
El texto presentado describe una propuesta para una web centrada en el agente, argumentando que la arquitectura actual de internet es fundamentalmente errónea porque presupone usuarios humanos en lugar de agentes de IA. Los autores diagnostican fallos en tres niveles: acceso, economía y contenido, señalando que los agentes actualmente están bloqueados o se consideran amenazas extractivas. Para resolver esto, proponen un marco donde los agentes que actúan en nombre de los humanos heredan derechos de acceso equivalentes, gestionados mediante nuevos estándares de metadatos y limitación de velocidad en lugar de un bloqueo generalizado. Desde el punto de vista económico, el texto sugiere abandonar el modelo basado en la atención y adoptar un sistema de suscripción basado en tokens que reconozca al agente como un representante humano. Para proteger la integridad de la información, los autores introducen el Lenguaje de Marcado de Texto para Agentes (ATML) y una cadena de procedencia criptográfica para evitar la recursión epistémica, donde el contenido generado por IA retroalimenta los bucles de entrenamiento de la IA. En definitiva, el documento busca renegociar el contrato social de la web para integrar a los agentes de IA como ciudadanos de primera clase, preservando al mismo tiempo la verdad fundamental generada por los humanos.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "Towards an Agent-First Web: Redesigning the Web for AI Agents", por Eranga Bandara y colegas. Publicado el 17 de Junio de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
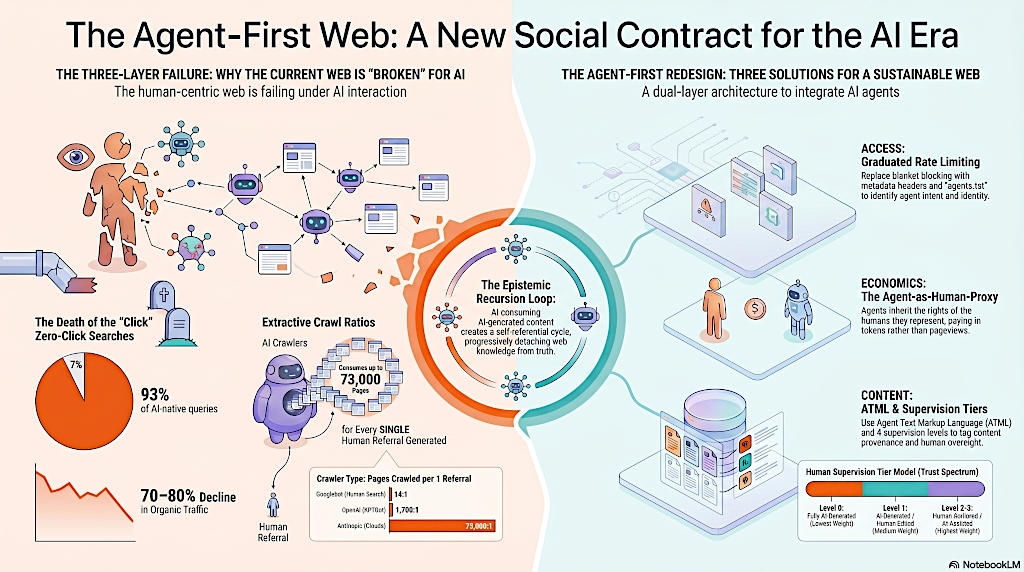
Ahora mismo, algo como el 93% de las búsquedas nativas de IA resultan en cero clics para el sitio web real que proporcionó la información.
Beto
Un cero, es asombroso.
Alicia
Lo es. Haces una pregunta. La IA lee todo internet por ti. Sintetiza esta respuesta perfecta. Y nunca visitas la fuente.
Beto
Lo cual es genial para el usuario.
Alicia
Oh, absolutamente. Es mágico. Es totalmente libre de fricciones. Pero para las personas que realmente crean esa información, es un desastre completo. Quiero decir, los grandes editores están llamando esto "un evento de nivel de extinción" para internet tal como la conocemos.
Beto
Y no están exagerando. Quiero decir, es un colapso estructural completo de la economía digital en la que básicamente hemos confiado durante las últimas tres décadas.
Alicia
Correcto.
Beto
Estamos viendo cómo la arquitectura fundamental de la web se rompe en tiempo real bajo el peso de la inteligencia artificial.
Alicia
Así que, para esta inmersión profunda, estamos desarmando un artículo de investigación preliminar muy fascinante y masivo publicado el 17 de junio de 2026.
