
Hoy les traigo otro tema científico reciente e interesante. Han creado grandes modelos de lenguaje (LLMs) aptos para generar código y hacer ingeniería de software. Y lo hacen muy bien, quizás mejor que la mayoría de los ingenieros del mundo. Y en la frontera de estos avances, equipos de agentes autónomos que pueden generar sistemas de aplicaciones completas.
Enlace al artículo, para aquellos interesados en profundizar en el tema: "From Code Foundation Models to Agents and Applications: A Comprehensive Survey and Practical Guide to Code Intelligence". 29 autores incluyendo departamentos de investigación de universidades y compañías privadas. Publicado en Diciembre 3 del 2025.
Este es un artículo larguísimo, y parece más bien un libro. Consta de 304 páginas, y más de 1340 citaciones. Para vuestra conveniencia el artículo ha sido resumido, transcrito y traducido al español, usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos, que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos a un nuevo análisis profundo. Hoy dejaremos de lado el arte generativo y las grandes discusiones filosóficas. Nos vamos a centrar en pura potencia de ingeniería.
Beto
Entrar en las tuercas y tornillos.
Alicia
Exacto. Nos adentramos profundamente en el estado actual de los grandes modelos de lenguaje, específicamente diseñados para el desarrollo de software profesional. Los LLMs para código.
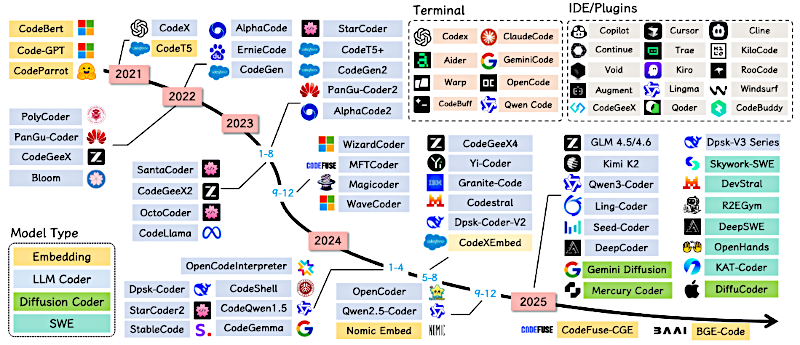
Evolución de LLMs para código
Beto
Sí, y esa es una distinción realmente importante. Quiero decir, tus modelos de propósito general, tus GPT estándar o Claude, son increíblemente poderosos para cosas cotidianas. Pero nuestras fuentes muestran de forma consistente que a menudo carecen de esa profundidad crucial, de la robustez y de la alineación de dominio que realmente necesitas para desarrollo de software profesional.
Alicia
¿Qué significa eso en la práctica?
Beto
Bueno, hablamos de mantener invariantes complejas, esas reglas estrictas en tu sistema que simplemente no pueden romperse, especialmente en bases de datos; o de satisfacer contratos de API muy sutiles y navegar por enormes bases de código con múltiples ficheros. Ese nivel de rigor técnico es exactamente por lo que los LLMs especializados en código se han convertido en su propia categoría.
Alicia
Y la línea de tiempo aquí se mueve a un ritmo salvaje. Quiero decir, estamos viendo fuentes que trazan este progreso desde los primeros modelos de código cerrado en 2018, hasta lo que se espera en 2025. Modelos como GPT-5, Claude 4.5, lo último de GROK; es una hiper-evolución que parece casi exigir especialización para mantener el ritmo.
Beto
Absolutamente. El propio espacio de problemas, la ingeniería de software, está tan altamente constreñido que requiere corrección verificable. Y las recetas de entrenamiento tienen que reflejar eso.
Alicia
Así que esa es nuestra misión hoy. Queremos entrar en la sala de máquinas de la especialización. Queremos entender la salsa secreta, ¿verdad?
Los enormes datos curados con los que se entrenan estos modelos, los trucos arquitectónicos únicos que los hacen tan rápidos y eficientes para código, y qué pueden hacer realmente hoy con retos de ingeniería del mundo real. Bien, desempacemos esto.
Probablemente deberíamos comenzar por la base, el combustible de todo esto: los enormes conjuntos de datos de código. Pero parece que la industria ha avanzado más allá de los simples volúmenes gigantes de datos.
