
Uno de los campos profesionales donde se aplica la Inteligencia Artificial (IA) es la Medicina. El siguiente es un resumen de un artículo científico que lista los modelos multimodales aplicados a la medicina, y los enfoca desde el punto de vista de la tecnología, sus aplicaciones y los desafíos a los que se encuentran.
Enlace al artículo, para aquellos que quieran profundizar en el tema: "Multimodal Large Language Models for Medicine: A Comprehensive Survey", por Jiarui Ye y Hao Tang. Publicado el 29 de Abril del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos a un nuevo análisis profundo. El programa donde abordamos algunos de los temas más complejos y de rápida evolución. Extraemos los conocimientos más importantes para que puedas estar instantáneamente bien informado.
Hoy nos centramos en una de las áreas de innovación con más carga: la integración de la IA en la medicina. Específicamente, hacemos una inmersión profunda en los modelos de lenguaje grandes multimodales, o MLLMs. Y nuestro material fuente para esto es una enorme síntesis. Hablamos de más de 330 artículos de investigación recientes.
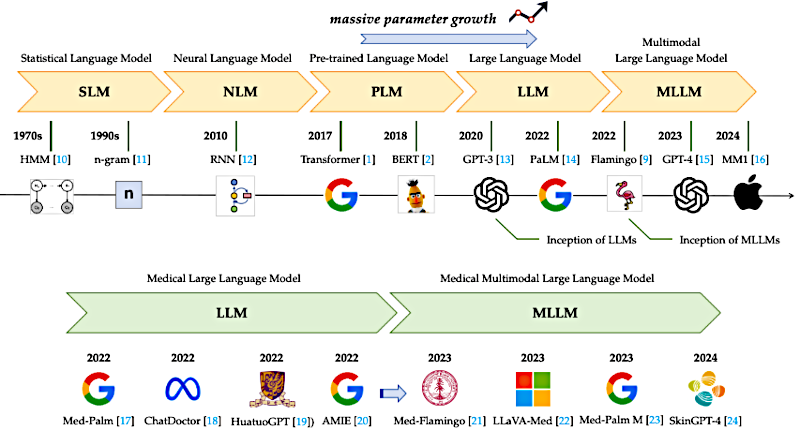
Beto
Correcto. Y nuestra misión hoy es realmente ir más allá del bombo general. Ya sabes, se oye todo el tiempo sobre modelos solo de texto como GPT‑4. Pero necesitamos enfocarnos en los MLLMs porque, francamente, son el siguiente paso necesario para cualquier uso clínico real.
Alicia
¿Por qué? ¿Por qué lo multimodal es la clave?
Beto
Porque la propia medicina es multimodal. Un médico maneja imágenes, texto, audio, vídeos quirúrgicos, marcadores genéticos, todo eso. Y un LLM, por sí solo, solo maneja texto. Un médico trata con la realidad.
Alicia
Precisamente. Así que hoy vamos a desglosar tres áreas centrales. Primero la tecnología: cómo es posible esa integración multimodal.
Luego las principales aplicaciones clínicas que existen ahora.
Beto
Por ejemplo, generar informes, cirugía, ese tipo de cosas.
Alicia
Exacto. Y, lo más crítico, los desafíos inmediatos que estos modelos deben superar antes de que puedan ser confiables en un entorno clínico real.
Bien, empecemos por la base. Todos más o menos conocemos la historia ahora. Los modelos modernos de lenguaje realmente despegaron con la arquitectura "transformer", allá por 2017. Esa innovación, el mecanismo de "self‑attention", llevó a los enormes modelos de texto que conocemos, como la serie GPT.
Beto
Y esos modelos de texto fueron revolucionarios. Pero lo fascinante es lo rápido que el campo médico se dio cuenta de que tenían que pivotar.
Alicia
¿Por qué? ¿Porque el texto no es suficiente?
