
El Informe Técnico del Premio ARC 2025 detalla el progreso y las metodologías utilizadas para resolver el punto de referencia ARC-AGI-2, un conjunto de datos diseñado para medir la inteligencia artificial general a través de nuevas tareas de razonamiento. Una de las principales conclusiones de la competencia es el auge de los ciclos de refinamiento, que permiten a los sistemas mejorar iterativamente sus respuestas mediante entrenamiento en tiempo de prueba o síntesis de programas evolutivos. Las soluciones de mayor rendimiento incluyeron NVARC, que alcanzó una precisión del 24%, y el Tiny Recursive Model, que demostró que las redes pequeñas de 7 millones de parámetros pueden realizar razonamientos complejos. A pesar de estos avances, el informe señala que la IA actual sigue limitada por la cobertura del conocimiento, lo que lleva a un nuevo tipo de contaminación del punto de referencia donde los modelos se basan en la exposición previa a datos en lugar de la lógica pura. Para abordar estas limitaciones, los organizadores anunciaron ARC-AGI-3, que introducirá entornos interactivos para la planificación y la memoria de pruebas. En último término, el informe enfatiza que para lograr una verdadera inteligencia fluida es necesario ir más allá de la correspondencia de patrones estáticos hacia una adaptación eficiente y autónoma.
Enlace al articulo cientifico, para aquellos interesados en profundizar en el tema: . Por François Chollet y colegas. Publicado el 19 de Enero del 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos a un nuevo análisis profundo. Hoy es Martes 20 de Enero del 2026. Y mira, si te has sentido un poco abrumado por el ciclo de exageración de la IA, ...
Beto
Solo un poco.
Alicia
Ya sabes cómo va: Cada semana aparece un nuevo modelo que supuestamente desafía las leyes de la física. Hoy vamos a aterrizar un poco porque ayer se publicó el informe técnico del premio ARC 2025.
Beto
Por fin. Estuve refrescando mi feed todo el fin de semana por esto.
Alicia
Y para quien no lo sepa, esto no es solo otro comunicado de prensa de un gigante tecnológico. Esto es, no sé, ¿cómo llamarlo? ¿El control de realidad anual?
Beto
Eso es exactamente. Es la auditoría. Es el momento en que dejamos de mirar las demos brillantes y realmente, ya sabes, abrimos el capó para ver si el motor está funcionando. Y sinceramente, el informe de este año quizá sea el documento más importante que hemos visto en los últimos cinco años de IA.
Alicia
Grandes afirmaciones desde el principio. Pero la misión del análisis profundo es desglosar exactamente por qué. Porque el número principal, la gran cifra de 2025, es impactante. Pero antes de llegar ahí, tenemos que definir el problema. Quiero decir, tenemos Gemini 3. Tenemos Claude Opus 4.5.
Beto
Herramientas increíbles.
Alicia
Pero la pregunta que plantea este informe es: ¿están pensando?
Beto
Correcto. Y hay una diferencia enorme entre conocimiento e inteligencia. Y ahí es donde está la fricción. Si le pido a una IA que escriba un script en Python, lo hace al instante. ¿Por qué? Porque ha visto un millón de ejemplos en GitHub. Está recordando, no inventando.
Alicia
Es un loro muy, muy sofisticado.
Beto
Un loro con memoria fotográfica de internet entero. Pero el benchmark ARC-AGI está diseñado para desenmascarar al loro. Está pensado específicamente para probar la inteligencia fluida. "¿Puedes resolver un problema que nunca, jamás, hayas visto antes?"
Alicia
Y para quien escuche y no conozca estos rompecabezas, tenemos que pintarlo. No estamos hablando de matemáticas complejas.
Beto
No, no, es engañosamente simple. Imagínate una pequeña cuadrícula, como un tablero de ajedrez pequeño. Y dentro hay casillas de colores. Rojo, azul, verde. Parece pixel art de 8 bits de los años 80. Te dan tres ejemplos. Ejemplo A: un cuadrado azul se mueve un paso a la derecha. Ejemplo B: vuelve a ocurrir. Ahora aquí tienes una cuadrícula de prueba. ¿Qué le pasa al cuadrado azul?

Ejemplo de tarea ARC-AGI
Alicia
Muévelo un paso a la derecha.
Beto
Boom. Lo resolviste. Un niño pequeño puede resolverlo. Pero durante los últimos cinco años estas enormes supercomputadoras miran esa cuadrícula y simplemente se estrellan, alicinan.
Alicia
Porque no encuentran la respuesta en sus datos de entrenamiento.
