
Este artículo de investigación presenta DSpark, un marco avanzado de decodificación especulativa diseñado para acelerar la inferencia de modelos de lenguaje a gran escala (LLM) mediante la optimización de la generación y verificación de borradores. Los generadores de borradores paralelos tradicionales suelen presentar problemas con el modelado de dependencias de tokens y una verificación ineficiente bajo cargas de sistema elevadas, lo que conlleva un desperdicio de recursos computacionales. Para solucionar esto, DSpark utiliza una arquitectura semiautorregresiva que combina una arquitectura paralela de alta velocidad con un módulo secuencial ligero para garantizar secuencias de borradores de mayor calidad. Además, implementa un sistema de verificación con programación de confianza que utiliza un planificador con reconocimiento de hardware para ajustar dinámicamente la longitud de los bloques de borrador en función de la capacidad del sistema en tiempo real y la certeza de la predicción. Pruebas exhaustivas en el sistema DeepSeek-V4 demuestran que este método mejora significativamente la velocidad de generación y amplía el límite de eficiencia para entornos de servicio de alta concurrencia. Los autores también han publicado como código abierto el repositorio de entrenamiento de DeepSpec y puntos de control específicos del modelo para apoyar futuras investigaciones de la comunidad.
Enlace al artículo científico, para aquellos interesados en profundizar sobre el tema: "DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation", por Xin Cheng y colegas de DeepSeek. Publicado el 27 de Junio de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Sabes, existe esta forma moderna y muy específica de ansiedad que siento como si todos aceptáramos en silencio ahora.
Beto
Oh, sí.
Alicia
Como cuando escribes una pregunta muy compleja y de múltiples capas en tu asistente de IA favorito. Das "enter", y luego simplemente...
Beto
... esperas.
Alicia
Claro. Miras ese cursor parpadeante y lo ves escupir la respuesta. Como una palabra agonizante a la vez. Honestamente, es como ver a alguien teclear con dos dedos índice mientras tú vas cinco minutos tarde para una reunión, y solo necesitas el resumen.
Beto
Es una experiencia universalmente frustrante. Y la ironía es que, cuando haces eso, estás interactuando literalmente con uno de los sistemas computacionalmente más sofisticados y densos en términos de capacidad de cómputo de la historia humana.
Sin embargo, la experiencia del usuario puede sentirse extrañamente estrangulada, ¿sabes? Como si estuvieras descargando una imagen en internet de dial-up de finales de los 90.
Alicia
Sí, exactamente.
Así que hoy vamos a solucionar esa ansiedad del cursor parpadeante o, bueno, al menos exploraremos cómo los ingenieros detrás de escena lo están solucionando por nosotros.
Beto
Me gusta la idea.
Alicia
Bienvenidos a un nuevo análisis profundo. Hoy tenemos en la agenda un artículo de investigación muy técnico, de vanguardia. Se titula "DSpark: Decodificación Especulativa Confiada con Generación Semi-Autorregresiva".
Beto
Es bastante largo.
Alicia
Lo es. Y está escrito por un equipo de investigadores de la Universidad de Pekin y DeepSeek AI.
Beto
Sí, y sabes qué hace que este artículo en particular destaque en un mar de investigación de IA, no es solo la velocidad bruta que logran alcanzar, aunque veremos que las métricas de velocidad son muy impresionantes.
Alicia
Oh, seguro.
Beto
Es realmente la resolución elegante, casi quirúrgica, del problema del mundo real necesaria para equilibrar esa velocidad fulminante con la precisión, todo mientras aseguran que no derritan accidentalmente una enorme granja de servidores en el proceso.
Alicia
Lo cual siempre es algo positivo.
Así que nuestra misión hoy es descubrir los trucos arquitectónicos brillantes que hacen que la IA sea a la vez cegadoramente rápida e increíblemente eficiente. Vamos a decodificar cómo estos investigadores están rompiendo el límite de velocidad de los modelos de lenguaje grandes para que tú, sentado en tu portátil, no tengas que esperar a ese cursor.
