
Esta investigación ofrece una revisión exhaustiva de la interacción intermodal entre la música impulsada por IA y diversos formatos de datos como texto, imágenes y vídeo. Clasifica estos avances tecnológicos en marcos impulsados por la música, orientados a la música y bidireccionales, ilustrando cómo las máquinas ahora analizan, generan y sincronizan contenido auditivo complejo. Los autores trazan la evolución desde la música simbólica hasta los modelos modernos de aprendizaje profundo, incluyendo difusión y transformadores, que facilitan tareas como la transcripción de letras, la coreografía con IA y la edición de vídeo. Además, el texto detalla conjuntos de datos multimodales esenciales y métricas de evaluación objetivas utilizadas para medir la calidad y la alineación rítmica de los medios generados. Al abordar la escasez actual de datos y las limitaciones computacionales, el artículo destaca las tendencias futuras en agentes musicales multimodales y la alineación con las preferencias humanas. En última instancia, las fuentes sirven como una guía fundamental para integrar la inteligencia artificial más profundamente en los ciclos de vida creativos de la industria musical global.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "A Survey on Cross-Modal Interaction Between Music and Multimodal Data", por Sifei Li y colegas. Publicado el 21 de Febrero del 2026.
El resumen, la transcripción, la traducción, y las voces, fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Escúchalo aquí, mientras lees la transcripción (abajo):
Transcripción
Beto
¿Has oído hablar alguna vez de la sinestesia?
Alicia
Oh, sí. Es esa condición neurológica realmente fascinante, ¿no? Donde los cables del cerebro se cruzan como en algo bueno...
Beto
Exacto.
Alicia
...como que puedas oír un acorde de piano específico y al instante saborear fresas. O ves el número cinco y para ti siempre es indudablemente azul brillante.
Beto
Exactamente. Es esa mezcla de los sentidos. Y para los humanos es una rareza biológica. Pero aquí está la cosa por la que nos metemos hoy: lo que antes era una anomalía rara en nosotros se está convirtiendo rápidamente en el sistema operativo estándar para la inteligencia artificial. Literalmente estamos enseñando a las máquinas a tener sinestesia.
Alicia
Esa es en realidad una analogía perfecta. Ya no solo enseñamos a los ordenadores a procesar datos. Les enseñamos a traducir experiencias entre distintos medios: mirar la foto de un atardecer y simplemente escuchar la banda sonora que le pertenece, o tomar un párrafo de texto y bailar al ritmo de esas palabras específicas.
Beto
Y esa es la misión de este análisis en profundidad. Desentrañamos lo que llaman aprendizaje multimodal, específicamente en el contexto de la música. Para quienes escuchan, nos basamos en un gran artículo de revisión de 2026.
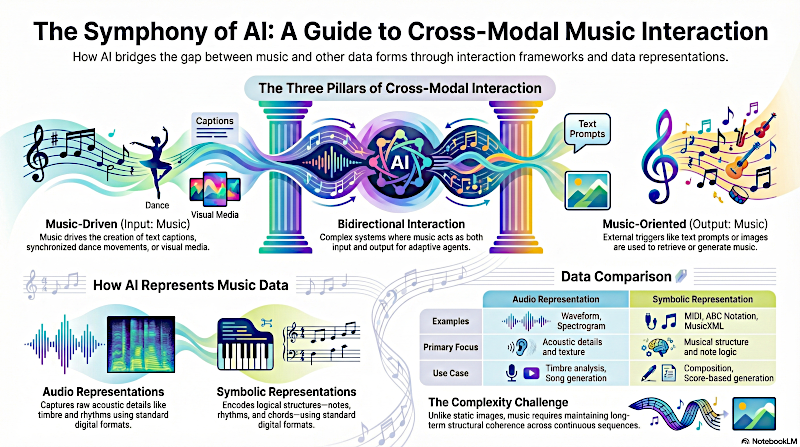
Interacción Musical Inter-Modal
Alicia
Uno realmente denso.
Beto
Muy denso. Se titula “A Survey on Cross-Model Interaction Between Music and Multimodal Data”, es de Sifei Li y su equipo, publicado en Computational Visual Media.