Beto
Oh, absolutamente. Ese es el cambio crítico. El recurso más influyente aquí es la familia de conjuntos de datos, el Stack. Proviene de la gran colaboración de código.
Alicia
El Stack, OK.
Beto
Y realmente representa esa comprensión a nivel industria de que la calidad y la gobernanza importan mucho más que la pura cantidad, especialmente cuando trabajas con código.
Alicia
Y hemos visto un escalado serio aquí. El Stack original V1 ya era enorme, 3.1 terabytes.
Beto
Fue impresionante, sí. Código con licencia permisiva a través de cientos de lenguajes. Pero V2 está en otro nivel.
Alicia
Es casi 10 veces más grande.
Beto
Es enorme. El Stack V2 son 32.1 terabytes y cubre más de 600 lenguajes. Pero quizás lo que importa más que la escala es el proceso de gobernanza detrás.
Alicia
¿A qué te refieres con gobernanza?
Beto
Incluye higiene de datos rigurosa como deduplicación avanzada, para que el modelo no memorice simplemente código. Y, de forma crítica, hay un proceso formal y transparente de exclusión (opt-out).
Alicia
Para que los propietarios de repositorios puedan decir: "oye, no uses mi código".
Beto
Exacto. Y ese nivel de curación debe ser una pesadilla operacional masiva. Pero es esencial para generar confianza. Y, francamente, para asegurar la corrección de esa base de entrenamiento.
Alicia
Tiene mucho sentido. Si entrenas con código defectuoso o redundante, simplemente estás horneando esos errores en el modelo final.
Beto
Directamente en el producto final.
Alicia
Bien, pasemos de los datos al silicio, a la arquitectura.
¿Qué características especializadas se incorporan a estos LLMs de código antes del ajuste fino que les dan ventaja?
Beto
Bueno, los modelos de código usan objetivos de preentrenamiento especializados. Van mucho más allá de la simple predicción de tokens siguiente.
Una de las técnicas clave se llama "fill-in-the-middle", o FIM. Se ve en muchos modelos como StarCoder.
Alicia
Fill-in-the-middle. Así que en lugar de solo completar una línea de código, ...
Beto
... se le enseña a predecir un fragmento faltante de código usando contexto tanto de lo que viene antes, el prefijo, como de lo que viene después, el sufijo, al mismo tiempo.
Alicia
Ah, entonces está mirando hacia adelante y hacia atrás en el archivo. Eso parece esencial para la edición de código, ¿no? Bueno, estás cambiando el cuerpo de una función pero dejando todo lo demás intacto.
Beto
Exactamente. Potencia enormemente su capacidad para hacer un relleno ("in-filling"), que es pan de cada día para cualquier asistente de editor de código ("Integrated Development Environment", IDE).
Alicia
¿Qué más?
Beto
También está la predicción de múltiples tokens, ("Multi-Token Prediction", o MTP), donde predice varios tokens a la vez para una mejor coherencia. Y ahora vemos cosas de vanguardia con difusión para código en el entrenamiento.
Alicia
OK. Tenemos que parar en difusión un segundo. La asociamos mayormente con generación de imágenes, ese proceso iterativo de remover el ruido. ¿Cómo se aplica eso al código?
Beto
Todo va de control y diversidad. ¿Sabes cómo un modelo estándar genera código token por token?
Alicia
Sí. Puede quedarse atascado en un camino extraño desde el principio.
Beto
Exacto. El entrenamiento por difusión toma un trozo de código ruidoso o incompleto y luego lo refina iterativamente paso a paso. Esto permite que el modelo coordine mejor la estructura global de la salida.
Alicia
Así obtienes más control sobre la estructura final y probablemente evitas esos ciclos repetitivos raros que a veces ves.
Beto
Esa es la idea. Es una dirección muy prometedora.
Alicia
Aquí es donde el ingeniero se vuelve realmente estratégico, ¿verdad? El movimiento hacia "mezcla de expertos" ("Mixtures of Experts" o arquitecturas MoE), lo hemos visto en todas partes.
Beto
Seguro. La serie DeepSeek es un gran ejemplo en el espacio de código open source, especialmente la V3.2. Su versión tiene este nuevo mecanismo de atención dispersa ("DeepSeek Sparse Attention", DSA).
