
Hoy les traigo un resumen de un artículo científico que ofrece un estudio exhaustivo de los Modelos Fundacionales (MF) y sus amplias aplicaciones en el ámbito sanitario. Traza la historia de la Inteligencia Artificial (IA) en medicina, destacando avances arquitectónicos clave como las Redes Neuronales Convolucionales (CNN), las Redes Neuronales Recurrentes (RNN) y, en especial, los Transformadores, cruciales para los MF modernos. La fuente clasifica los MF en áreas como los Modelos Clínicos de Lenguaje Grande (LCLM), el Análisis de Imágenes Médicas (incluyendo segmentación y clasificación) y la Genómica (genómica y proteómica), detallando modelos especializados como GatorTronGPT y MedSAM. Además, el análisis explora las importantes oportunidades que ofrecen los MF, como la mejora de la robustez y el abordaje de datos de pequeño tamaño en enfermedades raras, a la vez que aborda desafíos cruciales como el alto coste computacional, la interpretabilidad y las preocupaciones legales y éticas para su adopción clínica generalizada.
Enlace al artículo, para aquellos interesados en profundizar en el tema: "A Comprehensive Survey of Foundation Models in Medicine", Wasif Khan y colegas. Publicado en Enero 16 del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Bienvenidos a este análisis profundo en la que tomamos el vasto y a menudo abrumador mundo de los datos complejos y tratamos de reducirlo a las ideas esenciales y fascinantes que necesitas conocer.
Hoy emprendemos una inmensa inmersión. Es una que se sitúa exactamente en la intersección entre la tecnología revolucionaria y la salud humana. Estamos analizando los modelos fundacionales — o FMs — y su revisión comprehensiva en medicina y atención sanitaria, basada en una encuesta extensa y realmente crítica del campo.
Bien, empecemos por desentrañar este tema central. ¿De qué hablamos realmente cuando decimos modelos fundacionales?
Técnicamente, son modelos de aprendizaje profundo a gran escala. Se entrenan con conjuntos de datos enormes, normalmente usando lo que se llama aprendizaje auto-supervisado. Y el resultado es un único modelo base, altamente versátil, que luego puede adaptarse y ajustarse para una enorme gama de tareas específicas.
Alicia
Exacto. Para los oyentes que quizá no tengan un doctorado en aprendizaje automático, ¿cómo describirías la diferencia entre un modelo fundacional y una IA especializada estándar que hemos visto antes?
Beto
Piensa en una IA especializada como una llave de una sola casa. Abre una cerradura: por ejemplo, detectar tumores en un tipo muy específico de radiografía.
Un modelo fundacional, en cambio, es más como una llave maestra. Una vez entrenado, tiene una comprensión tan amplia de patrones y contexto que puede adaptarse rápidamente para abrir miles de cerraduras diferentes: desde diagnósticos hasta descubrimiento de fármacos o generar resúmenes de pacientes.
Alicia
Esa es una analogía perfecta, y esto es tan importante porque, aunque la inteligencia artificial y la salud no son nuevas — la cirugía asistida por ordenador comenzó ya a principios de los años 80 —, el ritmo de progreso ha explotado recientemente.
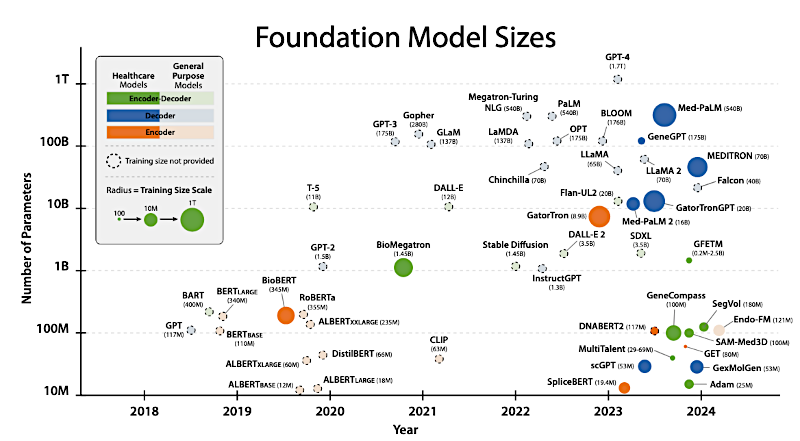
Tamaño de los Modelos Fundacionales
Y el catalizador clave de esta explosión fue la introducción de la arquitectura transformer en 2017. Los modelos construidos sobre esta arquitectura, como las familias BERT y GPT, están ahora transformando casi todos los aspectos de la atención sanitaria. Estamos yendo más allá del simple reconocimiento de patrones hacia una verdadera síntesis de alto nivel, ya sea en análisis de imágenes médicas o en el complejo y abstracto mundo de la investigación genómica.