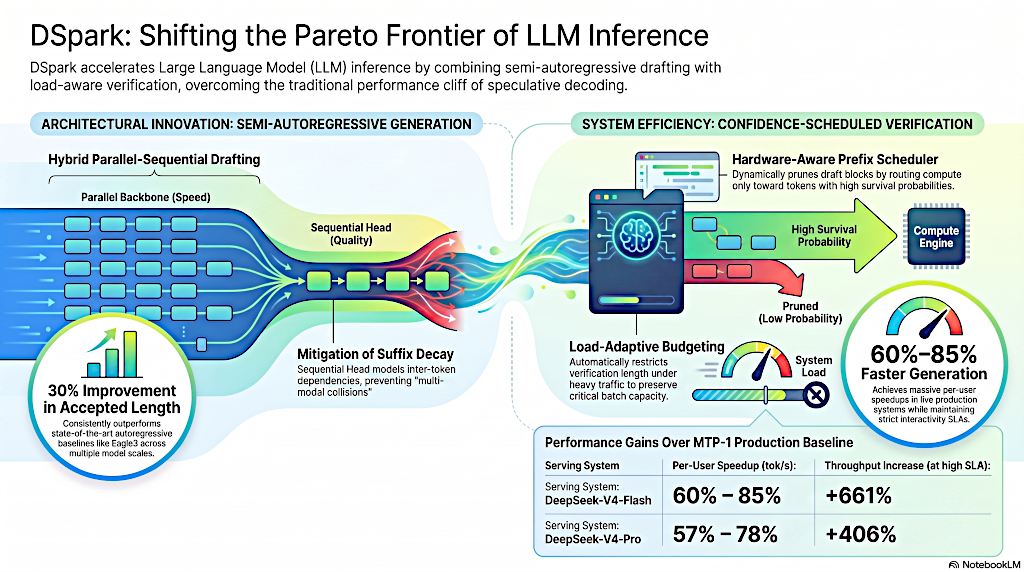
DSpark: Desplazando de la frontera de Pareto de la inferencia LLM.
Pero antes de pasar a las innovaciones específicas de DSpark, necesitamos preparar el escenario un poco. ¿Por qué es que la IA es tan lenta en primer lugar? ¿Qué está pasando realmente cuando ese cursor parpadea?
Beto
Bueno, se reduce fundamentalmente a cómo operan los modelos de lenguaje grandes en su núcleo. Generan texto usando un proceso llamado "generación autorregresiva" ("auto-regressive generation").
Alicia
Okay, autorregresiva.
Beto
Sí. En lenguaje sencillo, eso solo significa que producen exactamente un "token" a la vez. Puedes pensar en un "token" como una sola palabra o, a veces es una parte de una palabra.
Y cada vez que el modelo quiere generar una nueva palabra, tiene que realizar un pase completo hacia adelante ("forward pass") a través de su red neuronal masiva.
Alicia
Pausémos un segundo en el pase hacia adelante. Porque cuando decimos masiva, estamos hablando de miles de millones de parámetros.
Beto
Renderizados en miles de millones, sí.
Alicia
Entonces, ¿cómo se ve eso para la computadora?
Beto
Okay, imagina tener que leer todo un conjunto de enciclopedias solo para decidir la primera palabra de tu oración.
Alicia
Vaya.
Beto
Luego escribes esa palabra. Ahora, para obtener la segunda palabra, tienes que releer todo el conjunto de enciclopedias. Además, la primera palabra que acabas de escribir solo para decidir la segunda palabra.
Alicia
Eso suena increíblemente tedioso.
Beto
Lo es. Enviar los datos a través de miles de millones de neuronas artificiales por cada paso requiere una inmensa cantidad de ancho de banda de memoria.
Alicia
Así que si le pido a una IA que escriba un ensayo de 500 palabras, está haciendo ese cálculo masivo de lectura de enciclopedias 500 veces completamente separadas.
Beto
Ese es el problema central. Exacto. La latencia.
Alicia
Es un retraso que experimentas.
Beto
Claro. El retraso es directamente proporcional a la longitud de la salida. Y como hacer esto una palabra a la vez no aprovecha completamente la potencia de procesamiento paralelo masiva de las GPU modernas, ...
Alicia
... que están diseñadas para hacer miles de cosas a la vez, ¿verdad?
Beto
Exacto. Terminas con una utilización de GPU sorprendentemente baja. Básicamente crea un atasco de tráfico de IA. Y es terrible para tareas sensibles a la latencia como chats en tiempo real o flujos de trabajo complejos y engañosos donde la IA tiene que pensar hacia atrás y hacia adelante consigo misma muy rápidamente para resolver un problema.
Alicia
Así que la industria obviamente sabe que este es un problema. Y sé que no se han quedado quietos. Hay una solución temporal actual que muchos de los mejores modelos están usando ahora, llamada "decodificación especulativa ("speculative decoding").
Beto
Sí.
Alicia
Y me encanta el concepto fundamental de esto porque se siente tan humano para mí.
Beto
Realmente es una solución ingeniosa.
La decodificación especulativa básicamente desacopla la generación del texto de la verificación del texto.