Beto
Ni de lejos. Los LLMs son excelentes resumiendo historias clínicas o redactando notas de paciente. Pero la atención sanitaria se trata fundamentalmente de correlacionar múltiples tipos de datos al mismo tiempo.
Alicia
Exacto, un cardiólogo no solo está leyendo notas.
Beto
Exacto. Está mirando notas textuales, sí, pero también lecturas de ECG, vídeos de ecografía, quizá incluso secuencias genómicas. Para ayudar realmente en una tarea compleja, el sistema tiene que combinar todo eso.
Alicia
Eso suena como un desafío técnico enorme. Quiero decir, si tienes datos que vienen de un escáner CT de alta resolución, que es visual, y del historial de texto de un paciente, ¿cómo hace el sistema para que se comuniquen entre sí? ¿No se pierde algo?
Beto
Ese fue el salto crítico que los LLMs tuvieron que resolver. Y la arquitectura central es en realidad bastante elegante. Usa el LLM como el cerebro, la parte central de razonamiento. Pero los datos no van directamente al cerebro. Primero tienes estos codificadores especializados por modalidad. Toman la entrada cruda — una radiografía, un archivo de audio — y extraen las características clave.
Alicia
Y luego viene la parte mágica.
Beto
Viene un módulo crucial llamado "módulo de alineamiento".
Alicia
¿Qué hace en realidad el módulo de alineamiento?
Beto
Piénsalo como un traductor universal. Toma esas características no textuales de los codificadores y las convierte al lenguaje conceptual que el LLM entiende.
Alicia
¿Entonces convierte la imagen de un tumor en algo que el cerebro basado en texto puede procesar?
Beto
Perfectamente dicho. Traduce esa información visual en vectores de embedding que corresponden a conceptos textuales. Así, ahora el LLM puede procesar esa imagen del tumor junto con un informe de biopsia escrito.
Alicia
Esa explicación estructural realmente ayuda. Nos da la base. Ahora vayamos al “y qué”. ¿Cómo se está usando esta tecnología en la práctica? Encontramos tres aplicaciones principales, empezando por la documentación.
Beto
Bien. La primera y probablemente la más adoptada es la generación de informes médicos.
Alicia
Esto ahorra una enorme cantidad de tiempo a los doctores.
Beto
Muchísimo. Profesionales altamente cualificados como los radiólogos pasan horas cada día redactando informes detallados basados en rayos X, TACs, resonancias. La esperanza con la IA es reducir ese tiempo y disminuir errores sencillos.
Alicia
La investigación da un gran ejemplo: XrayGPT. ¿Puedes explicarnos cómo funciona ese y, quizá más importante, dónde falla?
Beto
Claro. XrayGPT toma la imagen, extrae características con un codificador visual y luego ese módulo de alineamiento que comentamos pasa esas características al LLM médico.
Alicia
Y entonces le haces preguntas.
Beto
Le haces una pregunta del tipo: “¿Cuáles son los hallazgos principales y las impresiones de esta radiografía?” y genera un informe.
Alicia
Pero aquí está la parte crucial. Los informes médicos tienen una estructura lógica muy estricta. Tienes los hallazgos, las observaciones objetivas, y luego la impresión, que es el resumen final.
Beto
Exacto. Y esto es un enorme reto clínico destacado en la investigación. Estos LLMs suelen sacar puntuaciones muy altas en benchmarks. Pasan el examen. Pero funcionan mal en el mundo real. Y es porque se vuelven muy buenos generando una impresión que suena plausible pero les falta la habilidad inferencial profunda para conectarla lógicamente con los hallazgos.
Alicia
Pueden listar observaciones, pero no pueden realmente diagnosticar la enfermedad.
Beto
Es una gran analogía: es la diferencia entre memorización y razonamiento verdadero. Y esa incapacidad para conectar los puntos es una preocupación de seguridad enorme.
Alicia
Bien, eso es eficiencia.
La segunda aplicación que abordamos es algo más suave: la atención al paciente.