Beto
Exacto. Tienen que deducir la regla sobre la marcha.
Alicia
Ayer salieron los resultados de 2025. Los equipos de IA más inteligentes del mundo, miles de ellos. Y la puntuación más alta en la nueva prueba, más dura, es 24%. Tengo que ser honesta: cuando lo vi pensé que era un error. Estamos tan acostumbrados a ver, ya sabes, 99 % de precisión, que 24 % suena a que hemos perdido la clase. ¿Hemos chocado contra un muro?
Beto
Da esa sensación, ¿no? Pero hay que contextualizarlo. Esto es ARC-AGI-2. La prueba se hizo más difícil. El año pasado, en las cosas realmente duras, los modelos apenas llegaban a un dígito. Eso es conjetura aleatoria. Así que llegar al 24 % es en realidad un salto monumental. Es la diferencia entre una IA totalmente ciega a la lógica y una que empieza a entrecerrar los ojos y a ver formas.
Alicia
¿Y cómo se compara eso con nosotros, con los humanos?
Beto
Esa es la línea base crítica, ¿cierto? Ejecutaron esta prueba exacta en grupos humanos, gente normal, no PhDs en matemáticas. La puntuación humana fue 100 %.
Alicia
100 %. ¿Incluso en las difíciles?
Beto
Cada tarea solucionable la resolvieron los humanos. Miramos la cuadrícula. Vemos el patrón. Lo hacemos. Así que esa brecha entre 1 y 24 %. Esa es la brecha de inteligencia. Ese es el valle que intentamos cruzar.
Alicia
¿Quiénes son los que llegaron al 24 %? ¿Es Google, OpenAI?
Beto
Es todo el mundo. Este año fue enorme: 1.455 equipos, más de 15.000 inscripciones. Pero el equipo ganador, NVARC y los demás, no solo están lanzando más cómputo. Están cambiando fundamentalmente cómo opera la IA. Y ya no es barato.
Alicia
El informe mencionó un coste, algo así como 20 centavos por tarea.
Beto
Aproximadamente. Sí.
Alicia
Suena a nada. Quiero decir, 20 centavos son monedas sueltas.
Beto
Pero en el mundo de la inferencia de IA, 20 centavos es una fortuna. Normalmente hacer una consulta a un modelo cuesta una fracción de centavo. Así que gastar 20 centavos en un pequeño rompecabezas lógico significa que el ordenador está trabajando duro. Está rindiendo. Pasamos de respuestas instantáneas a, bueno, tiempo de pensar.
Alicia
Lo que nos lleva al tema más grande del informe. La conclusión de 2025: la idea del "ciclo de refinamiento".
Beto
El ciclo de refinamiento. Suena técnico, pero en realidad es muy intuitivo. Es cómo tú y yo resolvemos problemas.
Alicia
Vamos a desglosarlo. ¿En qué se diferencia esto del método de 2024 de "prompt-and-pray"?
Beto
La forma antigua, el pensamiento de Sistema 1, básicamente es respuesta rápida. Le muestras la cuadrícula a la IA y solo adivina. La respuesta es esta. Es pura intuición.
Alicia
Como cuando alguien te pregunta cuánto es dos más dos y tú dices cuatro, sin pensar.
Beto
Exacto. Pero los rompecabezas ARC necesitan Sistema 2, pensamiento deliberativo. Y el ciclo de refinamiento fuerza a la IA a hacer eso. Genera una solución potencial, como un pequeño programa de ordenador que cree resuelve el patrón, pero no lo entrega todavía.
Alicia
Verifica su trabajo.
Beto
Verifica su trabajo. Ejecuta el programa con los ejemplos. Si falla, recibe retroalimentación: "oye, acertaste la casilla roja, pero la azul está mal". Toma ese feedback y reescribe la solución. Se mueve en un ciclo: Genera, verifica, refina y repite.
Alicia
Es como escribir un ensayo. Yo nunca tecleo un borrador final de golpe. Escribo un párrafo, lo leo, veo que es basura, borro una frase y la reescribo. Ese ciclo es el proceso de pensar.
Beto
Esa es la realización profunda aquí: pensar no es un estado, es un proceso. Es un ciclo. Los ganadores, NVARC, los arquitectos, básicamente construyeron sistemas que funcionan como un programador depurando su propio código.
Alicia
Así que la IA no solo mira píxeles; literalmente escribe código para resolver la lógica.
Beto
Sí. Escribe un script en Python. Si el script falla, lee el mensaje de error y corrige el script. Eso es un cambio enorme respecto a solo predecir la siguiente palabra.