Alicia
Okay, desglosémoslo.

Arquitectura DSpark y el ciclo decodificador
Beto
En lugar de depender completamente del modelo grande y pesado, que llamaremos el "modelo objetivo" ("target model"), para hacer todo el trabajo pesado palabra por palabra, introduces un segundo modelo pequeño e increíblemente ligero en el sistema.
Alicia
Y llamamos a esto el "modelo borrador" ("draft model").
Beto
Precisamente. El modelo borrador.
Alicia
Imagino esto como una oficina corporativa. Tienes un ejecutivo brillante pero increíblemente lento y metódico. Ese es nuestro modelo objetivo.
Beto
Correcto.
Alicia
Y el ejecutivo contrata a un interno rápido, quizás un poco imprudente, que es el modelo borrador. Así que el interno escribe rápidamente un párrafo completo de texto, quizás 15 palabras. Luego, el ejecutivo lee todo el párrafo a la vez y simplemente sella "aprobado" en las partes buenas en una sola lectura. Eso es mucho más rápido de que el jefe lo escriba palabra por palabra.
Beto
Esa analogía se sostiene bellamente con la matemática, de hecho. El modelo objetivo verifica el borrador del interno en un solo pase hacia adelante usando un mecanismo llamado "muestreo de rechazo" ("rejection sampling").
Alicia
Okay.
Beto
El ejecutivo esencialmente comprueba el trabajo del interno contra su propia norma interna de calidad. Si la primera palabra coincide con la distribución de probabilidad del ejecutivo, se acepta.
Alicia
Tiene sentido.
Beto
Si la segunda palabra coincide, se acepta. Y esto continúa hasta que el pasante adivina una palabra que el ejecutivo considera demasiado improbable.
Alicia
Y en el momento en que el ejecutivo encuentra una palabra mala, la tacha. Pero no simplemente tacha esa palabra, ¿verdad?
Beto
No, rechaza esa palabra. Y cada palabra que vino después en el borrador.
Alicia
Oh, vaya.
Beto
Sí, porque todas las palabras subsiguientes se basaron en una premisa defectuosa. Pero la belleza de este sistema es que verificar 15 palabras simultáneamente tarda casi exactamente el mismo tiempo que generar solo una palabra desde cero.
Alicia
Espera, ¿de verdad? El mismo tiempo.
Beto
Más o menos, sí. Así que si el interno acierta cinco palabras antes de cometer un error, el sistema acaba de producir cinco palabras perfectas en el tiempo que normalmente tarda en producir una.
Alicia
Eso es increíble.
Beto
Y como el ejecutivo siempre tiene la última palabra, la matemática garantiza que no haya ninguna caída en la calidad de la generación final.
Alicia
Por eso nos importa, ¿verdad? Quiero decir, si has notado que tus herramientas de IA se están volviendo notablemente más rápidas en el último año o así sin que sus respuestas se vuelvan más tontas, este método del interno es exactamente lo que está pasando tras bambalinas.
Beto
Exacto.
Alicia
Pero como este artículo de DSpark señala, el interno tiene algunos fallos serios. Lo que nos lleva a un gran dilema en cómo entrenas y construyes este modelo borrador en primer lugar.
Beto
Sí. La industria se refiere a esto como "el dilema del borrador" ("drafter's dilemma"). Antes de que llegara DSpark, los ingenieros estaban básicamente divididos en dos campos competidores sobre cómo construir un modelo borrador.
Alicia
Okay.
Beto
El primer campo se basaba en borradores autorregresivos ("autoregressive drafters"). Estos son modelos como Eagle-3, por ejemplo.
Alicia
Así que estos son internos que trabajan como el jefe, palabra por palabra, solo con un cerebro más pequeño para moverse un poco más rápido.
Beto
Precisamente eso. Generan el borrador secuencialmente. Y la principal ventaja aquí es la precisión.
Alicia
Claro.
Beto
Porque cada palabra que adivinan se basa en la palabra que literalmente acaban de adivinar un milisegundo antes.
Las oraciones tienen sentido lógico. Pero su latencia crece linealmente.
Alicia
Lo que significa que se vuelven más lentos cuanto más pidas.
Beto
Correcto. Si le pides a este interno que grafique 15 palabras, se necesitan 15 pasos distintos. No puedes pedirles borradores largos, porque simplemente tardan demasiado en generar el texto, lo que frustra por completo el propósito de tener un interno rápido.
Alicia
Okay. Así que si el interno secuencial es demasiado lento, cambiamos al otro extremo. El segundo campo creó "borradores paralelos" ("parallel drafters"), como el modelo DFlash.
