
Este trabajo de investigación presenta una taxonomía integral de siete dimensiones diseñada para evaluar sistemas de IA Agéntica en los campos de la salud y la medicina. Mediante el análisis de 49 estudios distintos, los autores evalúan cómo los agentes basados en LLMs gestionan tareas complejas como el razonamiento cognitivo, la gestión del conocimiento, la seguridad y la ética. Los hallazgos revelan que, si bien estos agentes destacan en tareas centradas en la información, como la respuesta a preguntas médicas y la documentación, a menudo presentan dificultades en responsabilidades orientadas a la acción, como la planificación de tratamientos y el descubrimiento de fármacos. Además, el estudio identifica lagunas críticas en la investigación actual, específicamente en lo que respecta a los desencadenadores de eventos autónomos, la supervisión humana en el circuito y los mecanismos robustos de recuperación de errores. En definitiva, la fuente sirve como marco estandarizado para el seguimiento de la madurez de los sistemas inteligentes en su transición de simulaciones teóricas a herramientas clínicas responsables.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "Agentic AI in Healthcare & Medicine: A Seven-Dimensional Taxonomy for Empirical Evaluation of LLM-based Agents", por Shubham Vatsal y colegas. Publicado el 4 de Febrero del 2026.
El resumen, la transcripción, la traducción, y las voces, fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Escúchalo aquí, o lee la transcripción (abajo):
Transcripción
Alicia
Bienvenidos a un nuevo análisis profundo. Hoy vamos a mirar bajo el capó de lo que podría ser la tecnología más trascendental de la próxima década: IA con agencia y salud.
Beto
Y no estamos hablando solo de un chatbot que te da un plan de dieta genérico y te dice que bebas más agua.
Alicia
No.
Beto
Hablamos de un cambio fundamental en cómo construimos estos sistemas de IA.
Alicia
Correcto. Porque la narrativa ha cambiado. En los últimos años todo giraba en torno a la IA generativa, sistemas que crean texto o imágenes. Pero ahora la palabra de moda es agencia. Hablamos de sistemas que pueden planificar, usar herramientas, ejecutar tareas.
Beto
Y básicamente actuar como un médico residente digital. Esa es la promesa. Sí.
Alicia
Entonces la idea no es solo preguntarle algo a la IA, sino darle un trabajo.
Beto
Exacto. Le dices: "gestiona el plan de cuidado de la diabetes de este paciente durante los próximos seis meses". Y el agente se pone en marcha. Monitorea las analíticas, cita consultas, comprueba interacciones medicamentosas. Y solo te molesta cuando algo realmente va mal.
Alicia
Lo cual suena increíble. Quiero decir, suena como la solución al agotamiento médico. Pero las promesas son baratas. Y en medicina, si la promesa falla, la gente puede resultar herida. Así que para averiguar si estos agentes están realmente listos para el hospital, o si esto es otra vez Silicon Valley prometiendo más de lo que puede cumplir, revisamos un trabajo de investigación enorme hoy.
Beto
Es un artículo de revisión importante. Se titula "Agentic AI and Healthcare and Medicine" y se publicó en IEEE Access en enero de 2026. Los autores, Vatsal, Dubey y Singh, básicamente decidieron hacer una comprobación de la realidad en toda la industria.
Alicia
No miraron un solo demo llamativo. Revisaron 49 estudios distintos publicados entre finales de 2023 y mediados de 2025. Querían saber: ¿son estos sistemas realmente capaces de hacer el trabajo? ¿O solo son buenos respondiendo exámenes de opción múltiple?
Beto
Y para eso no podían usar las métricas existentes. Porque antes de esto, la investigación era el Lejano Oeste. Un artículo decía: nuestra IA es excelente porque aprobó el examen de licencia médica de EE. UU. Y otro decía: la nuestra es excelente porque puede resumir un PDF. No puedes comparar esas dos cosas.
Alicia
Así que necesitaban una regla común.
Beto
Precisamente. Los autores crearon lo que llaman una "taxonomía en siete dimensiones".
