho más complejo.
Beto
El agente tiene que manejar restricciones encadenadas y por capas. Por ejemplo, el presupuesto del hotel para el día dos cambia directamente el límite de gasto para los restaurantes ese mismo día. El agente tiene que rastrear esas reglas interconectadas mientras usa sus herramientas.
Alicia
Y las herramientas eran bastante diversas, cubriendo búsqueda, código.
Beto
Muy diversas. Sintetizan agentes de búsqueda a partir de datos web, agentes de código a partir de problemas reales de GitHub y pull requests, y agentes generales diseñados para complejidad pura. Esa amplitud es lo que enseña al modelo a generalizar.
Alicia
Bien, hablemos del proceso interno. Lo llaman “thinking in tool use”. La fuente lo describe como una gran innovación en cómo el modelo maneja su monólogo interno.
Beto
Sí, esto es una solución realmente ingeniosa. Los modelos previos, cuando hacían la tarea multi-paso, tenían que volver a razonar todo el problema desde cero cada vez que recibían un resultado de una herramienta.
Alicia
Lo cual es increíblemente ineficiente.
Beto
Enormemente ineficiente. Así que DeepSync V3.2 tiene un sistema de gestión de contexto más inteligente. Retiene su razonamiento histórico. Está entrenado en cadenas de pensamiento.
Alicia
Cuando solo está recibiendo salidas de herramientas, recuerda lo que estaba pensando mientras espera, digamos, que llegue un resultado de búsqueda.
Beto
Precisamente. Solo descarta ese razonamiento cuando llega un mensaje totalmente nuevo del usuario. Mantiene el flujo de pensamiento y ahorra un montón de tokens.
Alicia
Y los resultados en los benchmarks de agentes son realmente fuertes. Supera a otros modelos abiertos e incluso generaliza a tareas para las que no fue explícitamente entrenado.
Beto
Absolutamente. El rendimiento general es impresionante. El modelo de pensamiento de DeepSync V3.2 obtiene una buena clasificación en Codeforces y una tasa de resolución del 73.1% en el benchmark SWE verificado. Es muy competitivo en flujos de trabajo de desarrolladores.
Alicia
Finalmente, toquemos un experimento práctico interesante que realizaron sobre gestión de contexto. Para esas grandes tareas de búsqueda donde alcanzas el límite de contexto de 128K, probaron varias estrategias.
Beto
Cierto, miraron resumir, descartar 75% y descartar todo. Y el resultado fue fascinantemente contraintuitivo.
Alicia
Realmente lo fue. La mejor estrategia en el benchmark Browsecom fue la más simple: descartar todo.
Beto
Que alcanzó un puntaje de 67.6%.
Alicia
Espera, tirar todo el historial de llamadas a herramientas funcionó mejor. Eso debería ser la peor estrategia. ¿Por qué resetear completamente el contexto sería mejor que resumirlo?
Beto
Porque en este benchmark, el objetivo está en el número total de acciones que puedes realizar. “Descartar todo” libera instantáneamente toda la ventana de contexto.
Alicia
Ah, así que le da al agente más espacio para actuar.
Beto
Exactamente. Puede realizar un mayor número de pasos de ejecución. Tiene más capacidad para intentar algo, fallar y volver a intentarlo. Para estas tareas pesadas en búsquedas, la capacidad de tomar más acciones fue más valiosa que tener una memoria perfecta de cada paso previo.
Alicia
Así que prioriza su presupuesto de tokens para hacer en vez de recordar. Es una gran lección para cualquiera que intente desplegar estos agentes.
Beto
Muestra que el modelo puede regenerar el razonamiento que necesita bastante rápido. Pero lo que absolutamente no puede recuperar es el presupuesto de tokens para la ejecución.
Alicia
Para concluir, a pesar de estos enormes logros, ¿cuáles son las dos limitaciones clave que los autores aún reconocen?
Beto
Primero, el conocimiento del mundo. Aún va un poco por detrás de los líderes propietarios, y eso es simplemente una función de menos FLOPs totales de entrenamiento. Planean escalar eso. Y segundo, como hemos discutido, es la eficiencia en tokens.
Alicia
Puede igualar la calidad del razonamiento, pero a menudo necesita un camino más largo y con más tokens para llegar allí.
Beto
Correcto.
Alicia
Este es un modelo histórico, sin embargo. Deepseek V3.2 ha resuelto ese problema arquitectónico central. Y mediante una inversión masiva y estable en RL post-entrenamiento, ha alcanzado paridad en razonamiento y en capacidades de agente con los gigantes de código cerrado.
Beto
Realmente marca un nuevo hito. Prueba que la innovación arquitectónica, como DSA, combinada con esa computación post-entrenamiento masiva, puede desbloquear rendimiento de frontera en el ámbito abierto. La era en la que los modelos abiertos solo eran “bastante buenos” podría haber terminado. Ahora son genuinamente competitivos.
Alicia
Así que la compensación principal para ti, el oyente, queda clara. Puedes tener paridad de rendimiento, pero por ahora viene a costa de un mayor consumo de tokens en las tareas más complejas.
Beto
Y eso nos lleva a la gran pregunta sobre el futuro del despliegue de IA. Los autores señalan que puedes escalar este cómputo en tiempo de prueba de dos formas. Puedes hacerlo en serie con una gestión de contexto inteligente, como la estrategia “descartar todo”.
O bien, puedes hacerlo en paralelo: muestres muchas intentos independientes baratos y eliges el que funciona mejor.
Alicia
Y eso deja una reflexión provocadora final para llevarte: ¿qué enfoque es la mejor solución a largo plazo para resolver problemas complejos en el mundo real? ¿Debes dedicar tus recursos a un único camino profundo y metódico de pensamiento? ¿O es mejor ejecutar cientos de intentos paralelos baratos y simplemente escoger al ganador? Esa elección estratégica, profundidad serial versus amplitud paralela, va a ser una pregunta crucial para el futuro de la IA.



{kind=link}