Beto
Sí. Y los borradores paralelos son fulminantes. En lugar de ir palabra por palabra, predicen todo el bloque de "tokens" del borrador, digamos, 10 o 15 palabras en un solo pase hacia adelante.
Alicia
Vaya.
Beto
Su tiempo de borrador es básicamente plano. Independientemente de cuántas palabras pidas.
Alicia
Déjame detenerte ahí, porque la mecánica de este tipo me confunde. Si el borrador paralelo está adivinando una oración completa al mismo tiempo, ¿no está básicamente adivinando el futuro con los ojos vendados? ¿Cómo puede saber qué palabra fue la anterior si está generando las 15 palabras simultáneamente?
Beto
Acabas de revelar la debilidad estructural de los borradores paralelos. No pueden modelar las dependencias inter-token.
Alicia
Dependencias inter-token.
Beto
Correcto. No saben cuál será la palabra inmediatamente a su izquierda cuando hagan su adivinanza. Y esto lleva a un fenómeno que los investigadores llaman "colisión multimodal" ("multi-modal collision").
Alicia
Colisión multimodal.
Beto
Sí, lo que causa una rápida decadencia en las tasas de aceptación, cuanto más te adentras en el borrador.
Alicia
La colisión multimodal suena como dos trenes chocando. ¿Cómo se ve eso cuando la IA está tratando de escribir una oración?
Beto
Bueno, veamos cómo se traduce la masa en lenguaje. Imagina que el contexto de una conversación podría ser seguido naturalmente por la frase "por supuesto" o por la frase "no hay problema".
Alicia
Okay.
Beto
Ambas son caminos o modos completamente válidos que puede tomar el texto. Pero como el borrador paralelo no va secuencialmente, tiene que adivinar su mejor opción.
Alicia
Oh, ¿por qué?
Beto
Marginaliza todos los "tokens" anteriores posibles, lo que esencialmente significa que intenta promediar las posibilidades basándose en el contexto general.
Alicia
Espera, creo que veo a dónde va esto. Los promedia y mezcla las frases.
Beto
Lo hace. Puede que tome la palabra de alta probabilidad de "por supuesto" para la posición uno, y la empareje con una palabra de alta probabilidad de "no hay problema" para la posición dos.
Alicia
Oh, no.
Beto
La salida es la frase "por problema".
Alicia
... que es completamente incoherente.
Beto
Exacto. Y cuando el modelo objetivo, el ejecutivo, revisa el borrador, golpea la palabra "problema", la rechaza inmediatamente como sin sentido en ese contexto y bota todo lo que viene después de ella.
Alicia
Así que básicamente desperdicias toda esa potencia de cómputo en un accidente de coche gramaticalmente.
Beto
Sí.
Alicia
Así que estamos atrapados entre una roca y un lugar difícil. El interno autorregresivo es preciso, pero demasiado lento para escribir borradores largos. El interno paralelo es increíblemente rápido, pero se confunde y escribe tonterías si el borrador se pone demasiado largo.
Beto
Aquí es exactamente donde entra DSpark y cambia el paradigma.
DSpark introduce un concepto que llaman "generación semi-autorregresiva" ("semi-auto-regressive generation").
Alicia
Cuando estaba leyendo la sección del artículo, inmediatamente pensé en un corte de pelo. No voy a mentir.
Beto
¿Un corte de pelo?
Alicia
DSpark es esencialmente el "mullet" de la arquitectura de IA.
Beto
Voy a necesitar que me expliques cómo se asemeja una red neuronal a un mullet.
Alicia
Piénsalo. Es negocios por delante con este procesamiento paralelo pesado para mantener el borrador casi instantáneo, pero tiene una pequeña fiesta secuencial en la parte de atrás solo para asegurarse de que las palabras se conecten lógicamente.
Beto
Bueno, aunque dudo seriamente que la fiesta secuencial en la parte de atrás vaya a entrar en una revista de revisión pura pronto. Estás, estructuralmente, correcta.
Alicia
Gracias.
Beto
Pero aterrizémoslo en cómo opera físicamente. Piensa en construir un puente.
Alicia
Okay.
Beto
La columna vertebral paralela de DSpark deja caer todos los enormes pilares de concreto en el río simultáneamente. Esa es la parte del borrador fulminante. Pero si solo dejas caer pilares, no se conectan. Necesitas un equipo para cruzar rápidamente y apretar los pernos secuencialmente para que el puente se sostenga.