Beto
Un artículo muy esperado.
Alicia
Oh, sí. Se titula "Rediseño de la web para agentes de IA: Rediseñando la web para agentes de IA". Y está compuesto por esta enorme coalición de laboratorios tecnológicos e investigadores universitarios.
Beto
Correcto.
Alicia
Así que, nuestra misión hoy es básicamente doble.
Primero, necesitamos entender la mecánica de por qué la web, centrada en el ser humano, se está desmoronando.
Y segundo, queremos explorar el gran plano de tres capas de los investigadores para construir lo que llaman "la web de agentes de IA".
Red para Agentes de IA
Beto
Porque la realidad es que la web simplemente no puede sobrevivir en su forma actual. No estamos hablando de una caída temporal en el tráfico web.
Alicia
Correcto. Como un mal trimestre o algo así.
Beto
Exacto. Estamos hablando de una crisis arquitectónica. Requiere básicamente desgarrar internet hasta los cimientos y reescribir las reglas fundamentales de cómo se accede, financia y estructura la información.
Alicia
Bien, desglosémoslo porque si estás escuchando esto ahora mismo, definitivamente usas herramientas de IA todos los días. Pero estás a punto de comprender la guerra de infraestructura invisible que está sucediendo detrás de cada "prompt" que escribes.
Beto
Sucede constantemente en segundo plano.
Alicia
Exacto. Así que empecemos con el diagnóstico. ¿Por qué es la web humana tan singularmente vulnerable a los agentes de IA?
Beto
Bueno, para entender realmente la vulnerabilidad, tienes que mirar la suposición fundamental incrustada en la World Wide Web cuando fue inventada en 1989. Todo el sistema, los servidores, los navegadores, el código subyacente, todo se construyó sobre la premisa de que la entidad al otro lado de la pantalla es un ser humano.
Alicia
Correcto.
Beto
Un humano que opera a una velocidad humana lenta, que procesa información visualmente y, lo más importante, que tiene una capacidad de atención humana que realmente puede ser monetizada.
Alicia
Y esa monetización, quiero decir, es el núcleo absoluto de la economía de la atención. Toda la máquina funciona solo con vistas de página, impresiones de anuncios y clics de afiliación.
Beto
La economía de la atención depende totalmente de este ciclo de valor cerrado. Así que un editor gasta tiempo y dinero creando un artículo. Tú, como humano, navegas hasta su sitio para leerlo.
Alicia
Correcto.
Beto
Y mientras estás allí, ves anuncios de banner o quizás haces clic en un enlace patrocinado, el anunciante paga al editor por tu atención. Y luego el editor usa esa facturación para financiar el artículo de mañana.
Alicia
Genial.
Beto
Pero cuando un agente de IA entra en ese ecosistema en tu nombre, rompe violentamente ese ciclo.
Alicia
Porque la IA no tiene ojos para ver un anuncio de banner, ¿verdad? Y ciertamente no tiene una billetera para comprar cualquier producto de afiliación que esté siendo promovido.
Beto
Exacto. Simplemente extrae el texto sin procesar. Lo analiza, lo sintetiza y te lo entrega de vuelta en una ventana de chat.
Alicia
Así que todo valor sin costo.
Beto
Correcto. El valor entregado es inmenso. Pero el valor devuelto al editor que realmente generó ese conocimiento es cero absoluto.
Alicia
Y la escala de esa extracción, quiero decir, eso es lo que realmente me dejó asombrada en la investigación. Hay una métrica en el artículo que llaman "la proporción de rastreo a referencia" ("crawl to referral ratio").
Beto
Sí, ese punto de datos es salvaje.
Alicia
Lo es. En la era de los motores de búsqueda tradicionales, había una especie de contrato social tácito, ¿verdad? Googlebot rastreaba las páginas de un sitio web, las indexaba y, a cambio, enviaba tráfico humano.
Beto
Una relación simbiótica.
Alicia
Exacto. Históricamente, Googlebot rastreaba unas 14 páginas por cada referencia humana que generaba para un sitio, lo cual parece justo.
Pero luego el artículo mira los datos de mediados de 2025.
Beto
Aquí es donde se vuelve loco.
Alicia
Sí. El rastreador de Anthropic llega a 73,000 rastreos por una sola referencia humana.