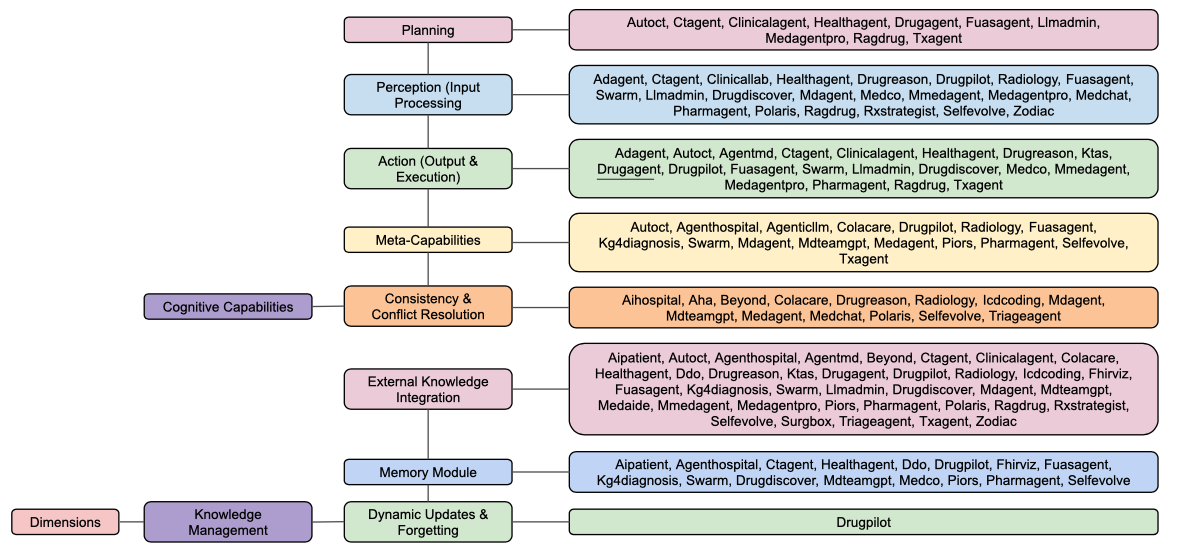
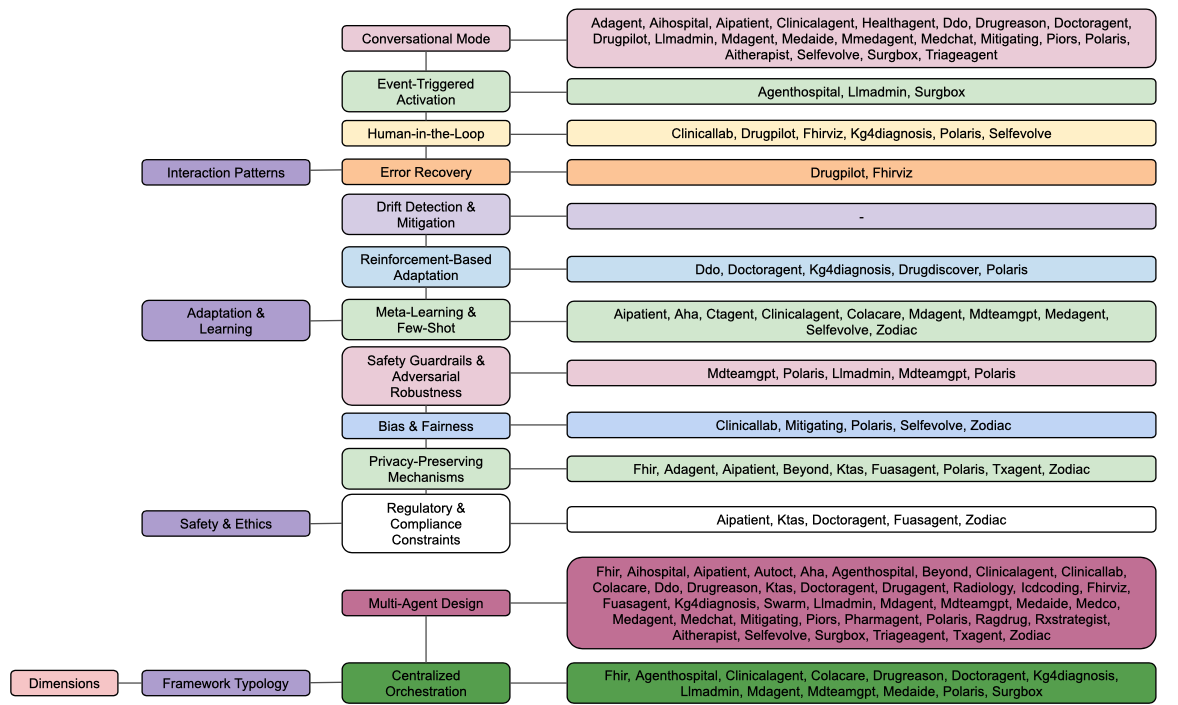
Taxonomía de las siete dimensiones
Alicia
Piénsalo como un boletín estandarizado para médicos IA. Evaluaron esos 49 sistemas en cosas como capacidad cognitiva, memoria, trato al paciente y seguridad.