Beto
Nuestra misión hoy para ti, el oyente, es bastante clara. Vamos a levantar el telón sobre los FMs específicos que se están adaptando para uso clínico. Examinaremos algunas de sus capacidades verdaderamente sorprendentes, como esos datos avanzados de resonancia magnética sintetizados que mencionamos. Y, de forma crucial, revisaremos los principales desafíos prácticos y estructurales a los que se enfrentan.
Alicia
Y solo para situar el escenario desde el momento "ajá" inicial, tienes que entender que la escala aquí es simplemente asombrosa y altamente especializada. Estos modelos médicos varían dramáticamente; están muy por encima de lo con lo que el público suele interactuar.
Por ejemplo, existen modelos como Megatron-LM que ahora escalan hasta 70.000 millones de parámetros y se entrenaron con literalmente miles de millones de palabras de texto clínico. Esto los hace profundamente, profundamente integrados en el vocabulario y el contexto específico de la medicina.
Beto
Esa escala es simplemente alucinante. Empecemos exactamente por dónde viene esa escala: la base técnica.
El verdadero punto de inflexión no fue solo más datos; fue una mejor arquitectura. Mencionaste la introducción en 2017 del modelo transformer. ¿Por qué fue eso un terremoto técnico?
Alicia
Pues porque cambió fundamentalmente cómo las máquinas procesan secuencias de información, ya sean esas secuencias palabras en una oración o bases en una cadena de ADN. Verás, antes dependíamos de modelos secuenciales como las redes neuronales recurrentes (RNNs). Tenían que leer una palabra y luego la siguiente y luego la siguiente. El modelo transformer, usando un mecanismo de autoatención, permite que el modelo capture el contexto en paralelo: mira toda la secuencia de una vez, entendiendo cómo el comienzo de una oración se relaciona con el final simultáneamente.
Beto
Así puede procesar el contexto mucho más rápido y a fondo.
Alicia
Exactamente. Este salto permitió la creación de los primeros grandes modelos fundacionales, como BERT, que se convirtieron en el estándar casi de la noche a la mañana. Y, por supuesto, la familia GPT.
Pero el habilitador fundamental para todos los FMs, lo que les permite manejar esta cantidad colosal de información, es el aprendizaje auto-supervisado ("Self-Supervised Learning", SSL). Aquí el modelo genera autónomamente sus tareas de preentrenamiento a partir de enormes cantidades de datos sin etiquetar. Aprende sin que un humano tenga que etiquetar manualmente cada pieza de información.
Beto
Eso explica cómo pueden digerir tanto texto sin procesar.
Pero aquí viene la pregunta clave, especialmente para las implicaciones clínicas. ¿Por qué no podemos simplemente usar un modelo general enorme, como por ejemplo un chat GPT genérico? ¿Por qué necesitamos modelos lingüísticos clínicos a gran escala especializados ("Clinical Large Language Models", CLLMs)?
Alicia
Todo se reduce al vocabulario y a las distribuciones contextuales. Los modelos generales se entrenan con datos generales de Internet: Reddit, Wikipedia, libros. Las distribuciones de palabras, la terminología específica, los acrónimos, la jerga, la forma en que se estructuran las notas son significativamente diferentes en el contexto clínico. Un modelo que traduce bien del francés al alemán podría tener dificultades para distinguir “neumonía” de “infiltrado” en la nota de un médico. Necesitas modelos empapados en corpus médicos.
Beto
Detallemos esos modelos especializados que surgieron de esta necesidad. ¿Cuáles fueron los primeros pioneros que realmente establecieron este entrenamiento específico por dominio?
Alicia
Uno de los primeros y más exitosos fue BioBERT, introducido en 2018. Se entrenó específicamente con literatura biomédica a gran escala. Su éxito fue casi inmediato en tareas críticas para el procesamiento del lenguaje natural clínico: reconocimiento de entidades nombradas, extracción de relaciones y respuesta a preguntas.
Beto
Un momento. Para nuestros oyentes, asegurémonos de desmenuzar esa sopa de siglas. ¿Cómo se ve el reconocimiento de entidades nombradas ("Named Entity Recognition", NER) en un entorno clínico?