Alicia
Y la afirmación es bastante grande.
Beto
Lo es. Dicen que reduce el coste de inferencia para entradas largas en un 50%. Y para una audiencia profesional, eso es extremadamente estratégico.
Alicia
Explícame eso. ¿Por qué un recorte del 50% en costes es tan estratégico? Es más que ahorrar algunas monedas en la factura de la nube, supongo.
Beto
Oh, mucho más. Cuando tratas de lograr comprensión a nivel repositorio, tu ventana de contexto puede tener cientos de miles de tokens.
Alicia
Todo el proyecto.
Beto
Claro. Reducir a la mitad el coste de procesarlo hace que la operación en tiempo real sea económicamente viable a escala. Significa que tu asistente de IDE, como el construido sobre Claude 4.5 Sonnet, que mostró grandes mejoras en edición multi-archivo, puede usar ese contexto masivo sin arruinar a la empresa o tardar minutos.
Alicia
Bien, así que esa arquitectura especializada es lo que realmente hace posibles las herramientas comerciales.
Beto
Es lo que sustenta toda la comercialización de los LLMs de código.
Alicia
Eso deja clara la tendencia de especialización. Entonces, si la arquitectura nos da la potencia para parsear y generar código eficientemente, ¿cómo le enseñamos a entender la intención humana y la corrección?
Beto
Bien. Eso nos lleva a la alineación. La segunda fase mayor.
Alicia
El entrenamiento de alineación.
Beto
Exactamente. Aquí es donde adaptas el modelo a instrucciones humanas. Comienza con fine-tuning supervisado ("Supervised Fine-Tuning", o SFT). Y desde el principio, los LLMs de código especializados que se entrenan así tienden a superar a los modelos generales en cosas como la autocompletación de código.
Alicia
Pero SFT ha tenido problemas serios de integridad, ¿no? Las fuentes que leí apuntaron a dos grandes problemas. Filtración de datos y sesgo por complejidad de tareas.
Beto
Son problemas extremadamente serios, sobre todo porque conducen a una falsa sensación de confianza.
Alicia
¿Qué es exactamente la filtración de datos?
Beto
Es la contaminación del conjunto de pruebas. El modelo ha visto las respuestas a las preguntas del benchmark durante su entrenamiento. Así que su rendimiento parece increíble, pero desaparece en el mundo real.
Alicia
¿Y el sesgo por complejidad de tareas?
Beto
Ahí es donde los conjuntos de datos SFT están inundados de tareas simples de completar función. Entonces el modelo se vuelve genial en problemas cortos y fáciles, pero se desmorona completamente cuando le pides diseñar un sistema multiarchivo.
Alicia
¿Cómo están luchando los investigadores contra eso? Vi menciones de usar un LLM para juzgar a otro LLM.
Beto
Sí, esos jueces LLM.
Alicia
Pero ¿no introduce eso otra capa de sesgo potencial?
Beto
Es un punto válido. Pero los nuevos métodos sofisticados se enfocan en detectar solapamientos semánticos, no solo copias exactas. Intentan ver si dos problemas son conceptualmente idénticos, incluso si aparecen redactados de forma diferente.
Alicia
Eso suena computacionalmente caro.
Beto
Lo es. Pero ese rigor es lo necesario para crear benchmarks que realmente prueben la capacidad de razonamiento genuino.
Alicia
Y el razonamiento genuino, parece ser el gran cambio de paradigma aquí. La principal herramienta del modelo para resolver problemas complejos ahora es el propio código.
Beto
Eso es. Nos movemos hacia métodos basados en razonamiento como "cadena de pensamiento ("Chain-of-Thought", CoT) y, aún más efectivamente, los "Modelos de Lenguaje Ayudados por Programa" ("Program-Aided Language Models", o PAL).
Alicia
Con PAL, no pides la respuesta final.
Beto
No. Induces al modelo a generar una serie de pasos ejecutables, normalmente código Python, que te lleven a la respuesta.
Alicia
Así que el modelo básicamente escribe un pequeño programa para resolver el problema meta. Ejecuta ese programa en un intérprete, verifica el resultado y luego genera la solución final.