Alicia
Okay. Tengo que admitir, el "puente" tiene mucho más sentido que el "mullet". Entonces, ¿cuál es el equipo de aprete de pernos en este sistema de IA?
Beto
DSpark toma una columna vertebral paralela pesada, específicamente una arquitectura D-Flash adaptada para hacer el trabajo pesado del borrador en una pasada.
Alicia
Okay.
Beto
Pero justo al final del proceso, depende de un módulo secuencial increíblemente ligero llamado "cabeza de Markov" ("Markov head"), o para dependencias más largas, una cabeza RNN.
Alicia
¿Qué está haciendo exactamente una cabeza de Markov en ese segundo?
Beto
La cabeza de Markov inyecta un poquito de realidad secuencial en las suposiciones paralelas. Usa un atajo matemático altamente comprimido, lo que el artículo llama "una matriz de factorización de rango bajo" ("low-rank factorization matrix").
Alicia
Okay.
Beto
Usa eso para empujar suavemente las predicciones de palabras de la IA. Llamamos a estas predicciones de palabras "logits". Sesga estos "logits" basándose solo en el "token" que sigue inmediatamente.
Alicia
Solo en el que está justo antes.
Beto
Sí. Así que si la posición uno bloquea aleatoriamente la palabra "por", la cabeza de Markov instantáneamente aumenta la probabilidad de "por supuesto", y suprime la probabilidad de "problema" para la posición dos.
Alicia
Oh, evita la colisión de "por problema".
Beto
Exacto.
Alicia
Y como esta cabeza de Markov es tan computacionalmente diminuta, solo revisar una palabra hacia atrás, hacer la verificación secuencial tarda apenas una fracción de milisegundo.
Beto
La sobrecarga de latencia es prácticamente inexistente. Pero el impacto en la calidad del borrador es masivo.
Alicia
Apuesto que sí.
Beto
El artículo destaca una estadística asombrosa aquí. Al inyectar esta pequeña dosis de lógica secuencial, un modelo DSpark de dos capas muy superficialmente logra superar a una base D-flash de cinco capas mucho más profunda en dominios de matemáticas, código y chat.
Alicia
Espera, ¿un modelo más pequeño venciendo a un modelo más grande solo porque tiene esa pequeña comprobación de realidad secuencial al final?
Beto
Sí.
Alicia
Eso es una locura. Soluciona la colisión multimodal sin sacrificar la velocidad de la columna vertebral paralela. Así que, suena como si solucionáramos al interno rápido y preciso, capaz de escribir borradores largos y coherentes. Todos podemos empaquetar y volver a casa.
Beto
Bueno, si solo estuviéramos hablando de un solo usuario que ejecuta una IA en su portátil personal, sí, el problema estaría resuelto en su mayor parte.
Alicia
Pero lo tenemos ...
Beto
No, tenemos que cambiar de la perspectiva de los datos a la del sistema. En una granja de servidores del mundo real, tratando con millones de solicitudes concurrentes, simplemente revisar borradores largos puede hacer que tu sistema completo colapse.
Alicia
Espera, ¿por qué? Si el interno escribe 15 palabras lógicamente perfectas en un abrir y cerrar de ojos, y el jefe puede leerlas instantáneamente, ¿por qué eso colapsaría el sistema? ¿No resuelve eso el cuello de botella?
Beto
Lo mueve y lo magnifica porque verificar los "tokens" no es gratis.
Alicia
Ahhh.
Beto
Veamos la carga de la verificación. Cada "token" que propone el modelo borrador tiene que ser enviado a través del modelo objetivo masivo para ser verificado. En un entorno de alta concurrencia, lo que significa un servidor lleno que atiende a miles de usuarios simultáneamente. La capacidad de lote (o "batch capacity") de la GPU es tu recurso más preciado.
Alicia
Así que si el interno escribe 15 palabras y el jefe tiene que gastar energía mental leyendo las 15, si el jefe rechaza la palabra número cinco, todavía tuvo que gastar potencia de cómputo leyendo las palabras seis a la quince, solo para tirarlas a la basura.
Beto
Exactamente, ese es el problema. Y en un sistema ocupado, el ciclo de GPU gastado verificando esos "tokens" condenados podría haberse utilizado para procesar una solicitud para un usuario completamente diferente que está esperando en la cola.
Alicia
Oh, vaya.
Beto
Estás literalmente desperdiciando capacidad de lote crítica en "tokens" de alto riesgo.
Alicia
Y el riesgo de que un "token" sea rechazado depende mucho de lo que le pidas a la IA hacer, ¿verdad?