Alicia
Buena pregunta. El NER enseña a la máquina a identificar y categorizar conceptos críticos en una nota médica. Identifica “aspirina”, “paciente Jaundo” e “infarto de miocardio” como tipos específicos de entidades: un medicamento, una persona, una enfermedad, todo en un bloque de texto no estructurado. Luego la extracción de relaciones ("Relation Extraction", RE) da un paso más: conecta esas entidades. Por ejemplo, reconocer que la aspirina fue recetada al paciente Jaundo por el infarto de miocardio. Y la respuesta a preguntas ("Question Answering", QA) usa esas relaciones identificadas para contestar instantáneamente una consulta del clínico basada en el expediente del paciente.
Beto
Ese nivel de especialización funcional es crítico. ¿Y hasta qué punto han evolucionado desde esa base de 2018?
Alicia
Han alcanzado una escala operacional real. Por ejemplo, toma GatorTronGPT de 2023. Se construyó sobre la arquitectura GPT-3, escalando hasta 20.000 millones de parámetros. Y, crucialmente, sus datos de entrenamiento incluyeron un volumen masivo de 82.000 millones de palabras de texto clínico desidentificado del UF Health. Eso, junto con datos generales, llevó el total a 277.000 millones de palabras. Porque se entrenó con documentación clínica del mundo real, mostró la capacidad notable de generar datos sintéticos alineados con el conocimiento médico. Incluso alcanzó un rendimiento comparable al humano en una prueba de Turing para médicos.
Beto
Ese es un hito fenomenal: desempeñarse de forma comparable a humanos en una prueba de Turing.
Pero si ese modelo se entrenó con 82.000 millones de palabras desidentificadas de una sola institución, UF Health, ¿no introduce eso inevitablemente un sesgo regional o demográfico? ¿No lo haría menos efectivo en una clínica rural en Alaska o en un gran hospital metropolitano en Nueva York, que atienden poblaciones de pacientes totalmente diferentes?
Alicia
Ese es precisamente el punto de fricción con el que lidiamos. El sesgo de datos institucionales es una preocupación enorme. Aunque estos modelos especializados muestran un rendimiento increíble a nivel local porque están perfectamente afinados al estilo de documentación y la cohorte de pacientes de ese hospital específico, su generalizabilidad sigue siendo una gran pregunta abierta. Los investigadores están trabajando activamente en técnicas de fusión de modelos y en el intercambio multi-institucional de datos para mitigar esto.
Beto
Y en cuanto al tamaño, ¿estamos viendo modelos aún más grandes ahora?
Alicia
Sí. El modelo MEDITRON, también de 2023, es aún mayor con 70.000 millones de parámetros. Se entrenó con 48.1 mil millones de tokens del dominio médico. Y encuestas han mostrado consistentemente que MEDITRON supera en ciertas tareas médicas específicas a anteriores modelos de vanguardia como GPT-3.5 y MedPaLM. Esto subraya que, por ahora, tamaño y datos especializados siguen siendo las palancas clave para el rendimiento.
Beto
La complejidad del lenguaje clínico es inmensa, pero el desafío se complica aún más cuando pasas de registros de texto a datos visuales: el mundo de la imagen médica. ¿Cómo pasan los modelos fundacionales de leer miles de millones de palabras a analizar escáneres de alta resolución?
Alicia
La visión por computadora médica es donde los patrones y características difieren más significativamente de las imágenes naturales que encuentras en Internet general. Los desafíos hacen que los modelos de segmentación generales — incluso los muy exitosos como SAM, "Segment Analysis Model", entrenado con más de 11 millones de imágenes generales — sean a menudo ineficaces para tareas especializadas.
Beto
Como, ¿por ejemplo?
Alicia
Especialmente en imágenes volumétricas 3D complejas como las resonancias magnéticas (RM) o las tomografías computarizadas (TC). La definición del límite entre tejido sano y tejido patológico es demasiado sutil para que un modelo general lo capte.
Beto
¿Cuál es la respuesta especializada en el dominio visual?
Alicia
Refleja la estrategia textual: entrenamiento intensivo específico por dominio. Así vimos modelos como MedSAM, introducido en 2024. Es un FM relacionado con la medicina diseñado para segmentación universal de imágenes. Se entrenó con más de 1.5 millones de pares imagen-texto médicos y muestra un rendimiento superior en ese entorno especializado comparado con su contraparte de propósito general.
Beto
También vemos modelos basados en conceptos como CLIP, que conectan imágenes y texto. ¿Enfrentan el mismo problema de escasez de datos que mencionaste antes?
Alicia
Sí. Los modelos basados en CLIP se topan con una traba porque el dominio médico tiene conjuntos de datos de imágenes-texto de alta calidad mucho más pequeños que los miles de millones de imágenes generales etiquetadas en Internet.