Beto
Viendo las notas…
Alicia
Bueno, digamos que si esto fuera el boletín de mi hijo, tendríamos una conversación muy seria.
Beto
Es definitivamente una mezcla. Si tuviéramos que resumir la tesis de este análisis profundo: hemos construido agentes que son auténticos genios leyendo y recuperando información, pero están fracasando estrepitosamente en aprender, adaptarse y, crucialmente, en saber cuándo detenerse.
Alicia
Es la diferencia entre saber de libros y saber de la calle, o quizá entre inteligencia y sabiduría.
Beto
Buena forma de decirlo.
Capacidades Cognitivas
Alicia
Empecemos con la primera mención en el boletín: capacidades cognitivas, el cerebro.
Beto
Esto es el núcleo. ¿Puede el agente pensar? Específicamente, los autores miran tres cosas: planificación, percepción y capacidades meta.
Planificación
Alicia
Hablemos de planificación primero, porque si contrato a un asistente humano o a un médico principiante, espero que pueda planificar a futuro: primero hacer A, luego, si ocurre B, hacer C; eso parece básico.
Beto
Uno pensaría que sí, pero aquí vemos la primera gran bandera roja. El estudio encontró que la planificación — es decir, la habilidad para descomponer objetivos a largo plazo en hitos más pequeños — fue calificada como no implementada en alrededor del 45% de los estudios.
Alicia
Casi la mitad. Así que, en cierto sentido, se están improvisando.
Beto
Sí, son reactivos. Les cuesta lo que llamamos "objetivos de horizonte largo" en salud. Un plan de tratamiento no es un evento aislado; se desarrolla a lo largo de semanas o meses.
Alicia
Tienes que verificar que el paciente recogió la medicación, luego comprobar efectos secundarios unos días después.
Beto
Exacto. Luego ajustar la dosis según un resultado de laboratorio dos semanas después.
Alicia
Y los agentes actuales no pueden mantener esa línea temporal en la cabeza.
Beto
La mayoría no pueden. Se quedan pegados en el "aquí" y "ahora". Los autores califican a la mayoría como, en el mejor de los casos, parcialmente implementados, lo que significa que pueden hacer una descomposición básica de tareas. Por ejemplo: para diagnosticar X necesito pedir la prueba Y.
Alicia
Pero no la parte dinámica.
Beto
Correcto. La planificación dinámica y sofisticada, donde el plan se ajusta según nuevos datos, falta en gran medida.
Alicia
Eso parece un obstáculo insalvable para el manejo de enfermedades crónicas. No puedes tratar la diabetes con un sistema que no puede pensar más allá de mañana.
Pero seguro que son mejores viendo lo que está frente a ellos.
Percepción y Acción
Beto
Lo son. La puntuación de percepción es mucho más alta: alrededor del 41-46% de los agentes implementaron totalmente percepción y acción.
Alicia
Define eso. ¿Qué cuenta como percepción?
Beto
Es la habilidad para procesar datos crudos, no solo texto, sino mirar una radiografía, leer un ECG o extraer datos de una historia clínica electrónica. Y acción significa que realmente pueden hacer algo con ello.
Alicia
... como pedir un análisis de sangre.
Beto
Exacto. Como disparar una llamada API al laboratorio.
Alicia
Bien. Así que pueden ver que el paciente está enfermo y pueden ordenar la prueba. Eso suena funcional.
Capacidades Meta
Beto
Lo es. Pero aquí está la trampa: la inteligencia no es solo conocer la respuesta, es saber cuándo no conoces la respuesta.
Alicia
Y eso es lo que llaman capacidades meta, pensar sobre el pensamiento.