Alicia
Y este artículo es, esencialmente, el plano de cómo pasamos de simples pitidos MIDI a que la IA genere canciones completas listas para la radio con voces, o incluso a que coreografíe rutinas de baile complejas. Cubre cómo las máquinas leen la música, cómo la visualizan y cómo están empezando a componerla.
Beto
Pero antes de llegar a la parte de ciencia ficción, los bailarines IA y los generadores de texto a canción, tenemos que empezar por la lucha. Porque el artículo lo deja muy claro desde el principio: la música es especialmente difícil para la IA.
Alicia
De verdad lo es. Quiero decir, comparado con la generación de imágenes, si le muestro a una IA la foto de un gato, esos datos son espaciales. Son estáticos.
Beto
Exacto, están ahí quietos.
Alicia
Toda la información, las orejas, los bigotes, la cola, está presente en el mismo instante. Puedes analizarlo todo de una vez.
Beto
Pero la música es temporal. Sucede a lo largo del tiempo.
Alicia
Sí, es una secuencia. No puedes ver la canción completa de un vistazo. Y el significado de una nota depende totalmente de lo que vino antes y de lo que viene después.
Beto
El contexto lo es todo.
Alicia
Precisamente. Un acorde de Do mayor suena alegre, ¿verdad? A menos que se toque después de una larga y disonante construcción aterradora; entonces suena a resolución o alivio.
Beto
Y es tan abstracta. Quiero decir, puedes describir objetivamente un gato a una máquina. Pero intenta describir la tristeza en un concierto para violonchelo a un ordenador que literalmente nunca ha sentido nada en movimiento.
Alicia
Es una pesadilla subjetiva para los científicos de datos.
Beto
Entonces, ¿cómo lo solucionan?
El Lenguaje de la Música
Eso nos lleva a la primera gran sección del artículo: el lenguaje de la música. Antes de que una IA pueda remezclar una canción o convertirla en vídeo, tiene que poder oírla realmente.
Alicia
Correcto. Y los autores lo dividen en dos campos principales: representaciones de audio y representaciones simbólicas.
Beto
Piénsalo como la grabación frente a la partitura.
Alicia
Es una excelente forma de decirlo.
Beto
Empecemos por el lado de la grabación, el audio bruto. ¿Cómo escucha una máquina?
Alicia
La forma más básica es la forma de onda. Si alguna vez abriste un archivo de audio en un editor o miraste una nota de voz en tu teléfono, has visto esto: esas líneas dentadas que se mueven de izquierda a derecha.
Beto
Sí, las ondulaciones.
Alicia
Exacto. Es simplemente la amplitud en función del tiempo. La señal cruda de la onda sonora.
Beto
¿Pero puede la IA aprender a partir de eso? Parece demasiado desordenado.
Alicia
Puede, pero los modelos de deep learning realmente luchan con ello porque los datos son de muy alta dimensión. Es abrumador. Así que los investigadores suelen convertir ese sonido en una imagen.
Beto
Transforman sonido en imagen.
Alicia
Sí: un espectrograma. Parece un mapa de calor. El tiempo en el eje X, la frecuencia o alturas en el eje Y, y el color muestra cuán fuerte está esa frecuencia en ese momento. De pronto conviertes un problema temporal en un problema de imagen.
Beto
Y la IA ya es muy buena “mirando” imágenes.
Alicia
Exacto. Aprovecha toda la tecnología de visión por computadora que ya existe.
Beto
Pero el artículo sostiene que los espectrogramas estándar no bastan del todo para la música. Mencionan algo llamado espectrograma log-mel.
Alicia
Esa es una distinción crucial. Un espectrograma estándar trata todas las frecuencias por igual. Pero el oído humano no lo hace para nada.
Beto
¿A qué te refieres?
Alicia
Somos muy sensibles a cambios en las notas graves. Podemos distinguir fácilmente entre un Mi grave y un Fa grave. Pero en las frecuencias muy altas no podemos diferenciar bien entre 10.000 Hz y 10.050 Hz.