Beto
Se trata de comunicación médica profesional y compasiva. Todos sabemos que los chatbots solo de texto fracasaron bastante aquí.
Alicia
La brecha de empatía.
Beto
Exacto. Los pacientes necesitan sentirse comprendidos, no simplemente procesados por una máquina.
Alicia
Y los LLM intentan arreglar eso incorporando todos esos datos no textuales que un médico humano captaría de forma natural en una habitación.
Beto
Precisamente. Si un paciente escribe un mensaje de texto, perfecto, un sistema solo de texto no tiene forma de saber si es genuino o sarcástico. Un LLM multimodal puede entrenarse para analizar movimiento facial, lenguaje corporal, seguimiento ocular, incluso el ritmo y el tono de la voz. Así, sistemas como ChatDoctor o LLaVA-Med pueden obtener una imagen mucho más precisa del estado real del paciente.
Alicia
Nuestra tercera aplicación va a un entorno de muy alta responsabilidad: el quirófano. Hablamos de asistencia clínica en cirugía.
Beto
Modelos como SurgicalGPT se están desarrollando para responder a preguntas rápidas basadas en vídeo quirúrgico en vivo. Se llama "Visual Question Answering" (VQA).
Alicia
La idea de una IA que observa un procedimiento y da análisis en tiempo real es revolucionaria.
Beto
Lo es, pero la limitación aquí es importante y, francamente, plantea banderas de seguridad inmediatas.
Alicia
Si pasan por alto detalles claves en radiología, ¿qué pueden estar perdiendo en cirugía?
Beto
Los modelos VQA quirúrgicos actuales tienden a centrarse solo en el área inmediata de la enfermedad, el órgano objetivo.
Alicia
Así que tienen visión de túnel.
Beto
Visión de túnel total. Con frecuencia pasan por alto información de fondo crucial, como el movimiento de una herramienta quirúrgica, el estado operativo general o signos de sangrado justo fuera de su foco principal.
Alicia
Y pasar por alto el movimiento de instrumentos en un quirófano es un riesgo inaceptable. Conduce a una comprensión defectuosa del procedimiento y podría causar un error catastrófico.
Entonces, si estos MLLMs son el motor, el combustible debe ser una diversidad increíble de datos médicos. Entremos en las seis modalidades principales que deben dominar, empezando por los clásicos.
Beto
Comenzamos con imágenes radiológicas: resonancias magnéticas para tejido blando, las radiografías estándar y luego los TACs.
Alicia
Y los TACs son particularmente complicados, leí.
Beto
Son muy desafiantes. Te dan estas hermosas secciones transversales en alta resolución de la anatomía, pero la pura dimensionalidad de esos datos — estás tratando con espacio 3D — crea enormes problemas de estabilidad y precisión para los modelos.
Alicia
A continuación, imágenes fotográficas. Esto es más directo, ¿no?
Beto
En parte. Son visuales de dispositivos ópticos: imágenes de dermatología de la piel, imágenes de oftalmología del ojo, o imágenes de endoscopia de, por ejemplo, pólipos en el recto. ChatGPT4 es un buen ejemplo aquí.
Alicia
Luego hay una que me pareció muy interesante: datos de audio. Es más que conversación.
Beto
Mucho más. Incluye sonidos que realmente transmiten estado de salud. La investigación menciona un modelo llamado RespLLM.
Alicia
¿Qué hace eso?
Beto
Convierte sonidos como toses y patrones respiratorios en espectrogramas para predecir la salud respiratoria general. Y en algo como la consulta psicológica, el tono y el tempo de la voz del paciente son puntos de datos críticos.
Alicia
Para la medicina personalizada, tenemos que hablar de todos los datos ómicos. Esto es la información de plano, ¿no?
Beto
Es el genoma, el proteoma, el transcriptoma, todos los datos moleculares complejos que determinan cómo funciona tu cuerpo. Es absolutamente crucial para la medicina personalizada, pero es increíblemente difícil de integrar con otros datos clínicos.