Beto
Correcto. Autorreflexión. Calibración de la confianza. Y ahí las notas se desploman. El informe encontró que aproximadamente el 53% de los agentes carecen de esto por completo.
Alicia
Son idiotas confiados.
Beto
No están calibrados. Un médico humano sabe cuándo está fuera de su alcance; dice: “No estoy seguro de este sarpullido; necesito consultar con Dermatología”. Estos agentes, al carecer de esa capacidad meta, a menudo fabrican, halucinan, diagnósticos con confianza. No tienen el mecanismo interno para decir: mi puntuación de confianza es baja; debo parar.
Alicia
Eso conecta con otra estadística que vi en tus notas sobre resolución de conflictos.
Beto
Sí. Y eso es aterrador en un entorno clínico. Aproximadamente el 61% de los agentes no tienen ningún mecanismo para resolver información contradictoria.
Alicia
Dame un ejemplo real de eso. ¿Qué pasa?
Beto
Bien. Imagina que la IA lee la historia del paciente. Una nota de 2022 dice que el paciente tiene una alergia severa a la penicilina. Una nota de 2024 dice que el paciente toleró penicilina sin problema. Un médico humano se detiene y piensa: “¡Eh!, esto contradice; debo investigarlo antes de que pueda matar a alguien”.
Alicia
Y la IA, ¿qué haría?
Beto
Sin módulos de resolución de conflictos, simplemente opera sobre un modelo probabilístico. Puede elegir la más reciente, la que apareció primero, o intentar mezclar ambas en algo incoherente. No se da cuenta de que hay una contradicción.
Alicia
Le falta el juicio para decir: espera, esto no cuadra.
Beto
Precisamente. Así que tenemos un cerebro que puede leer y actuar, pero no puede planificar a largo plazo ni sabe cuándo está confundido.
Gestión del Conocimiento
Alicia
Pasemos a la segunda dimensión, gestión del conocimiento, la biblioteca. Y creo que aquí la IA realmente saca un sobresaliente.
Beto
Saca un sobresaliente en una cosa concreta: la integración de conocimiento externo. Esto está totalmente implementado en alrededor del 76% de los agentes. Probablemente hayas oído el término RAG.
Alicia
“Retrieval-augmented generation”, generación aumentada por recuperación. Es como darle al agente un examen con libro abierto.
Beto
Exacto. En vez de confiar solo en lo que memorizó durante su entrenamiento, que puede estar desactualizado, el agente puede buscar las guías más recientes o consultar una base de datos de interacciones de medicamentos. Esta es la parte más fuerte de la tecnología actual. Ancla a la IA en hechos.
Alicia
Pero, y siempre hay un “pero”, tener una biblioteca solo es útil si sabes cómo tirar los libros viejos.
Actualizaciones Dinámicas y Olvido
Beto
Y aquí llegamos a quizás la estadística más chocante del artículo: la categoría es actualizaciones dinámicas y olvido.
Alicia
Ay. ¿Cuántos fallaron en esto?
Beto
Aproximadamente el 98%.
Alicia
98%. Así que casi nadie está construyendo una forma para que estos agentes actualicen sus creencias internas.
Beto
Solo uno de los 49 trabajos que revisaron lo implementó completamente un sistema llamado DrugPilot. Todos los demás construyeron sistemas estáticos.
Alicia
Espera, explícame esto. ¿Por qué es tan difícil olvidar? Es una computadora; ¿no puedes simplemente borrar el archivo?
Beto
Esa es la intuición, ¿no? Pero los modelos de IA no son bases de datos. Cuando una IA aprendió algo durante el entrenamiento, esa información no está en una carpeta específica que puedas arrastrar a la papelera. Está horneada en los pesos neuronales: las miles de millones de conexiones entre las neuronas artificiales. Es como un recuerdo de la infancia: no puedes extraerlo quirúrgicamente.
Alicia
Entonces la información está difundida por todo el cerebro.
Beto
Exacto. Si un agente se entrenó con datos médicos de 2020 que decían que el tratamiento A era el mejor y en 2024 descubrimos que el tratamiento A causa infartos, tienes un problema.
Alicia
Un problema enorme.
Beto
Incluso si le muestras a la IA el nuevo artículo, ese sesgo profundo del entrenamiento hacia el tratamiento A sigue ahí, latente en los pesos.