Beto
Suena igual, un agudo chillón de todos modos.
Alicia
Correcto. Entonces el espectrograma log-mel ajusta los datos visuales para que coincidan con la percepción humana. “Aplasta” las frecuencias altas y estira las bajas. Literalmente imita nuestra biología.
Beto
Así que enseña al ordenador a priorizar los sonidos que a los humanos realmente les importan.
Alicia
Precisamente. Pero incluso eso no es el estándar absoluto para la música específicamente. Si quieres que la IA entienda melodía y armonía, el artículo apunta a la CQT.
Beto
La Transformada de Q constante. ¿Por qué la CQT gana frente al espectrograma log-mel?
Alicia
Porque los espectrogramas estándar y los log-mel operan en escalas lineales o perceptuales, pero ninguna de esas se alinea perfectamente con la teoría musical. En una vista estándar, la distancia física entre un Do bajo y el siguiente Do más alto se ve diferente dependiendo de dónde estés.
Beto
Ah, ya veo. No está espaciado uniformemente.
Alicia
Correcto. Pero la CQT usa una escala logarítmica que se alinea específicamente con los semitonos musicales.
Beto
Así que en un mapa CQT, una octava siempre se ve a la misma distancia visual.
Alicia
Sí. Alinea los datos visuales con la escala musical real. Elimina todo el “borroneo” que obtienes con otros métodos. Si entrenas una IA para reconocer una progresión de acordes, la CQT es como ponerle gafas: hace que la estructura armónica resalte claramente.
Beto
Muy bien. Así es como la IA trata el sonido bruto: lo mapea visualmente.
Pero luego está el otro campo, la representación simbólica, la partitura. Y el obvio aquí es MIDI.
Alicia
El buen y viejo MIDI. Ha sido el estándar de la industria desde los años 80.
Beto
Mi primer teclado tenía puertos MIDI.
Alicia
El de todos. MIDI son solo instrucciones. Le dice al ordenador: toca la nota 60 con velocidad 100 durante dos segundos. Es muy eficiente. Pero el artículo apunta un fallo importante para el entrenamiento de IA: MIDI es dato de interpretación, no de estructura.
Beto
Correcto. No sabe qué es un compás.
Alicia
O un tiempo ni una armadura. Es solo un flujo de eventos independientes. Así que los investigadores desarrollaron tokens mejorados, REMI.
Beto
MIDI “reformado”.
Alicia
Sí. Insertan tokens especiales en la secuencia de datos que literalmente dicen “nuevo compás” o “posición uno”. Obligan a la IA a entender la rejilla rítmica de la canción, no solo cuánto dura una nota.
Beto
Pero la representación que realmente me llamó la atención en esta sección y, honestamente, la que me hizo detenerme y mirar fijamente fue la notación ABC.
Alicia
Oh, me encanta la notación ABC. Es un ejemplo perfecto de pensamiento lateral en informática.
Beto
Explícaselo al oyente porque suena casi demasiado simple para ser de alta tecnología.
Alicia
Es simple. La notación ABC representa la música usando texto ASCII estándar. Las notas son literalmente letras del teclado: A, B, C, D. Puedes denotar sostenidos, bemoles, duraciones de nota, todo con puntuación y caracteres estándar.
Beto
Y estás esencialmente escribiendo una sinfonía con un teclado normal.
Alicia
Exacto. Pero aquí está por qué esto es completamente revolucionario para la IA: tenemos enormes modelos de lenguaje, los cerebros detrás de ChatGPT o Claude, que se han “tragado” básicamente todo el texto disponible en internet.
Beto
Son increíblemente buenos con texto.
Alicia
Son maestros prediciendo la siguiente palabra en una oración.
Beto
Al convertir la música a notación ABC ...
Alicia
Conviertes la música en texto. Puedes alimentar una melodía a una IA basada en texto y puede leer y escribir música como si fuera inglés o francés. Evita la necesidad de procesamiento de audio complejo por completo. Simplemente trata una melodía como una narrativa.