Alicia
Y, por supuesto, finalmente está el dato textual: la base.
Beto
Historias clínicas electrónicas, informes médicos detallados, enormes conjuntos de diálogo como MedDialog, y por supuesto toda la literatura científica para razonamiento basado en evidencia.
Alicia
Dicho todo esto, pensarías que los MLLMs tienen material de entrenamiento sin límite. Pero nos topamos de frente con lo que la investigación llama "la paradoja de la escasez".
Beto
Los datos médicos son en realidad increíblemente escasos.
Alicia
¿Por restricciones legales, éticas y de privacidad?
Beto
Exacto. Cosas como la Ley de Portabilidad y Responsabilidad del Seguro Médico ("Health Insurance Portability and Accountability Act", HIPAA) limitan severamente el acceso. Esto realmente daña el rendimiento del modelo, especialmente para enfermedades raras donde simplemente no hay conjuntos de datos públicos grandes con los que entrenar.
Alicia
Así que esta escasez obliga a la industria a ponerse creativa.
Beto
Muy creativa. La atacan por dos frentes. Primero, soluciones basadas en el modelo: en lugar de exigir más datos, afinarán un modelo potente existente — por ejemplo convertir "PaLM" en "Med-PaLM" —. Se concentran en potenciar sus habilidades inferenciales para que dependa menos de la memorización de datos.
Alicia
Y la segunda solución es, creo, aún más fascinante: la augmentación basada en datos. Si no puedes obtener los datos, los fabricas.
Beto
Generas datos sintéticos de alta calidad. Por ejemplo, los investigadores usan modelos como GPT‑4 para crear preguntas y respuestas basadas en libros de texto médicos. O generan leyendas detalladas y formateadas para imágenes públicas existentes.
Alicia
Básicamente construyen su propio currículo de entrenamiento de alta calidad ...
Beto
... desde cero para sortear las barreras regulatorias. Es una solución ingeniosa.
Alicia
Esto nos lleva a lo que podría ser la sección más crítica. Porque por muy ingeniosa que sea la tecnología, estos modelos tienen que cumplir los estándares más altos antes de tocar una vida humana.
Beto
Correcto. Debemos hablar de profesionalismo, seguridad y equidad.
Alicia
Empecemos con el Desafío Uno: Profesionalismo. El modelo tiene que pensar y hablar como un especialista. ¿Cómo medimos eso?
Beto
Bueno, hay dos formas principales. Una es la valoración manual por expertos, donde médicos humanos puntúan las salidas del modelo en cosas como exactitud y utilidad.
Alicia
Y la otra es hacer que tomen exámenes profesionales.
Beto
Correcto. Hacemos que los modelos se presenten a evaluaciones profesionales como el Examen para la Licencia Médica de los EE.UU. ("United States Medical Licensing Examination,", USMLE).
Alicia
Y las puntuaciones son impresionantes, ¿no? Vi que GPT‑4 y Med-PALM obtienen más del 86% de acierto.
Beto
Las cifras suenan increíbles, pero aquí está el punto clave al que volvemos una y otra vez.
Alicia
Si obtuvieron 86% en los exámenes médicos, ¿por qué siguen fallando en la clínica? ¿Cuál es la desconexión?
Beto
La desconexión es la inferencia. Las altas puntuaciones muestran competencia y recuerdo. Han memorizado mucha información. Pero la práctica clínica real exige inferencia profunda: aplicar el conocimiento a una situación de paciente completamente nueva y dinámica.
Alicia
Así que conoce el libro de texto, pero no puede manejar el mundo real.
Beto
Precisamente. Y la falta de ese razonamiento profundo es una falla persistente. Incluso están recurriendo a construir diccionarios especializados solo para evitar que los modelos cometan errores básicos, como dividir la palabra “cardiomegalia” en partes...