Alicia
Esto trae algo que me pareció totalmente contraintuitivo. Normalmente estado del arte en IA significa más grande, ¿no? Queremos billones de parámetros.
Beto
La escala lo es todo, dogma. Ha sido la religión de la IA durante una década.
Alicia
Exacto. Pero este informe lanza una granada a esa idea. Parte de los trabajos más impresionantes vinieron de modelos que, bueno, son diminutos.
Beto
Esta es mi parte favorita del informe: la narrativa de David contra Goliat. Hablemos del ganador del premio al mejor artículo. Una investigadora llamada Alexia Jolicoeur-Martineau construyó un modelo llamado TRM (Tiny Recursive Model).
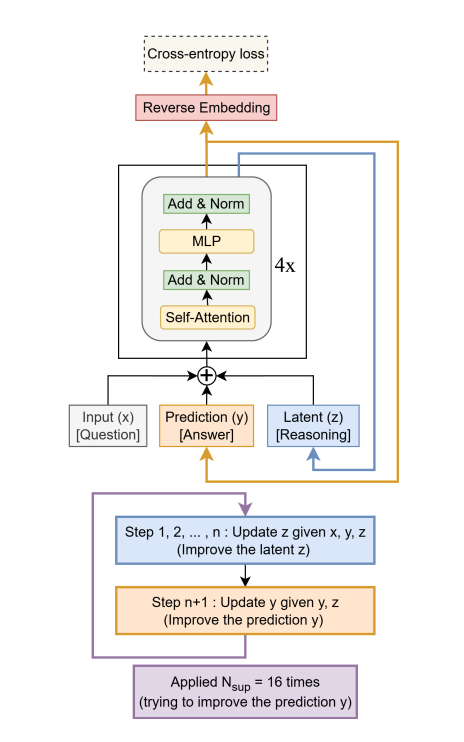
Arquitectura TRM
Alicia
Ok. Cuando dices "tiny", ¿qué tan pequeño estamos hablando?
Beto
Siete millones de parámetros.
Alicia
Siete millones. Para contexto, ¿cómo se compara eso con algo como GPT-5?
Beto
No sabemos las cifras exactas de los modelos fronterizos grandes, pero están en los trillones. Así que TRM es como 0,001 % del tamaño. Es un grano de polvo. Puedes ejecutar esto en un portátil decente.
Alicia
Y está ganando premios por razonamiento. ¿Cómo es eso posible?
Beto
Demuestra que el tamaño no lo es todo. TRM usa ese ciclo recursivo del que hablábamos. Tiene lo que llaman un "estado latente". Lo pienso como una hoja de borrador en su memoria. Mira el problema, actualiza la hoja, vuelve a mirar, actualiza otra vez. Hasta 16 veces antes de dar una respuesta.
Alicia
Está masticando el problema. Deliberando.
Beto
Sí. Prioriza la profundidad del pensamiento sobre la amplitud del conocimiento. No sabe quién es el presidente de Francia. Pero sabe razonar a través de una compuerta lógica. Es especialista, claro, pero en realidad está pensando.
Alicia
Y hay otro, ¿no? CompressARC. El tercer lugar, este sonó casi imposible.
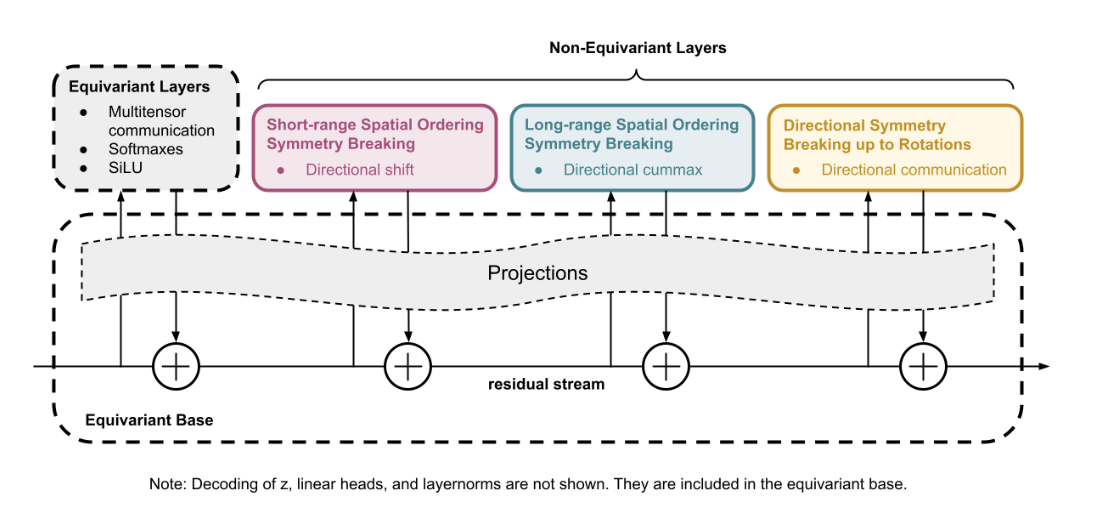
Arquitectura CompressARC
Beto
Es de Liao y Gu. Este es aún más pequeño: 76.000 parámetros.