Beto
Eso conecta totalmente los puntos para mí. Está aprovechando el mayor avance en IA que tenemos ahora mismo, los grandes modelos de lenguaje, y solo adapta la música para caber en sus cerebros existentes.
Interacción Dirigida por Música
Alicia
Lo que nos lleva perfectamente a la siguiente gran sección de la revisión: la interacción dirigida por la música. Aquí la música no solo se limita a ser analizada; se convierte en la jefa. Dirige la generación de otros medios.
Beto
Correcto: cuando la música manda, veamos música a texto. Esto es muy útil para catalogar bibliotecas enormes.
Alicia
Enormemente. Lo llamamos “captioning” musical (generación de descripciones musicales). Le das un archivo de audio a la IA y te devuelve una descripción: "piano jazz animado, tono sombrío subyacente y batería con escobillas".
Beto
El artículo menciona modelos como MusCaps y MusiLingo. ¿Cómo hacen esto? ¿Solo buscan etiquetas de metadatos?
Alicia
No; usan esa comprensión cruzada de modalidades. Escuchan la textura acústica del sonido, el tempo, la instrumentación y traducen esas características matemáticas de audio en palabras semánticas.
Pero el desafío mucho más duro aquí son las transcripciones de letras.
Beto
No, espera: tenemos reconocimiento de voz en el móvil. Lo uso para enviar mensajes todos los días. ¿Por qué cantar es mucho más difícil de transcribir?
Alicia
Es el problema de la fiesta con cóctel, pero aumentado. En el habla, las palabras se pronuncian con relativa claridad, en ritmo estable y a menudo en aislamiento. En la música, las vocales se alargan durante cinco segundos. El tono sube y baja constantemente, y hay una batería golpeando platillos y una guitarra distorsionando encima de la voz.
Beto
Tienes que separar la señal del ruido.
Alicia
El artículo destaca una herramienta llamada LyricWhiz. Es muy ingeniosa. Usa el modelo Whisper de OpenAI para la transcripción cruda, pero luego lo empareja con GPT-4 para corregir contextualmente los errores.
Beto
¿Cómo funciona eso en la práctica?
Alicia
Si la transcripción cruda oye “sweet dreams are made of cheese”, ...
Beto
... un error clásico ...
Alicia
Correcto. GPT‑4 entra y dice, mirando el resto de la canción, que probablemente sea “these” y no “cheese”.
Beto
Inteligente. Pero saber qué se dijo es totalmente distinto a saber cuándo se dijo.
Alicia
Exacto. Eso es la alineación, con precisión al milisegundo. Una cosa es saber que el cantante dijo la palabra “amor”; otra muy distinta es saber en qué cuadro de vídeo cae esa palabra si estás construyendo una app de karaoke o un generador de vídeos musicales IA.
Música a Baile
Beto
Hablando de moverse al ritmo, hablemos de mi gráfico favorito del artículo: música a baile.
Alicia
Coreografía por IA.
Beto
He visto versiones tempranas en línea en las que los avatares parecen, bueno, simplemente agitarse salvajemente. Pero la tecnología ha mejorado.
Alicia
Drásticamente. Y el desafío central es que bailar no es solo movimiento; es movimiento limitado por el ritmo. Tienes que marcar el golpe. El artículo discute un modelo llamado Bailando.
Beto
Que es un nombre fantástico, por cierto.
Alicia
Realmente lo es. Bailando utiliza un “codebook” de movimientos de baile cuantizados. Imagina un vocabulario de gestos: un meneo de brazo, un paso característico, un movimiento de hip‑hop.
Beto
Una especie de diccionario de baile.
Alicia
Exacto. Bailando escucha la música, encuentra el pulso, y enlaza esas “palabras” del vocabulario para crear una frase coherente de movimiento.
Beto
Pero el artículo mencionó un problema físico raro en los modelos iniciales: el deslizamiento.
Alicia
Ah, sí. El "efecto Michael Jackson", pero sin intención. Los modelos tempranos no entendían gravedad ni fricción. La IA decía “mueve el pie del punto A al punto B” pero no le indicaba al avatar que primero levantase el pie.