Alicia
Terminas con un médico acumulador: un doctor que memorizó los libros de texto de 1990 y se niega a desaprenderlos.
Beto
Y que puede no creer cuando le dices las nuevas guías, pero bajo presión vuelve al viejo método. Si el agente no puede decaer la información antigua, si no puede olvidar, es intrínsecamente peligroso. Se vuelve obsoleto en cuanto termina su entrenamiento.
Alicia
Eso es una responsabilidad enorme. El conocimiento médico cambia cada día. Los fármacos se retirán, los protocolos se actualizan constantemente.
Beto
Confiar solo en el RAG para buscar nueva información ayuda, pero no resuelve el sesgo subyacente del modelo.
Alicia
Hablando de memoria, supongo que al menos pueden recordar lo que les dije hace cinco minutos.
Beto
Bueno, la memoria a corto plazo está aceptable, pero la memoria a largo plazo sofisticada, como recordar que tuviste el mismo sarpullido hace seis meses y que probamos la crema X y no funcionó, eso es sorprendentemente débil. Aproximadamente el 49% de los estudios tenían solo una implementación parcial de esto.
Alicia
Así que es como si cada vez tuviera que repetir la historia clínica: "Hola, soy tu médico, cuéntame tu historia médica otra vez."
Beto
Crea fricción para el usuario y rompe la continuidad del cuidado, que es la base de la buena medicina.
Patrones de Interacción
Alicia
Hablemos de la experiencia del usuario, segmento tres: patrones de interacción, el trato al paciente.
Beto
Pueden chatear; el modo conversacional es estándar. Unos 43% implementaron totalmente diálogos complejos. Pueden mantener el contexto, ser educados. Se nota la herencia de los chatbots.
Alicia
Pero conversación implica que yo inicio la discusión: “Eh, IA, ayúdame”. ¿Qué pasa si no puedo hablar? ¿Qué pasa si estoy dormido y mi ritmo cardíaco se dispara?
Beto
Y aquí está el problema proactivo. El informe muestra que alrededor del 92% de los agentes no están implementados para activación por eventos o vigilancia.
Alicia
Son mayordomos perezosos. Se sientan en la esquina hasta que suenan la campana.
Beto
"Pasivos", es el término técnico. Pero sí: en un hospital quieres un guardián silencioso. Quieres un agente que monitorice la corriente de datos: analíticas, constantes vitales, notas de enfermería, las 24*7.
Alicia
Y que solo alerte cuando detecta un problema.
Beto
Correcto. Cuando ve un patrón. Por ejemplo, "el potasio baja mientras la creatinina sube", se despierta y avisa al equipo sin que nadie pregunte.
Alicia
La verdadera agencia es proactiva.
Beto
Correcto. Si la IA espera a que el humano pregunte “¿está bien el paciente?”, ha fallado como salvaguarda.
Alicia
Hubo otro fallo técnico que me preocupó: recuperación de errores. El 96% de los agentes no la tiene. ¿Qué significa eso en lenguaje llano?
Beto
Significa que son frágiles. Supongamos que la IA decide solicitar una receta, formatea los datos y la envía a la API de la farmacia, pero el Wi‑Fi falla, o el servidor de la farmacia está caído.
Alicia
Es algo que puede ocurrir normalmente en informática.
Beto
Correcto. Un sistema normal tendría reintentos controlados (reintentos idempotentes). Sabría cómo intentar de nuevo de forma segura sin pedir la medicación dos veces o haría rollback de la transacción hasta que el humano confirme.
Alicia
'Idempotentes', suena como a un conjuro de Harry Potter.
Beto
Solamente significa que hacer la misma cosa varias veces no cambia el resultado. Como cuando presionas el botón para llamar a un ascensor. Lo puedes presionar diez veces, pero el ascensor apenas viene una vez.
Alicia
Estos agentes no suelen hacer eso.
Beto
La mayoría no. Se bloquean o, peor aún, asumen que la orden fue procesada cuando no lo fue. El 96% de los estudios no incorporó estas redes de seguridad. Construyeron agentes para el camino feliz, que asumen que todo siempre funciona.
Alicia
Eso está bien para un vídeo demo ante inversores, pero no para un hospital a las 2 a.m.
Beto
Resalta que estábamos viendo prototipos, no productos.