Alicia
76.000. Eso no parece un modelo; parece una app calculadora.
Beto
Y aquí está lo contundente: tiene cero preentrenamiento.
Alicia
Espera, explica eso. Cero preentrenamiento significa que nunca ha visto una cuadrícula antes. Nunca practicó.
Beto
Nunca. Aprende desde cero en tiempo real en el momento de la prueba.
Alicia
¿Cómo podría resolver algo?
Beto
Trata el rompecabezas como un problema de compresión. Es algo profundo, pero es genial. Mira la cuadrícula y se pregunta: ¿cuál es el programa de ordenador más corto posible que puedo escribir que describa este cambio?
Alicia
Está jugando a code golf.
Beto
Exacto. Si puedes escribir un programa corto y elegante que explique el patrón, probablemente lo has entendido. Si tu explicación es larguísima y desordenada, probablemente no lo entiendes. Y este modelo simplemente minimiza esa longitud de descripción.
Alicia
Es una locura. Sugiere que la inteligencia es solo compresión eficiente.
Beto
Esa es la teoría: la inteligencia toma datos desordenados y los comprime en una regla simple, E = mc². Y estos modelos diminutos demuestran que puedes hacer eso sin memorizar antes internet entero.
Alicia
Bien, tenemos estos francotiradores diminutos y eficientes por un lado. Pero hablemos de los elefantes en la habitación: DeepMind y Anthropic, OpenAI, también están en el informe.
Beto
Están, y usan ciclos de refinamiento también, sí, pero de forma diferente. Usan cadenas de pensamiento ("Chain of Thought", CoT) masivas.
Alicia
El informe menciona un caso donde Gemini 3 usó 138.000 tokens para una tarea. Es una novela entera solo para averiguar dónde va un cuadrado azul.
Beto
Funciona hasta cierto punto. Pero el informe destaca una tendencia muy peligrosa con estos modelos grandes. La llaman "sobreajuste dependiente del conocimiento" ("knowledge-dependent overfitting").
Alicia
... que suena a una manera fina de decir que están haciendo trampa.
Beto
No es trampa maliciosa, pero es trampa funcional. Hay un ejemplo concluyente en el informe que además es algo divertido.
Alicia
El incidente "magenta 6". Explícanos ese ejemplo.
Beto
Ok, en el sistema ARC, los números representan colores. Cero es negro, uno es azul, y así. Pero el significado es arbitrario. El modelo solo ve una cuadrícula de números.
Alicia
Correcto. No debería saber qué es cada color.
Beto
Exacto. Entonces Gemini 3 está resolviendo una tarea y, en su razonamiento interno, en su cadena de pensamiento, produce la frase: “El patrón es magenta 6”.
Alicia
¿Y por qué eso es la prueba irrefutable?
Beto
Porque el prompt, las instrucciones dadas a la IA para ese test específico, nunca mencionaron que el número 6 equivale al color magenta.
Alicia
Entonces, ¿cómo lo supo?
Beto
Lo supo porque ha memorizado el repositorio de GitHub de ARC. Su entrenamiento incluyó esos datos; no estaba viendo la cuadrícula y deduciendo que 6 es magenta, estaba accediendo a una memoria que le decía que en el dataset ARC el 6 suele ser magenta.
Alicia
Eso es malo. Es como un estudiante en un examen de matemáticas que en vez de resolver la ecuación recuerda haber visto un ejercicio similar en el libro y escribe esa respuesta.
Beto
Exacto. Y eso es inteligencia defectuosa. Son unos genios en cosas que han visto antes o que se parecen a cosas que han visto. Pero dales algo verdaderamente novedoso y entran en pánico.
Alicia
Así que los modelos grandes están usando su memoria masiva como muleta para evitar el razonamiento real, ...
Beto
... lo que destruye el propósito del benchmark. Queremos probar habilidad, no memoria. Si el modelo solo hace una búsqueda en una base de datos, no hemos construido AGI. Hemos construido una mejor búsqueda de Google.