Beto
Así que los bailarines parecían deslizarse por el suelo como si hubiera hielo invisible.
Alicia
Exacto. ¿Cómo lo solucionaron? Los modelos más nuevos como EDGE usaron difusión, la misma técnica de los generadores de imágenes IA, pero además incorporaron restricciones físicas estrictas. Obligan a la IA a calcular el contacto del pie con el suelo. Tiene que “sentir” matemáticamente el piso.
Beto
También hay que acertar con el género. No quieres que la IA haga un vals lento para una caída masiva de dubstep.
Alicia
Ahí entran las redes de tokens de género. La IA identifica primero la etiqueta de género, por ejemplo hip‑hop, y entonces restringe su movimiento y la librería a movimientos que encajan en ese estilo. Filtra las piruetas de ballet antes de empezar a coreografiar.
Beto
Tiene sentido. Así que la música genera texto y baile. ¿Qué hay de música a vídeo?
De Música a Vídeo
Alicia
Hay dos vías principales. Una es el montaje/edición. Piensa en herramientas como AudeoSynth. Les das una carpeta de clips de vídeo sin pulir y una canción. Analiza los tiempos, los picos de energía, el ánimo general. Y corta los clips automáticamente para que encajen perfectamente con la pista.
Beto
La herramienta definitiva para crear TikToks.
Alicia
Básicamente, sí. La otra vía es la generación de interpretación. Esto es fascinante: crear un avatar virtual que realmente toque un instrumento.
Beto
Como un personaje animado que toca una guitarra real.
Alicia
Sí. Pero la animación está dirigida completamente por la entrada de audio. La IA oye una pista compleja de violín y calcula exactamente cómo tendría que moverse el brazo del arco y los dedos en el diapasón para producir esos sonidos.
@art_for_joy1 Pachelbel's Canon🎶 piano and ghost violin duet. This music is often used for both weddings and funerals all text to video using new version 3 from @PixVerse incredible prompt adherence 🙌 #fyp #canonind #piano #violin #duet #ai #aiart #aimusicvideo #pixversev3 ♬ original sound - Art
Beto
Wow. Está ingenierizando al revés la acción física a partir del resultado acústico.
Alicia
Exacto. Deduce la causa a partir del efecto.
De Texto a Música
Beto
Hemos hablado de la música como entrada. Ahora cambiemos el guión: sección tres del artículo, que es lo que realmente está rompiendo internet ahora mismo: interacción orientada a la música. La música como salida. Texto a música.
Alicia
Este espacio ha evolucionado increíblemente rápido. Hace apenas dos años, si escribías “canción acústica triste” en un prompt, la IA buscaba en una base de datos y recuperaba un archivo preexistente. Ahora genera una canción nueva desde cero.
Beto
Entonces, cuando escribo “línea de bajo funky con un sintetizador espacial”, ¿qué está haciendo la IA en segundo plano?
Alicia
Depende de la arquitectura. El artículo divide los pesos pesados en dos categorías: generación simbólica y generación de audio.
Beto
Lo simbólico es la parte de la partitura otra vez, ¿no?
Alicia
Correcto. Modelos como MuseCoco o ChatMusician trabajan con notación ABC o tokens MIDI. Tratan de componer una canción como escribir un ensayo: predicen la siguiente nota basándose en las anteriores.
Ejemplo con ChatMusician
Beto
Pero los grandes modelos, los que suenan como grabaciones reales en Spotify, ¿usan MIDI?
Alicia
No. Están haciendo generación de audio directa. Y aquí el artículo distingue entre dos grandes familias: modelos autoregresivos y modelos de difusión.
Beto
Desglosemos porque esos términos se lanzan mucho en noticias de IA.
Autoregresivos primero. El artículo menciona MusicGen de Meta.
MusicGen en acción
Alicia
Piensa en los autoregresivos como un auto‑completar super avanzado. Es como escriben los modelos de texto. Predicen la siguiente palabra basándose en las anteriores. MusicGen hace exactamente lo mismo pero con sonido. Divide el audio en codebooks, esos tokens comprimidos de sonido crudo.