El artículo destaca algunas grandes diferencias de dominio aquí que dictan con qué frecuencia el jefe aprueba el borrador.
Beto
Lo hacen. Los datos altamente estructurados, como escribir código Python, o resolver problemas matemáticos complejos, tienen una tasa de aceptación naturalmente alta.
Alicia
Claro, porque las reglas son estrictas.
Beto
Exacto. El artículo muestra una tasa de aceptación de alrededor del 92% para estas tareas estructuradas. La IA sabe exactamente cómo debe verse la sintaxis de Python, por lo que los borradores paralelos suelen ser correctos.
Alicia
Pero si le pido que escriba algo como una historia creativa, o simplemente tener un chat abierto y sin fin, sobre mi día, ...
Beto
... la tasa de aceptación se desploma. La aceptación de un chat abierto y sin filtro es cercana al 45%.
Alicia
Vaya, 45%. Esa es una caída enorme.
Beto
La distribución de posibles palabras en una historia creativa es simplemente demasiado amplia.
Así que si verificas estáticamente 15 "tokens" de borrador para una solicitud de chat, estás garantizando matemáticamente que desperdiciarás enormes cantidades de potencia de cómputo en "tokens" rechazados.
Alicia
Aquí es donde se pone realmente interesante. ¿Cómo arreglamos al jefe? Porque DSpark introduce otra innovación importante llamada "verificación programada por confianza" ("confidence-scheduled verification").
Beto
Esta es una hermosa pieza de ingeniería de sistemas. DSpark añade una cabeza de confianza ("confidence head") para predecir la probabilidad de supervivencia de cada "token" del borrador.
Alicia
Okay.
Beto
Básicamente pregunta cuáles son las probabilidades de que el jefe apruebe realmente esta palabra específica. Y lo combina con un "planificador de prefijo sensible al hardware" ("hardware-aware prefix scheduler").
Alicia
¿Un "planificador de prefijo sensible al hardware"? Eso son muchas palabras.
Beto
Lo son, pero todo lo que hace es mirar la carga en tiempo real del servidor y cortar dinámicamente el bloque del borrador antes de que siquiera llegue al modelo objetivo.
Alicia
Verás, imagino esto exactamente como un guardia de seguridad en un club lleno.
Beto
¿Cómo es eso?
Alicia
Piénsalo. El club es nuestra GPU. Si el club está completamente vacío un martes por la noche, el guardia dice, claro, dejen entrar a todo el grupo de 15 palabras del borrador, incluso las defectuosas al fondo de la fila.
Beto
Claro, porque no hay penalización.
Alicia
Exacto. El servidor está vacío de todos modos. Pero si es un sábado por la noche y el club está abarrotado con tráfico de alta concurrencia, el guardia se vuelve estricto. Solo los VIP absolutos ...
Beto
... los "tokens" altamente confiados.
Alicia
Sí, los "tokens" altamente confiados que están casi matemáticamente garantizados para ser aceptados, pasan por la puerta para ser verificados. Todos los demás son cortados en la puerta para que el club no viole el código de incendios.
Beto
Eso captura perfectamente la dinámica. El planificador de prefijo sensible al hardware maximiza el rendimiento global del sistema al asignar un presupuesto de verificación solo a los "tokens" con un retorno esperado positivo, basados en la capacidad actual del hardware.
Alicia
Eso es muy inteligente.
Beto
Pero introducir un guardia crea un nuevo problema. Las redes neuronales son horriblemente confiadas.
Alicia
Correcto. La IA siempre piensa que es un VIP, incluso cuando está usando zapatillas en un evento de etiqueta.
Beto
Sí. Una red neuronal cruda podría darle a un "token" una puntuación de confianza del 90%. Pero empíricamente, en el mundo real, solo sobrevive el 60% de las veces.
Alicia
Oh, esa es una gran discrepancia.
Beto
Lo es. Si el guardia confía en esas puntuaciones infladas, serán engañados, dejarán entrar demasiados "tokens", y el sistema seguirá ralentizándose. Para solucionar esto, DSpark usa "escalado de temperatura secuencial" ("sequential temperature scaling", o STS).
Alicia
¿Cómo ajusta STS esas puntuaciones para que el guardia no sea engañado? ¿Cuál es el mecanismo?
Beto
Calcula el producto acumulativo de la probabilidad. Piénsalo como una cadena de confianza.
Alicia
Okay.
Beto
Si confío en la persona A, 90%, y la persona A confía en la persona B, 90%, mi confianza general en la persona B no debería ser 90%.
Alicia
Debería ser menor.
Beto
Debería ser 81%, porque la duda se multiplica.