Beto
Exacto. Es un movimiento crucial porque descarga la lógica compleja y las matemáticas fuera de la red interna no determinista del LLM y las pone en un entorno externo verificable.
Alicia
Y eso le permite autocorregirse.
Beto
Eso le permite autocorregirse con retroalimentación de ejecución. Ese es el salto de la fluidez a la corrección.
Alicia
Y este enfoque en la corrección verificable nos lleva a lo que llamaste la cima de la alineación: el "Aprendizaje por Refuerzo con Recompensas Verificables" ("Reinforcement Learning with Verifiable Rewards", RLVR).
Beto
RLVR es un punto de inflexión crítico.
Alicia
Esto suena como la salsa secreta para conseguir que un modelo sea un ingeniero realmente fiable.
Beto
Así es. Porque optimiza el modelo directamente para una métrica de éxito binaria: el código tiene que ejecutarse y pasar todas las pruebas unitarias.
Alicia
Así que no se trata solo de imitar una solución bien escrita que vio durante el entrenamiento.
Beto
No. La señal de recompensa pasa de algo subjetivo — "¿esto parece bueno?" — a algo objetivo — "¿pasó la prueba?" Sí o no.
Alicia
Y eso requiere conjuntos de datos totalmente nuevos.
Beto
Totalmente. Las fuentes apuntan a cosas como AceCoder-87K, que tiene 87K problemas emparejados explícitamente con casos de prueba automatizados. Proporciona una señal de recompensa clara y sin ambigüedad. Otro, KodCode, se concentra en temas diversos y verificabilidad. Este ciclo de retroalimentación estructurado es cómo los modelos finalmente aprenden a manejar casos límite de forma fiable.
Alicia
Entonces, si cuentas con estas arquitecturas optimizadas y esta alineación impulsada por "Aprendizaje por Refuerzo" ("Reinforcement Learning", RL), ¿cómo se ve realmente en el mundo? ¿Dónde los desarrolladores profesionales están viendo estas capacidades?
Beto
La especialización ahora aparece en tareas realmente complejas que los LLMs tradicionales simplemente no podían manejar. Estamos viendo un rendimiento sólido en comprensión a nivel repositorio.
Alicia
Es decir, completado o refactorización que necesita contexto de múltiples ficheros.
Beto
Múltiples ficheros, dependencias del proyecto, estructura interna, todo el paquete. El modelo tiene que básicamente entender todo el grafo del proyecto.
Alicia
Para que sepa cómo una función utilitaria en un archivo está siendo llamada por una ruta de API en otro y cómo ambos se relacionan con un esquema de base de datos en un tercer archivo.
Beto
Exactamente, el desafío que nuevos benchmarks como RepoEval y CrossCodeEval están diseñados para probar. También lo estamos viendo en aplicaciones multimodales.
Alicia
Generar código a partir de algo que no sea texto.
Beto
Correcto. Generación de interfaces front-end: le das una captura de pantalla de un sitio web y genera un componente React funcional. O generar código boilerplate directamente a partir de un diagrama UML.
Alicia
Pero incluso con todo este progreso, las fuentes dicen que los LLMs generales todavía flojean en tareas de ingeniería largas y multi-paso. Hablan de razonamiento frágil en horizontes largos y de alucinaciones con herramientas.
Beto
Y esa fragilidad es exactamente por lo que necesitamos agentes. Un LLM independiente podría decidir usar un comando git, pero luego inventa una bandera de línea de comandos que no existe.
Alicia
O simplemente se inventa un mensaje de éxito sin haber comprobado nunca el estado del repositorio.
Beto
Precisamente. La solución son agentes de software, que son sistemas que envuelven al LLM con lógica de planificación, ejecución y verificación.
Alicia
Bien, desgranemos los dos diseños principales de agentes que estamos viendo.
Beto
Primero, tienes tus sistemas de agente único. Un buen ejemplo es AlphaCode 2. Es un LLM potente que mejora iterativamente su propio trabajo mediante autorreflexión y re-prompting.
Alicia
Simple y con menor sobrecarga.
Beto
Cierto. Favorece la iteración rápida.
Pero luego tienes el enfoque colaborativo más robusto ...
Alicia
... la tubería de agentes múltiples.
Beto
Y estos sistemas simulan todo un equipo de desarrollo. Frameworks como MetaGPT o ChatDev asignan roles especializados.