Beto
Quiero decir, desde una perspectiva de infraestructura, eso ya no es indexación de búsqueda. Eso es una operación de minería de superficie a escala industrial y unidireccional.
Alicia
Correcto.
Beto
El rastreador solo está recogiendo gigabytes de datos propietarios para entrenar modelos y servir esas respuestas de cero clics, ofreciendo absolutamente ninguna compensación económica a cambio.
Alicia
Ok. Para poner esto en términos humanos, imagina que eres dueño de una boutique de ropa local.
Beto
Ok.
Alicia
El viejo Googlebot era básicamente como un tipo amable que ocasionalmente entraba en tu tienda, miraba tu inventario y luego se paraba en una esquina concurrida de la calle repartiendo folletos para dirigir clientes que pagaran directamente a tu puerta.
Beto
Suena como un gran tipo.
Alicia
Correcto. Pero el modelo actual del rastreador de IA es una bestia completamente diferente. Es más como, bueno, es como un comprador personal que entra en tu boutique, toma fotos macro de alta definición de las costuras de cada prenda, vuelve a casa, usa una impresora 3D industrial y máquinas de coser automatizadas para crear réplicas perfectas para sus clientes ricos, y nunca compra ni un solo hilo de tu tienda.
Beto
Y mientras ese comprador personal está proporcionando este servicio increíblemente personalizado a su cliente, están llevando simultáneamente a la boutique a la bancarrota.
Alicia
Exacto. Lo cual honestamente plantea una pregunta obvia para mí. Si yo soy la editora o la dueña de la boutique en el escenario, ¿por qué dejo la puerta principal abierta? Si los bots estuvieran minando mi sitio, por qué no configuraría mi servidor para bloquear cada dirección IP automatizada?
Beto
Bueno, los editores están haciendo exactamente eso. Quiero decir, por pura autopreservación. Para 2025, Cloudflare, que accede al guardián de seguridad para una gran parte de internet global, comenzaron a lanzar herramientas para bloquear rastreadores de IA por defecto.
Alicia
Correcto.
Beto
Básicamente trataron cualquier acceso de agente como una extracción comercial hostil en lugar de una visita legítima.
Pero el bloqueo binario, ya sabes, simplemente cerrando el cerrojo, es un vendaje temporal.
Alicia
No es una solución real.
Beto
No, no es una solución arquitectónica sostenible en absoluto. Porque el servidor ahora no puede diferenciar entre un rastreador comercial de un billón de parámetros y tu asistente digital personal.
Alicia
Ah, ok. Así que si pago una suscripción a un sitio de noticias financieras, y pido a mi IA personal que me resuma un informe de ganancias de ese sitio, el servidor simplemente ve a un bot y lo bloquea, aunque yo sea un suscriptor de pago.
Beto
Exacto. Ese es el daño colateral de un enfoque de cerrojo. Tienes derecho legal a leer ese artículo, pero tu proxy designado queda bloqueado.
Alicia
Así que la puerta misma está básicamente rota. Necesitamos una nueva puerta principal que realmente pueda leer la intención de la IA que la está llamando.
Beto
Sí.
Alicia
Y eso conduce perfectamente a la primera capa del gran plano del investigador, el rediseño de la capa de acceso.
Beto
Correcto. Así que la filosofía fundamental para esta capa es algo que los investigadores llaman "el principio del agente como proxy humano".
Alicia
Lo que significa ¿qué exactamente?
Beto
Dicta que un agente de IA que actúe en nombre de un usuario debe heredar los mismos derechos de acceso que ese usuario. Nada más, nada menos.
Alicia
Ok.
Beto
Así que si un blog público es gratuito para leer, tu agente debe poder leerlo. Si tienes una suscripción digital premium a un periódico, tu agente debe heredar esa autorización.
Alicia
Me encanta eso. Y la mecánica técnica de cómo proponen implementar esto es simplemente fascinante. Porque actualmente la web depende de este sistema de honor desde 1994 llamado "robots.txt".
Beto
El viejo sistema de honor.
Alicia
Sí. Es esencialmente solo un archivo de texto sentado en un servidor que actúa como una señal de "por favor, no pises el césped". Los rastreadores legítimos lo respetan. Los actores malintencionados simplemente lo ignoran por completo.
Beto
Correcto.
Alicia
Así que el artículo propone arrancarlo por completo y reemplazarlo con un estándar de "agentes.txt", que está integrado con encabezados HTTP dinámicos. Así que cuando una IA solicita una página web, debe transmitir metadatos que declaren exactamente a quién representa y su intención específica.