Beto
Entonces construye la canción corte por corte microscópico. ¿Así que está creando la canción segundo a segundo?
Alicia
Sí. Mira el primer segundo y pregunta, estadísticamente y según el prompt “línea de bajo funky”, qué sonido acústico viene después. Y sigue así. Es muy bueno manteniendo una melodía porque siempre mira hacia atrás a lo que acaba de tocar para decidir qué sigue.
Beto
Y la otra familia, Difusión.
Alicia
Esta es la que usan modelos como Riffusion y Stable Audio. Si sabes cómo DALL·E o MidJourney generan imágenes, sabes este proceso. Empiezan con puro ruido. Simplemente estática aleatoria.
Beto
Caos total.
Alicia
Luego, guiados por tu prompt, van deshaciendo el ruido gradualmente. Van esculpiendo la estatua desde el bloque de mármol. Pero aquí está el truco, y esto conecta con nuestra primera sección: no están esculpiendo sonido directamente, están esculpiendo un espectrograma.
Beto
Volvemos a las imágenes.
Alicia
Sí. Generan una imagen del sonido, píxel por píxel, y al final convierten esa imagen de nuevo en un archivo de audio. Es como hackear la corteza visual de la IA para hacer música.
Beto
Se siente como haciendo trampa. Toma procesamiento visual y lo reutiliza para audio.
Alicia
Funciona increíblemente bien.
Y tenemos que mencionar el momento Suno y Udio. El artículo cita específicamente estas herramientas porque representan un gran salto en realismo.
Beto
Porque añadieron voces.
Alicia
Voces emotivas y de alta calidad. Hasta entonces, la música IA era sobre todo instrumental, pistas de fondo para estudiar o beats lo-fi. Pero herramientas como Suno y SongComposer descubrieron cómo generar canciones completas y cohesionadas: letra, melodía, armonía compleja y voces principales a partir de un solo prompt de texto.
Beto
Y no es solo una voz robótica encima; la voz se quiebra, respira en los lugares correctos, añade vibrato.
Alicia
Es fluida.
¿Cómo funciona?
Y eso nos lleva a la sección de panorama general del artículo: ¿cómo funciona esto realmente por dentro? ¿Cómo conectas la palabra inglesa “dog” con el sonido de un ladrido?
Beto
Esa es la sala de máquinas de toda la operación.
Alicia
Lo es. El concepto central es la representación conjunta multimodal.
Beto
Desenmarañémoslo.
Alicia
Imagina un enorme mapa multidimensional compartido. Un espacio de características común. Entrenar estos modelos consiste en forzar que la representación matemática de la palabra “dog” y la representación matemática del ladrido de un perro vivan en la misma coordenada de ese mapa.
Beto
Para la IA son exactamente el mismo concepto, solo almacenado en distintos formatos.
Alicia
Exacto. Modelos como MuLan o CLAP están diseñados para mapear ese espacio compartido. Sin ese puente fundamental no puedes traducir texto a música ni música a baile. Necesitas un lenguaje universal al que todo traduzca primero.
Beto
Es la piedra de Rosetta para la IA.
Alicia
Lo es, realmente. Es enorme, pero no perfecto. El artículo enumera obstáculos significativos que aún enfrentamos.
Beto
Adivina cuál es el número uno. Los derechos de autor, el copyright.
Alicia
Es el elefante en la habitación. Para entrenar estos modelos necesitas enormes cantidades de música multitrack de alta calidad. Y a diferencia de las imágenes, donde históricamente podías raspar la web, no puedes raspar Spotify sin preocuparte por demandas de las discográficas.
Beto
Y necesitas los stems, ¿verdad? Necesitas las voces aisladas y las pistas de batería aisladas para entrenarlo bien.
Alicia
Que son increíblemente difíciles de encontrar públicamente y de forma legal. Así que la escasez de datos es un cuello de botella real ahora mismo.
Luego está el problema de la subjetividad. Lo tocamos antes. La música es profundamente emocional.
Beto
¿Cómo sabe una IA si un prompt pide algo “agridulce”?