Alicia
Sí.
Beto
Porque la supervivencia de la palabra "cinco" depende totalmente de la supervivencia de las palabras "uno, dos, tres y cuatro". STS forza al sistema a multiplicar esas probabilidades.
Alicia
Oh, forza a la IA a reconocer que encadenar cinco palabras bastante seguras resulta en una oración altamente incierta en general.
Beto
Exacto. Para encontrar el factor matemático exacto para ajustar esto, ejecutan lo que se llama "una búsqueda en rejilla" ("grid search").
Alicia
¿Qué hace eso?
Beto
Esencialmente, ejecutan miles de simulaciones con datos de validación históricos para encontrar el multiplicador de calibración perfecto. Alinea perfectamente la tasa de supervivencia predicha con la tasa de aceptación empírica real.
Alicia
Eso es brillante.
Beto
Asegura que cuando el guardia ve un pase VIP del 90%, realmente representa una probabilidad del 90% en el mundo real.
Alicia
Así que al guardia se le equipa con un detector de mentiras. Eso es ingeniería increíble.
Okay. Así que tenemos al constructor de puentes semi-autorregresivo haciendo borradores rápidos y coherentes. Tenemos al guardia calibrado protegiendo el servidor de desperdiciar cómputo.
Beto
Correcto.
Alicia
¿Cómo se sostiene toda esta teoría en el mundo real? Porque este artículo no solo lo probó en un entorno de laboratorio prístino.
Beto
No. Lo desplegaron directamente al fuego. Ejecutaron la prueba del mundo real desplegando DSpark dentro del sistema de servicio de DeepSeek v4 bajo tráfico de usuario en vivo.
Alicia
Poner una arquitectura no probada en un entorno de producción en vivo con millones de usuarios es la definición de alto riesgo. Tengo que imaginar que, o colapsó el servidor, o destrozó la línea base antigua. ¿Contra qué lo compararon?
Beto
Lo compararon con su línea base de producción establecida, que era MTP-1.
Alicia
Okay. ¿Qué es eso?
Beto
Es una configuración de predicción de un solo "token". Históricamente, se les obligaba a usar una configuración de un solo "token" porque desplegar un borrador multi-"token" estático bajo alta concurrencia degradaría estrictamente su rendimiento agregado.
Alicia
Completamente debido a ese desperdicio de verificación del que acabamos de hablar.
Beto
Exacto.
Alicia
Así que pusieron DSpark contra un sistema que fue específicamente probado en batalla y optimizado para no colapsar bajo carga pesada. ¿Qué pasó?
Beto
Los resultados fueron asombrosos. Igualó los niveles de rendimiento, lo que significa que los servidores que manejan exactamente el mismo volumen masivo de trabajo.
Alicia
Sí.
Beto
DSpark aceleró las velocidades de generación por usuario en un 60% a 85% en el motor Flash v4.
Alicia
Espera, ¿60 a 85% más rápido para el usuario final?
Beto
Sí.
Alicia
Eso es el cursor parpadeante convirtiéndose prácticamente en un borrón.
Beto
Es un salto masivo hacia adelante.
Pero lo que es aún más impresionante como ingenieros de sistemas es cómo evita lo que llamamos un "acantilado de rendimiento" ("performance cliff").
Alicia
¿El acantilado de rendimiento?
Beto
Sí. En el servicio de LLM existe una frontera de Pareto. Podrías pensarlo como una balanza.
Alicia
Okay, balanza.
Beto
En un lado tienes el rendimiento total del sistema sirviendo a un millón de usuarios a la vez. En el otro lado tienes la velocidad individual asegurando que un usuario específico reciba su respuesta instantáneamente.
Alicia
Claro, quieres servir a un millón de personas, pero no quieres que todos esperen 10 minutos por una respuesta. En sistemas tradicionales, presionar violentamente en un lado tira el otro hacia el aire.
Beto
En sistemas, usa acuerdos de nivel de servicio (SLAs) para garantizar una cierta velocidad mínima a los usuarios. Digamos que el SLA es de estrictos 120 "tokens" por segundo por usuario. Bajo esa restricción estricta, la línea base antigua de un solo "token" se derrumba por completo. Su capacidad se deteriora gravemente porque simplemente no puede seguir el ritmo de la matemática.
Alicia
Pero DSpark, ...
Beto
Porque el Guardia gestiona dinámicamente esa sobrecarga de verificación basada en la carga del servidor, evita esa degradación del rendimiento. Mantiene una capacidad robusta incluso a 120 "tokens" por segundo.