Beto
Sí.
Alicia
¿Está extrayendo datos para la solicitud personal de un solo usuario? ¿O es un bot comercial que rastrea datos para entrenar un nuevo modelo fundacional masivo?
Beto
Y esa declaración de intención es realmente el primer paso crucial. Pero el mecanismo que realmente permite que tu agente personal lea contenido de pago depende del "token de delegación" ("OAuth delegation token").
Alicia
Espera, ese es el protocolo que corre detrás de escena cuando usas tu cuenta de Apple o Google para iniciar sesión en una aplicación de terceros aleatoria. Simplemente pasa una clave segura para que no tengas que crear una nueva contraseña.
Beto
Esa es la tecnología subyacente exacta.
Alicia
Sí.
Beto
Así que bajo este nuevo marco, iniciarías sesión en tu nueva suscripción, autenticarías a tu asistente de IA específico y el servidor generaría un token de delegación limitado en el tiempo.
Alicia
Entendido.
Beto
Luego, cuando tu IA se acerque al sitio más tarde para leer un artículo por ti, presenta ese token en su solicitud HTTP. El servidor web valida el token, reconoce que el bot representa a un humano pagador y sirve el contenido.
Alicia
Oh, wow.
Beto
Sí. No se requiere suscripción de bot del servidor.
Alicia
Eso es súper elegante. Pero tengo un problema importante con depender de un modelo de intención declarada, sin embargo.
Beto
Ok. ¿Cuál es?
Alicia
Bueno, ¿qué está impidiendo que una compañía de IA masiva multimillonaria simplemente programe su rastreador comercial para mentir?
Beto
Correcto.
Alicia
Podrían simplemente adjuntar una etiqueta de metadatos de asistente personal a su bot, eludir las defensas del servidor por completo y rastrear millones de artículos gratis.
Beto
Esto plantea una pregunta importante, y es exactamente la vulnerabilidad de cualquier sistema de autoinforme.
Pero los investigadores anticiparon este comportamiento adversarial. De hecho, se basaron en lecciones de los primeros días del spam por correo electrónico.
Alicia
Oh, interesante.
Beto
Sí. Para evitar que un agente se haga pasar por otra identidad, el plano requiere que todos los encabezados de metadatos del agente sean firmados criptográficamente usando criptografía de clave pública.
Alicia
Así que no es solo una etiqueta de nombre que llevan puesta. Es una firma digital verificable matemáticamente.
Beto
Exacto. Cuando una compañía de IA pone en marcha un agente, utilizan una clave criptográfica privada para firmar las solicitudes del agente. El servidor web que recibe la solicitud comprueba esa firma contra el registro de clave pública descentralizado. Esto prueba matemáticamente que el agente realmente pertenece a la entidad que pretende representar.
Alicia
Ok, pero ¿qué pasa si un rastreador comercial es atrapado forjando firmas para pretender ser un bot personal?
Beto
Entonces su clave pública es revocada del registro global. Instantáneamente, todo servidor web en la Tierra que se suscriba a ese estándar pierde su acceso hasta cero absoluto.
Alicia
Oh.
Beto
Están completamente exiliados de internet. La pura amenaza económica de la gestión global forza un cumplimiento masivo.
Alicia
Eso tiene todo el sentido.
Beto
Y una vez que los servidores pueden confiar realmente en la identidad de los bots, la web puede cambiar su postura de seguridad. El predeterminado ya no es bloquear a todos los bots. El nuevo predeterminado es la limitación de tasa gradual basada en una identidad verificable.
Alicia
Ok. Así que un agente proxy personal obtiene una asignación gratuita de, digamos, 100,000 palabras al día. Un agente suscriptor verificado obtiene acceso ilimitado. Y un rastreador comercial pesado es automáticamente dirigido a una pasarela totalmente diferente, tal como un nivel negociado licenciado.
Beto
Exacto. Lo cual nos transiciona pulcramente a la realidad aquí. Un equilibrador más inteligente en la puerta no paga al camarero.
Alicia
Esa es una gran manera de decirlo.
Beto
La IA podría ser permitida dentro del sitio web ahora, pero aún no está haciendo clic en enlaces de afiliación ni viendo anuncios de banner. La economía de la atención sigue muerta.