Alicia
Lo pasa mal. No hay una fórmula matemática para “agridulce”. Es cultural, extremadamente contextual. Un ordenador puede identificar fácilmente una tonalidad menor, pero no puede sentir la diferencia entre una canción triste y una espeluznante sin muchas etiquetas matizadas.
Beto
¿Y qué pasa con la estructura real de las canciones? He notado que muchas canciones generadas por IA suenan asombrosas durante unos 30 segundos y luego se desmadran. Empiezan a divagar.
Alicia
Sí. Ese es el problema de estructura a largo plazo. La IA es asombrosa para el ahora. Es genial prediciendo el próximo segundo de audio. Pero mantener una canción coherente, verso, estribillo, verso, puente, estribillo, durante tres o cuatro minutos requiere memoria y planificación.
Beto
Olvida el tema musical con el que empezó.
Alicia
Exacto. Los modelos actuales tienden a “alucinar” ideas nuevas en lugar de volver al motivo principal. Tienen la capacidad de atención de un pez dorado. Pero los investigadores trabajan activamente en modelos jerárquicos para solucionar esto, básicamente dando a la IA un plan global u esquema antes de que empiece a escribir las notas individuales.
Beto
De acuerdo. Hemos cubierto el lenguaje, las formas de onda, la CQT, la notación ABC. Hemos cubierto la música conduciendo visuales como baile y vídeo. Y hemos cubierto texto conduciendo la música con cosas como MusicGen, Suno y otras.
Alicia
Pinta una imagen vívida de convergencia. Todos estos medios se están fusionando.
Beto
Lo hacen. El cierre del artículo enfatiza ese difuminado de fronteras. La música ya no es solo sonido. Es datos fluidos que pueden verterse en cualquier contenedor.
Alicia
Y eso nos lleva a un concepto final realmente interesante que mencionan los autores, y que me parece profundo: la percepción del agente musical.
Beto
¿Qué implica eso para el futuro?
Alicia
Implica una IA que no solo genera o clasifica en aislamiento. Percibe y actúa como un agente autónomo completo. Una IA que escucha la melodía que tarareas, entiende el ánimo que quieres, escribe la letra, compone la armonía, canta las voces y luego coreografía el videoclip como un acto creativo unificado.
Beto
Cambia por completo el papel humano.
Alicia
Desplaza totalmente el centro de gravedad del arte. Si la máquina puede encargarse de la interpretación virtuosa y de la composición técnica, el papel humano deja de ser habilidad, saber mover los dedos rápido en un diapasón, y se convierte enteramente en intención.
Beto
Te vuelves el director.
Alicia
El curador, el visionario. Ya no tocas la guitarra físicamente; diriges a la IA para que la toque un poco más agresiva, o con un timbre más cálido.
Beto
Es un cambio de esfuerzo físico a selección creativa.
Alicia
Lo cual es increíblemente liberador para quienes tienen ideas pero tal vez no la destreza manual o años de entrenamiento.
Pero, por supuesto, también plantea enormes preguntas sobre qué valoramos realmente en el arte.
Beto
Me deja con un pensamiento con el que quiero que te quedes: si una IA puede analizar perfectamente los patrones matemáticos que provocan la emoción humana; si sabe exactamente qué progresión de acordes nos hace llorar y qué ritmo nos hace bailar, y puede ejecutarlo perfectamente cada vez, ¿importa que no haya alma detrás?
Alicia
Esa es la pregunta definitiva. ¿Está la emoción localizada en la creación de la pieza o está puramente en la recepción por parte del oyente?
Beto
Algo para masticar la próxima vez que te encuentres moviendo el pie con una canción que podría no haber sido escrita por un humano en absoluto.
Un enorme gracias a Li, Tan y al equipo de investigación por esta completísima revisión. Es una lectura densa, pero increíblemente esclarecedora.
Alicia
Absolutamente. Una verdadera mirada al futuro de la creatividad.
Beto
Gracias por acompañarnos en este análisis profundo. Nos vemos en el próximo.



{kind=link}