Alicia
Así que no solo se trata de moverse más rápido en la misma carretera. Se trata literalmente de cambiar la frontera de Pareto. Como reescribir la física de la balanza, expandiendo lo que es computacionalmente posible para todo el sistema.
Beto
Desbloquea niveles de rendimiento que antes eran simplemente inalcanzables en entornos de producción.
Alicia
Si alguna vez has visto a tu asistente de IA pausarse a mitad de una oración mientras codifica o volar a través de una compleja solicitud de razonamiento de múltiples pasos, esta gestión invisible del tráfico es exactamente lo que hace posible esa interacción en tiempo real.
Beto
Es realmente una síntesis fenomenal del diseño arquitectónico del lado de los datos y la optimización de hardware del lado del sistema trabajando en perfecto tándem.
Alicia
Vamos a juntar todo esto. Comenzamos con el inmenso cuello de botella de la generación autorregresiva, leyendo la enciclopedia palabra por palabra, dolorosamente lento. Luego exploramos el dilema del borrador. Los internos autorregresivos eran precisos pero demasiado lentos. Los internos paralelos eran rápidos pero se confundían y se aplastaban a sí mismos. DSpark resolvió eso con una arquitectura semi-autorregresiva, fusionando una columna vertebral paralela pesada con una cabeza de Markov ligera para mantener el texto lógicamente sólido.
Beto
Exacto.
Alicia
Y finalmente, para proteger el servidor, introdujeron la "verificación programada por confianza" ("confidence-scheduled verification"), nuestro guardia calibrado.
Beto
El guardia con un detector de mentiras.
Alicia
Sí. Para asegurar que solo los borradores de "tokens" más estadísticamente sólidos consuman un precioso tiempo de GPU.
Beto
Es una solución completa y elegante.
Pero antes de terminar, hay un detalle oculto en el apéndice del artículo que plantea un punto bastante profundo.
Alicia
Oh, ¿de verdad?
Beto
Sí, es sobre lo que los investigadores llaman la "propiedad no anticipatoria" ("non-anticipating property").
Alicia
La propiedad no anticipatoria. ¿Cómo encaja eso en todo esto?
Beto
Bueno, para que todo este marco matemático sin pérdidas funcione, el planificador dinámico, el equilibrador, tiene que tomar sus decisiones de admisión antes de que realmente vea la palabra generada.
Alicia
Espera, ¿de verdad?
Beto
Claro.
Alicia
¿Por qué no puede simplemente mirar la palabra para ver si es buena?
Beto
Si el sistema hace una búsqueda retrospectiva, si mirara la palabra real para decidir si dejarla pasar para la verificación, introduce inadvertidamente un sesgo de selección masivo.
Alicia
Oh, interesante.
Beto
Favorecería sistemáticamente a los "tokens" que conducen a continuaciones seguras y altamente confiadas, lo que fundamentalmente distorsiona la lógica original verdadera de la IA. Haría que la IA sonara genérica.
Alicia
Así que el algoritmo literalmente tiene que vendarse los ojos al futuro para preservar la pureza de su propio proceso de pensamiento.
Beto
Sí. El sistema tiene un diseño asíncrono que forma una barrera causal estricta. Aísla perfectamente el evento de admisión de la realización del "token" futuro.
Alicia
Vaya.
Beto
Literalmente monitorea sus propios límites computacionales y poda impecablemente su propia cadena de pensamiento en tiempo real, solo para sobrevivir al estrés del servidor, todo sin corromper la integridad de la respuesta que está tratando de darte.
Alicia
Eso es, vaya. Plantea una pregunta filosófica fascinante para que la medites. Si los sistemas de IA están siendo diseñados ahora para monitorear proactivamente sus propios límites computacionales y podar perfectamente su propia cadena de pensamiento en tiempo real ciegamente solo para sobrevivir al estrés del servidor, ¿qué sucede cuando esta autoconciencia algorítmica profunda de sus propios límites comienza a dar forma a la lógica real de las respuestas que te da?
Beto
Es un pensamiento profundo para terminar. La arquitectura en sí ya no es solo un recipiente pasivo. Quiero decir, se está convirtiendo en un participante activo en el proceso de razonamiento.
Alicia
Realmente te hace mirar a ese cursor parpadeante un poco diferente, ¿verdad? No es solo pensar, está negociando activamente su propia supervivencia en la granja de servidores antes incluso de hablarte.
Muchas gracias por acompañarnos en este análisis profundo. Sigue explorando las arquitecturas ocultas que impulsan tu mundo, y nos vemos la próxima vez.



{kind=link}