Alicia
Correcto. Entonces, ¿cómo hace el editor dinero para mantener las luces encendidas? Y eso nos lleva a la segunda capa del plano, la nueva economía. Los investigadores proponen básicamente abandonar las vistas de página y pasar a un modelo económico basado en tokens.
Beto
Sí. Así que en la industria de la IA ahora, la computación se mide en tokens, que son solo fragmentos de texto o datos. Las empresas pagan por la potencia del servidor por millón de tokens procesados.
Alicia
Correcto.
Beto
El artículo argumenta que el consumo de contenido debe medirse exactamente de la misma manera. Cuando un agente de IA lee un artículo, el editor cobra una microtransacción basada en el número de tokens consumidos.
Alicia
Esto me recordó inmediatamente al ecosistema de software. Porque los editores finalmente pueden elegir explícitamente su arquitectura económica. Pueden operar como software de código abierto, haciendo su contenido gratuito para leer, pero muy limitado en la tasa para prevenir el abuso del servidor, como Wikipedia, conjuntos de datos gubernamentales o simplemente blogs aficionados.
Beto
Correcto.
Alicia
O pueden operar como software propietario, midiendo su contenido por token y cobrando realmente a la IA por el acceso.
Beto
Y esa diversidad estructural es crítica.
Porque forzar todo el contenido detrás de un muro de pago estricto destruye la web del conocimiento abierto.
Pero, por el contrario, forzar todo el contenido a permanecer gratuito destruye la viabilidad financiera del periodismo y la investigación profunda.
Alicia
Absolutamente. Pero solo hablando prácticamente, la infraestructura requerida para esto parece una pesadilla.
Beto
¿Cómo es eso?
Alicia
Bueno, si yo soy el usuario, y pido a mi IA que investigue un tema financiero realmente complejo, podría leer fragmentos de 50 artículos diferentes a través de 30 sitios web diferentes en como tres segundos.
Beto
Correcto.
Alicia
¿Recibiría mi tarjeta de crédito 30 microtransacciones individuales por fracciones de un céntimo? Quiero decir, ¿cómo no causa eso fricción masiva para el usuario?
Beto
Ahí es donde entra la capa de liquidación de la API. El usuario está totalmente protegido de las microtransacciones.
Alicia
Gracias a Dios.
Beto
Sí. Tú, el oyente, simplemente pagas tu tarifa plana de 20 dólares al mes a tu proveedor de IA, digamos OpenAI o Google. Detrás de escena, esos proveedores agregan el uso de tokens de sus millones de agentes.
Alicia
Ok.
Beto
Y al final del mes, el proveedor de IA ejecuta ambos liquidaciones financieras a través de API con un consorcio editorial. Tu suscripción de 20 dólares es efectivamente agrupada y fracciones de un céntimo se distribuyen algorítmicamente directamente a los editores de los que tu agente aprendió.
Alicia
Es algo similar a cómo Spotify agrega dinero de suscripción y paga fracciones de un céntimo por reproducción a los artistas, pero sabes, aplicado a toda la base de conocimiento de internet.
Beto
Mmm. El mecanismo es muy similar, sí. Pero hay un problema económico secundario que este modelo de tokens intenta resolver. Y es uno que es argumentablemente mucho más peligroso que solo la pérdida de ingresos por publicidad.
Alicia
¿Cuál es?
Beto
Es la inundación infinita de contenido generado por IA.
Alicia
Oh, cierto. Porque si a los editores les pagan por token consumido, ¿qué evita que un actor malintencionado use una IA barata para simplemente generar cien millones de artículos al día, inundando la web y quedarse para recolectar regalías por tokens cuando otros bots los lean?
Beto
Exacto. Así que el artículo introduce un concepto llamado "la economía de contenido encargado" ("commissioned content economy").
Alicia
Ok. ¿Qué es eso?
Beto
Bueno, en un ecosistema donde el texto es prácticamente gratis de generar, la mera existencia del texto pierde todo valor económico.
Alicia
Correcto. Oferta y demanda.
Beto
Exacto. Así que el nuevo producto premium se convierte en la intencionalidad humana. Para que una pieza de contenido sea económicamente viable, para que un servidor realmente esté dispuesto a pagarlo, una entidad humana debe anclarlo.
Alicia
Interesante.
Beto
Una sala de redacción, un laboratorio de investigación o incluso un experto individual debe comisionar económicamente el trabajo apostando su reputación criptográfica por su valor.