Alicia
Desafío Dos posiblemente sea el mayor destructor de confianza: las alucinaciones. El modelo simplemente genera información que suena plausible pero está completamente fabricada. Puede sonar totalmente confiado mientras está peligrosamente equivocado.
Beto
Este es el obstáculo principal para la credibilidad. En los MLLMs a menudo aparece como una mala identificación, especialmente con imágenes. La investigación las clasifica como "alucinaciones de tipo, propiedad o relación".
Alicia
¿Un ejemplo?
Beto
Piensa en el ejemplo quirúrgico: el modelo ve una herramienta en una herida. Podría apoyarse en un estereotipo aprendido sobre la relación entre esa herramienta y ese tipo de herida. Prioriza su patrón aprendido sobre los datos visuales únicos que está viendo.
Alicia
Está viendo lo que espera ver, no lo que realmente hay. ¿Cómo se arregla eso?
Beto
Se pueden usar soluciones técnicas como la segmentación de imágenes: fuerzas al modelo a concentrarse en las partes clave de la imagen, lo que evita suposiciones generales. O se construyen estructuras de auto‑verificación donde tiene que contrastar su salida con los datos fuente antes de dar una respuesta.
Alicia
Y el último desafío es la equidad y el sesgo. Esto es enorme. La IA es tan buena como los datos con los que se entrena.
Beto
Si esos datos están sesgados, el consejo clínico estará sesgado. El desequilibrio en los datos y los prejuicios sociales incrustados pueden influir gravemente en los resultados.
Alicia
¿Qué encontró la investigación?
Beto
Citó ejemplos de modelos que predicen mayores costes o estancias hospitalarias más largas para poblaciones blancas, o reducen las tasas de tratamiento para grupos minoritarios, todo por estereotipos incrustados en los datos de entrenamiento.
Alicia
¿Es discriminación algorítmica?
Beto
Eso es exactamente lo que es. Y debe abordarse de forma proactiva. Se puede hacer a nivel de datos filtrando o remuestreando, y a nivel de modelo usando cosas como aprendizaje por refuerzo a partir de la retroalimentación humana ("Reinforcement Learning from Human Feedback", RLHF) ...
Alicia
... para alinearlo con valores humanos.
Beto
Para alinearlo con los valores médicos y éticos humanos, sí. Un sentido de empatía reforzado.
Alicia
Ha sido una inmersión realmente fascinante. Está claro que los MLLMs prometen un futuro de atención sanitaria de bajo coste y alta eficiencia. Es un verdadero cambio de paradigma.
Beto
La promesa es enorme. Pero como hemos dicho, el desafío del mundo real que une todo esto es el despliegue. Irónicamente, las regiones que más necesitan esta tecnología — lugares con pocos especialistas y recursos médicos escasos — a menudo carecen de la infraestructura técnica masiva para ejecutar estos modelos.
Alicia
Son simplemente demasiado grandes y consumidores de energía.
Beto
Exacto. Así que para ti, el aprendiz, la idea clave a mantener es esta: el futuro de la IA equitativa en medicina no es solo hacer modelos más inteligentes. Es hacerlos más pequeños.
Alicia
El imperativo moral definitivo es crear soluciones ligeras.
Beto
De verdad. Hablamos de técnicas como LoRA y QLoRA, que permiten a los desarrolladores congelar la mayor parte de un modelo enorme y ajustar solo una fracción mínima.
Alicia
¿Qué hace eso en la práctica?
Beto
Reduce drásticamente la carga de cómputo. Permite el despliegue en el borde, ejecutar estos complejos MLLMs directamente en un smartphone o un dispositivo wearable. Así es como se asegura que los beneficios de esta medicina de alta tecnología lleguen realmente a los lugares con mayores carencias.
Alicia
Por tanto, la optimización técnica no es solo un problema de ingeniería.
Beto
En este campo, la optimización técnica es un imperativo moral.



{kind=link}