Adaptación y Aprendizaje
Alicia
Pasemos al segmento cuatro, adaptación y aprendizaje. Hablamos del olvido, ¿pero y el aprendizaje de cosas nuevas? ¿Y este concepto de deriva?
Beto
La deriva, "drift", es el asesino silencioso de los modelos de IA: cuando el mundo cambia y el modelo no.
Alicia
Dame un ejemplo concreto.
Beto
Piensa en la demografía de los pacientes. Digamos que entrenas un agente con datos de un hospital universitario acomodado de Boston. Luego despliegas ese agente en una clínica rural de Arizona.
Alicia
Una población completamente distinta.
Beto
Exacto. Diferentes edades, dieta, factores ambientales. La distribución de datos ha derivado; o piensa en una nueva cepa de enfermedad que aparece. Los síntomas cambian. El modelo entrenado con la gripe del año pasado no reconocerá la gripe de este año.
Alicia
Y la hoja de calificaciones dice ...
Beto
... que el 98% de los agentes no tiene ningún mecanismo para detectar deriva.
Alicia
Así que vuelan a ciegas. Ni siquiera sabrían que su rendimiento empeora.
Beto
Seguirían diagnosticando con confianza la enfermedad antigua o malinterpretando la nueva población porque su modelo del mundo está congelado.
Alicia
¿No pueden aprender del feedback? Si el médico dice “no, mala IA, ese diagnóstico es incorrecto”, ¿se vuelve más listo?
Beto
Eso es la adaptación basada en refuerzo, aprendizaje por refuerzo ("Reinforcement Learning", RL). Y falta en alrededor del 84% de los agentes. La mayoría son motores de inferencia estáticos. Lo corriges hoy y mañana comete exactamente el mismo error.
Alicia
Eso es increíblemente frustrante. Los hace sentirse como máquinas tontas en vez de socios inteligentes.
Beto
Erosiona la confianza. Si tienes que corregir a tu asistente en la misma tarea cinco veces, lo despedirías.
Seguridad y Ética
Alicia
Esto nos lleva al segmento cinco, seguridad y ética. Si estas cosas son frágiles, estáticas y no están calibradas, ¿son seguras?
Beto
Los autores encontraron una brecha enorme entre la intención y la garantía. Todos los artículos dicen “la seguridad es nuestra prioridad”. Pero al mirar el código, faltan las barreras.
Alicia
Los números son contundentes.
Beto
Mecanismos de seguridad, como formas de evitar que la IA sea “liberada”, o evitar que haga algo claramente peligroso, faltan en el 65% de los estudios.
Y el cumplimiento normativo, implementar leyes como HIPAA o GDPR, faltaba en el 86% de los diseños.
Alicia
Espera, ¿el 86% de estudios de IA médica no incorporó cumplimiento con HIPAA o RGPD?
Beto
Confiaban en el LLM subyacente para ser “seguro”, pero no construyeron restricciones arquitectónicas específicas para garantizar la privacidad del paciente. No hay una línea de código que diga: si estos datos salen del entorno seguro, bloquear y registrar.
Alicia
Eso parece una demanda asegurada.
Tipología del Marco
Quiero tocar cómo se construyen estas cosas porque el artículo menciona una tipología que me pareció genial: el diseño multiagente.
Beto
Esta es la gran tendencia. Alrededor del 82% de los artículos no usan una sola IA; usan un equipo.
Alicia
Como un personal hospitalario digital.
Beto
Exacto. Puedes tener un agente que actúe como médico y proponga un diagnóstico; luego otro agente que actúe como crítico.
Alicia
Y su trabajo entero es apuntar fallos en el argumento.
Beto
Ese es su trabajo entero: “¿Estás seguro? ¿Comprobaste la presión arterial? ¿Y este resultado de laboratorio?”. En algunos trabajos debaten entre ellos.
Alicia
Eso es fascinante.
Beto
Artículos como ColaCare y MDAgents muestran que este proceso de debate reduce significativamente las alucinaciones. Obliga al sistema a revisar su trabajo. Simula el tipo de revisión por pares que ocurre en un hospital real.
Alicia
Tiene sentido. “Mide dos veces, corta una”. ¿Pero quién manda?
Beto
Ahí está el problema. El informe señala que la orquestación centralizada, tener un agente jefe de personal para coordinar al equipo, a menudo solo está parcialmente implementada, alrededor del 57%.