Alicia
Ok. Así que la recompensa económica no está ligada al número de palabras. Está ligada al riesgo humano y a la anclaje de reputación que da esa cuenta de palabras.
Beto
Precisamente. Crea una barrera de entrada financiera que neutraliza la ventaja de la generación infinita de IA.
Alicia
Vaya. Ok. Asumamos que la economía funcione. Los bots son identificados. Los editores están recibiendo pagos a través de API. Todavía tenemos un problema fatal con lo que la IA está consumiendo realmente.
Beto
Correcto. Los datos mismos.
Alicia
Sí. Lo cual nos lleva a la tercera y última capa del plano, la capa de contenido. Porque el formato actual de la web es fundamentalmente incompatible con el aprendizaje automático.
Beto
Lo es. HTML (Lenguaje de Marcado de Hipertexto) es la base de la web. Y fue diseñado completamente para la percepción humana.
Alicia
Correcto. Para los ojos.
Beto
Sí. Depende de un complejo modelo de objeto de documento o DOM, que básicamente le dice al navegador dónde poner la barra lateral de navegación, qué color hacer un botón y cómo escalar una imagen para una pantalla móvil.
Alicia
Y el artículo señala que todos esos datos visuales son esencialmente comida chatarra para una IA.
Beto
Comida chatarra completa.
Alicia
Correcto. Los investigadores calcularon que el HTML conlleva una sobrecarga de tokens del 67.6%. Eso significa que más de dos tercios de la potencia computacional y el ancho de banda que la IA gasta en ingerir una página web es desperdiciado, solo procesando instrucciones de diseño visual que ni siquiera puede percibir.
Beto
Y a escala planetaria, ese desperdicio se traduce en un consumo masivo de energía y latencia computacional. Es salvajemente ineficiente.
Alicia
Correcto.
Beto
Así que la solución propuesta es una web de doble capa impulsada por "el lenguaje de marcado de texto de agente HTML", ATML.
Alicia
Ok. Así que un servidor tendría esencialmente dos caras. Si navego a un artículo usando un navegador web tradicional, el servidor me detecta y me envía el archivo HTML visualmente rico.
Beto
Correcto.
Alicia
Pero si mi agente de IA solicita exactamente la misma URL, el servidor detecta los metadatos del agente y devuelve un archivo ATML en su lugar.
Beto
Correcto. Pero ten en cuenta que ATML no es solo HTML con el CSS eliminado. Es una arquitectura completamente diferente.
Alicia
Oh, ¿de verdad?
Beto
Sí. Estructura la información como un grafo de conocimiento semántico. Mapea explícitamente las relaciones entre entidades, puntos de datos y afirmaciones dentro del texto.
Esto permite a la IA ingerir pura lógica y hechos sin tener que inferirlos de párrafos legibles por humanos.
Alicia
Quiero decir, esa eficiencia estructural es genial, pero ATML sirve a un propósito mucho más oscuro y urgente en este plano, ¿no?
Beto
Absolutamente lo hace.
Alicia
Aquí es donde se pone realmente interesante. Introduce una capa de procedencia legible por máquina para combatir algo que los investigadores llaman "recursión epistémica".
Beto
Sí. Una recursión epistémica es, sin duda, la mayor amenaza a largo plazo para la integridad del conocimiento global. Es básicamente un bucle de retroalimentación autorreferencial.
Alicia
Como un salón de espejos.
Beto
Un salón inmenso de espejos. Sí. Los seres humanos escriben contenido original. Los modelos de IA se entrenan con ese contenido humano. Luego esos modelos se implementan para generar millones de nuevas páginas web.
Alicia
Correcto.
Beto
Luego la próxima generación de agentes de IA rastrea la web, rastreando ese texto generado por IA para entrenar modelos más nuevos o responder a peticiones de usuario. Cada vez que se repite ese ciclo, los artefactos estadísticos de la IA se amplifican. Los matices se aplanan por completo, y las alucinaciones se refuerzan como hechos de consenso.
Alicia
Y finalmente, el conocimiento basado en internet se despega por completo de la realidad humana física y sufre un colapso total del modelo.
Beto
Exacto. Para detener ese colapso, la IA absolutamente debe conocer el origen de los datos que está ingiriendo.
Alicia
Tiene que hacerlo.
Beto
Así que ATML se basa en un estándar criptográfico existente llamado C2PA para incrustar procedencia segura directamente en el archivo.