Alicia
Como un CEO para la planificación, un programador, un tester.
Beto
Exacto. Esta división del trabajo fortalece la modularidad y minimiza el riesgo de un único punto de fallo o de que una sola alucinación descarrile todo el proceso.
Alicia
Vamos a cerrar con las herramientas comerciales. Las que los desarrolladores usan cada día. Tenemos que empezar con GitHub Copilot.
Beto
Sigue siendo el referente. Copilot procesa algo así como 150 millones de sugerencias de código cada día. Ahora es una potencia multi-modelo.
Alicia
Cierto. Ya no es solo un modelo.
Beto
No, podría por defecto usar algo como GPT-4.5. Pero los usuarios premium pueden acceder a modelos de vanguardia como Claude 4.5 Sonnet o GPT-5. Y, de forma crucial, ha ido mucho más allá de la simple finalización. Funciones como Copilot Edits para refactorización multiarchivo lo colocan firmemente en esa categoría de uso profesional.
Alicia
Y las cifras son enormes. Copilot supuestamente generó alrededor de 500 millones de dólares en ingresos en 2024.
Pero la competencia de herramientas como Cursor se está poniendo realmente intensa.
Beto
Cursor es una historia fascinante. Es un fork de VS Code, pero diseñado desde cero para ser primero-IA ("AI-first"). Realmente crearon funciones como "modo compositor" ("Composer Mode"), ...
Alicia
... que te deja describir cambios a nivel de proyecto en lenguaje natural.
Beto
Correcto. Habilitando refactors complejos que antes eran imposibles. Cambia radicalmente el flujo de trabajo de ser reactivo — aceptar una sugerencia — a ser proactivo y hacer cambios holísticos del sistema.
Alicia
Y puede hacerlo porque gestiona el contexto muy bien, hasta 200,000 tokens.
Beto
Exacto. Resuelve ese problema de comprensión a nivel de repositorio del que hablamos. Y demostró que el modelo funciona. Alcanzaron 500 millones de dólares en ingresos anuales en solo dos años. Es increíble.
Alicia
Y, por último, tienes a Tabnine, que ha tallado un nicho muy potente alrededor de seguridad y privacidad.
Beto
La estrategia entera de Tabnine está construida sobre la gobernanza. Solo entrenan con código con licencia permisiva— MIT, Apache, BSD — lo que elimina completamente el riesgo de propiedad intelectual. Y, más importante para grandes empresas, se especializan en despliegues on-premises y locales.
Alicia
Todo queda detrás del firewall corporativo.
Beto
Obtienes soberanía total sobre los datos. Quizá sacrifiques las funciones más punteras de un Copilot respaldado por GPT-5, pero ganas seguridad total. Para industrias reguladas, es un intercambio no negociable.
Alicia
Ese análisis realmente nos devuelve al círculo completo. Hemos ido de modelos de lenguaje generales hasta estos LLMs de código hiper-especializados, impulsados por datos curados, optimizados por arquitecturas MoE y alineados mediante retroalimentación de ejecución.
Beto
Es una historia increíble de especialización de ingeniería. La industria ha dado pasos monumentales para resolver problemas complejos dentro de un sistema cerrado y verificable: la base de código misma.
Alicia
Correcto. Pero con todo eso, hay un reto mayor que sigue siendo frustrantemente fuera de alcance. A pesar de todo este progreso increíble en codificación, nuestras fuentes muestran que los benchmarks más rigurosos, los que se centran en tareas interactivas sin restricciones a escala web — como los benchmarks de búsqueda web — aún reportan tasas de éxito cercanas a cero, incluso para los mejores modelos.
Beto
Lo que nos lleva a la pregunta definitiva para que la pienses.
Alicia
Si estos LLMs ya son lo suficientemente sofisticados como para escribir, depurar y verificar de forma fiable software perfecto y multiarchivo, ¿por qué el acto aparentemente simple de navegar y lograr un objetivo complejo en la web abierta, ruidosa y caótica sigue siendo un problema importante sin resolver?
Beto
¿Y qué avance fundamental y específico será necesario para finalmente cerrar esa brecha entre el mundo controlado de una base de código y el mundo caótico abierto del razonamiento?



{kind=link}