Alicia
Así que tienes un montón de “médicos” debatiente en una sala pero nadie que tome la decisión final.
Beto
Eso puede llevar a ciclos donde discuten indefinidamente o el flujo de trabajo se paraliza. Necesitas esa capa jefe que diga: “vale, hemos debatido suficiente; es hora de decidir”.
Aplicaciones
Alicia
Finalmente, segmento seis: ¿para qué están aplicando estos agentes? ¿Qué trabajos están haciendo en los estudios?
Beto
Los ganadores son la fruta más accesible. Benchmarking es enorme. El 80% de los artículos estaban probando los agentes contra exámenes. QA médica (preguntas y respuestas médicas) está totalmente implementado en 57% de los estudios.
Alicia
Así que son excelentes en trivia médica.
Beto
Y documentación: resumir historias clínicas, extraer códigos de facturación; alrededor del 45% lo hace bien. Es útil, pero administrativo.
Alicia
¿Y los perdedores? ¿Dónde están las carencias?
Beto
Lo de alto riesgo: planificación del tratamiento, prescribir un plan de cuidado completo, solo 20%. Interacción directa con el paciente, hablar con la persona enferma, solo 22%.
Alicia
Porque es demasiado arriesgado.
Beto
Es increíblemente arriesgado. Y descubrimiento de fármacos prácticamente inexistente en este conjunto de datos; el 80% lo ignoró. No estamos pidiendo a estos agentes que inventen nuevas curas todavía; intentamos que manejen el papeleo de las que ya existen.
Resumen
Alicia
Resumamos todo. Hemos revisado el boletín. Parece que tenemos un estudiante que es brillante en la biblioteca,
Beto
... sobresaliente en recuperación ...
Alicia
... y juega bien en equipo,
Beto
... notable en colaboración multiagente ...
Alicia
... pero se niega a aprender algo nuevo. Se cae cuando se va la conexión, actúa completamente de forma pasiva y no sabe cuándo dejar de hablar si está confundido.
Beto
Resumen duro pero justo: "F" en adaptación, "F" en robustez, "F" en garantías de seguridad.
Conclusión
Alicia
¿Cuál es la conclusión para el médico o desarrollador que nos escucha? ¿Es todo esto un gran fracaso?
Beto
No, en absoluto. La conclusión es que hemos pasado de modelos predictivos — adivinar la siguiente palabra — a marcos agentivos. La estructura está allí. Tenemos el cuerpo.
Alicia
... pero no el sistema inmunológico.
Beto
No tenemos aún el sistema inmune, la habilidad para detectar errores y adaptarse. Seguimos construyendo artefactos estáticos en un mundo dinámico. Para que estos agentes sean realmente seguros en un hospital, deben evolucionar. Necesitan detección de deriva, protocolos de desaprendizaje, deben ser lo bastante humildes para decir “no lo sé”.
Alicia
Hasta entonces son solo motores de búsqueda muy sofisticados y muy frágiles.
Beto
Sí, asistencia poderosa. No, agentes autónomos, absolutamente no. No puedes sacar al humano del circuito. Si la máquina no puede aprender de sus errores o reconocer cuando la situación cambia…
Alicia
Y eso nos lleva a nuestro pensamiento final para el análisis profundo. Siempre nos gusta dejar algo para masticar.
Beto
Aquí va mi pregunta: pasamos tanto tiempo preocupándonos de que la IA se vuelva demasiado inteligente, Skynet, una superinteligencia que nos domina, ¿estaremos preocupándonos por algo equivocado?
Alicia
¿Qué quieres decir?
Beto
El peligro inmediato en salud no es una IA que nos supere intelectualmente. Es una IA lo bastante inteligente para dar consejos convincentes pero demasiado tonta para saber que las guías médicas cambiaron el martes pasado.
Alicia
Un genio desactualizado podría ser más peligroso que un tonto.
Beto
Exacto. En medicina, lo que sabías hace cinco años no es solo noticia vieja; es mala praxis. Si no resolvemos el problema del olvido, no podremos tener médicos IA.
Alicia
Pensamiento sobrio: la inteligencia es saber qué aprender. La sabiduría es saber qué olvidar. Gracias por acompañarnos en el análisis profundo.
Beto
Nos vemos la próxima vez.



{kind=link}