Alicia
Espera, C2PA, esa es la misma tecnología que los fabricantes de cámaras están empezando a usar para probar que una foto no fue generada por IA, ¿verdad?
Beto
Exacto. Utiliza enclaves seguros a nivel de hardware. Así que cuando un humano escribe en un dispositivo verificado o una sala de red produce un borrador finalizado, el sistema genera un "hash" criptográfico. Básicamente, una huella dactilar matemática única ligada a esa acción específica en ese momento concreto.
Alicia
Ok.
Beto
El archivo ATML lleva esa huella dactilar, clasificando el contenido en uno de cuatro niveles estrictos de supervisión.
Alicia
Correcto. Y así es como la IA sabe en qué confiar.
Estuve mirando estos niveles.
El Nivel 0 es contenido totalmente generado por una IA con cero supervisión humana. Esto obviamente conlleva el menor peso epistémico.
El Nivel 1 es generado por IA, pero editado por humanos.
El Nivel 2 es creado por humanos, pero asistido por IA. Así que tal vez una IA ayudó a organizar la investigación o algo así.
Y finalmente, el nivel 3 es totalmente escrito por humanos, rastreado desde las pulsaciones de teclas hasta la publicación final. Y eso conlleva la mayor confianza epistémica.
Beto
Y esa cadena criptográfica actúa como un disyuntor para el salón de espejos. Cuando tu asistente de IA está investigando, digamos, un síntoma médico para ti, y encuentra un archivo ATML, inmediatamente comprueba la firma criptográfica. Si el archivo afirma ser escrito por humanos de nivel 3, pero la matemática muestra que realmente deriva de lodo de IA de nivel 0, ...
Alicia
Tu agente sabe que debe rechazar los datos por completo.
Beto
Exacto.
Alicia
Es básicamente como comprar un diamante. Podrías comprar una piedra impecable en la calle, pero sin un certificado de autenticidad verificado, no tienes idea si tardó millones de años en formarse en la Tierra, o si tardó tres semanas en un laboratorio sintético.
Beto
Esa es una gran analogía.
Alicia
La capa de procedencia ATML es esencialmente el certificado de autenticidad para el pensamiento humano. Permite que una web saturada de IA exista sin que nosotros perdamos por completo nuestro control sobre lo que es real.
Beto
Y cuando sintetizas estas tres capas, el acceso, la economía y el contenido, empiezas a darte cuenta de la magnitud de lo que propone este artículo. Estamos renegociando activamente el contrato social de 1991 de internet.
Alicia
Porque el contrato antiguo era simple: navegadores humanos anónimos consumiendo HTML escrito por humanos a cambio de atención humana.
El nuevo contrato es una red de intención de agente verificada criptográficamente, financiada por liquidaciones API de tokens en bloque, consumiendo grafos de conocimiento HTML anclados por procedencia.
Beto
Es un cambio profundo, pero es el prerrequisito matemático para que la web realmente sobreviva a la transición a la inteligencia artificial sin canibalizarse económicamente y estructuralmente.
Alicia
Y para ti, oyente, esto no es solo la teoría académica abstracta. Esta internet de agentes de IA de doble capa es la fundación invisible que se está construyendo bajo tus pies en este preciso segundo, solo para soportar las herramientas en las que confiarás por el resto de tu vida.
Beto
La transición es totalmente inevitable. La única pregunta real es cuán elegantemente la ejecutemos.
Alicia
Pero, ya sabes, mirando este plano me deja con un pensamiento increíblemente inquietante que los investigadores no resuelven del todo.
Beto
Oh, ¿qué es eso?
Alicia
Bueno, si logramos hacer la transición a esta web ATML prístina y cerrada donde cada token es rastreado y cada pensamiento humano está firmado criptográficamente, ¿qué pasará con los miles de millones de páginas de basura de IA de nivel cero no verificadas que ya obstruyen internet hoy? ¿Terminaremos con dos internets completamente separadas?
Uno que sea una web humana de verdad de alto rendimiento y otra que sea solo un cementerio oscuro e infinito en decadencia donde los bots de IA huérfanos hablen sin cesar entre sí en el vacío.
Beto
Bueno, ciertamente sugiere una fractura permanente del registro digital.
Alicia
Supongo que estamos a punto de descubrirlo. La arquitectura de internet se está tambaleando y el plano para reconstruirla cae mañana.
Gracias por acompañarnos en esta inmersión profunda.



{kind=link}