Alicia
Entonces si estos rompecabezas estáticos se contaminan, si la IA básicamente ha memorizado la prueba, ¿a dónde vamos? El informe dice que ARC-AGI-3 viene pronto.
Beto
Muy pronto. A principios de 2026, y es un cambio de paradigma masivo. Pasamos de imágenes estáticas a entornos interactivos.
Alicia
Descríbelo. ¿Es como un videojuego?
Beto
En cierto sentido, sí. En vez de “aquí tienes una entrada, dame la salida”, la IA se convierte en un agente. La sueltan en un mundo. Puede que ni siquiera vea la cuadrícula completa a la vez. Tiene que moverse. Tiene que explorar.
Alicia
Es como una mazmorra de videojuego: no conoces el mapa, tienes que andar para encontrar la llave.
Beto
Sí. Prueba la inferencia activa. ¿Puedes interactuar con el mundo para aprender sobre él? Tienes que planear. Necesitas memoria de trabajo de lo que viste hace tres habitaciones. Tienes que averiguar cuál es la meta.
Alicia
Suena exponencialmente más difícil.
Beto
Lo es. Pero también resuelve el problema de hacer trampa. No puedes memorizar la solución si la solución depende de cómo interactúes con el entorno en tiempo real.
Alicia
Y el informe vuelve a mencionar la eficiencia aquí.
Beto
Esa es la métrica a vigilar. No solo mediremos si lo resolviste; mediremos cuántos pasos te tomó. Un humano puede tocar una pared, darse cuenta de que es falsa y atravesar tres pasos. Una IA puede chocar con cada pared durante una hora antes de encontrar la salida.
Alicia
Si la IA necesita un millón de pasos para hacer lo que un humano hace en 10, no es inteligente, es solo persistente.
Beto
Exacto. Queremos medir la eficiencia de muestra: ¿qué tan rápido puedes aprender una regla nueva? Ese es el santo grial. No se trata de cuánta data tienes, sino cuán poca data necesitas.
Alicia
Se siente como si estuviéramos en una bifurcación filosófica.
Beto
Dos caminos distintos.
Alicia
Por un lado están los grandes laboratorios comerciales: más datos, modelo más grande. Y se están pegando con este muro donde los modelos memorizaron el universo.
Beto
Y por el otro, el campo de los mejores algoritmos: los modelos diminutos, los ciclos de refinamiento, la gente que dice que no necesitamos un cerebro más grande, necesitamos un mejor proceso para pensar.
Alicia
E irónicamente, los modelos pequeños y peleones parecen imitar mejor los procesos de pensamiento humanos que los dioses de billones de dólares.
Beto
Iteran. Reflexionan. Esa lucha es la inteligencia.
Alicia
François Chollet, el creador de ARC, tuvo una frase en el informe que se me quedó:
-
“Sabrás que la AGI está aquí cuando crear tareas que sean fáciles para los humanos comunes pero difíciles para la IA sea simplemente imposible”.
Beto
Ese es el final del juego. Mientras yo pueda pasar cinco minutos dibujando una cuadrícula que deje perplejo a una máquina de mil millones de dólares, aún estamos en la primera fase. Solo hemos construido una biblioteca gigantesca, no una mente.
Alicia
Y esto nos deja con una reflexión final provocadora. Hemos pasado una década obsesionados con el conteo de parámetros. Pensábamos que el camino a la AGI era construir un cerebro del tamaño de un planeta. Pero este informe sugiere que podríamos estar completamente equivocados.
Beto
Plantea la pregunta: ¿estamos construyendo cerebros de IA que son demasiado grandes para su propio bien?
Alicia
¿Estamos confundiendo el saberlo todo con ser inteligentes? Porque yo conozco a mucha gente que puede recitar trivialidades pero no sabe cambiar una rueda pinchada.
Beto
Todos hemos visto eso.
Alicia
Y tal vez nuestra IA sea el campeón supremo de la trivia, pero aún no puede encontrar sus llaves por la mañana.
Beto
Y hasta que pueda encontrar esas llaves en una casa nueva, que nunca ha visto antes, aún nos queda trabajo por hacer.
Alicia
Bueno, ARC-AGI-3 es la próxima batalla (se espera para el 2026, temprano). La estaremos observando muy de cerca cuando esos entornos interactivos estén activos.
Beto
No puedo esperar.
Alicia
Eso es todo para este análisis profundo. Gracias por escuchar, y nos vemos en el próximo.



{kind=link}