Beto
¿Cómo están afrontando los investigadores esa limitación de datos de forma eficiente e ingeniosa?
Alicia
Se están volviendo inteligentes con los datos que tienen. Por ejemplo, MedCLIP en 2022 adoptó un enfoque muy astuto: emplearon aprendizaje contrastivo, pero desacoplaron las imágenes y el texto y reemplazaron las funciones de pérdida estándar — es decir, las medidas de error — por una pérdida de emparejamiento semántico basada en conocimiento médico.
Beto
¿Puedes simplificar esa idea de pérdida de emparejamiento semántico?
Alicia
Claro. Piénsalo así: en lugar de castigar al modelo solo por estar numéricamente equivocado, enseñaron al modelo el significado de los términos médicos. Aseguraron que la representación visual del modelo se alineara con el significado estructurado del concepto. Crucialmente, MedCLIP logró un desempeño prometedor comparado con modelos generales, pero usando 10 veces menos datos de entrenamiento. Eso habla directamente del poder de la experiencia específica del dominio por encima de la mera recopilación masiva de datos.
Beto
Eso es un ejemplo fantástico de eficiencia.
Ahora, esto se vuelve realmente abstracto e interesante cuando pasamos al núcleo biológico: hablemos de ómicas — genómica, proteómica, transcriptómica — donde los FMs están extrayendo cavidades de datos celulares increíblemente complejos. Aquí es donde la IA realmente comienza a descifrar el lenguaje de la vida misma.
Alicia
Si lo conectamos con la visión global, en ómicas la arquitectura transformer se usa para encontrar estructura en datos mucho más complejos que el lenguaje humano. Por ejemplo, Geneformer: un modelo basado en transformer entrenado en un enorme conjunto de 29.9 millones de transcriptomas de células individuales, compilado en lo que se llama Genecorpus-30M.
Beto
¿Qué permite realmente a un investigador usar un modelo transformer para mirar transcriptomas?
Alicia
Le permite al modelo actuar como un mapeador con conciencia de contexto de redes génicas. No mira un gen en aislamiento: entiende cómo la expresión del gen A se relaciona con los genes B, C y D simultáneamente a través de distintos tipos celulares y condiciones. Esto es esencial para identificar mecanismos sutiles en enfermedades o predecir cómo responderá una célula a un nuevo fármaco. El modelo está literalmente aprendiendo la gramática y la semántica de la biología celular.
Beto
Es un nivel completamente distinto de reconocimiento de patrones.
¿Esta área también está viendo ganancias de eficiencia similares a los modelos de visión especializados?
Alicia
Absolutamente. Mira DNABERT2: es una extensión del modelo basado en BERT diseñada específicamente para decodificar el lenguaje del ADN no codificante. Logra rendimientos prometedores usando 21 veces menos parámetros que su predecesor, DNABERT. Este giro hacia arquitecturas altamente eficientes pero aún especializadas es una tendencia mayor en todo el dominio. Nos estamos volviendo más inteligentes sobre cómo entrenar, no solo más grandes.
Beto
Esa capacidad de generalizar conocimiento es la recompensa práctica.
Pasemos a las líneas clínicas y hablemos de aplicaciones que ilustran inmediatamente el valor de los FMs en el flujo de trabajo clínico. Empecemos con los aspectos más destacados para aplicaciones de procesamiento de lenguaje natural ("Natural Language Processing", NLP) clínico.
Alicia
El valor inmediato reside en mejorar la comunicación y reducir masivamente la carga administrativa. En NLP clínico, los CLLMs están impulsando chatbots y asistentes virtuales que pueden proporcionar respuestas precisas y relevantes para preguntas específicas del paciente extraídas directamente de notas clínicas complejas. Hay estudios que muestran que chatbots médicos ofrecieron recomendaciones de calidad comparable a expertos humanos en ciertos escenarios de triaje.
Beto
Eso es potente.
¿Y la traducción? El lenguaje médico suele ser intencionalmente complejo, incluso en la lengua materna del paciente.
Alicia
Sí, los FMs muestran alta precisión para la traducción contextual del lenguaje médico. Esto simplifica la terminología compleja: por ejemplo, convertir “edema periférico” en “hinchazón del tobillo” o “hipertensión” en “presión arterial alta” para los pacientes. Esto mejora enormemente la accesibilidad comunicativa para pacientes y cuidadores.
Beto
Si estos CLLMs simplifican la terminología médica en tiempo real, ¿existe el riesgo de que sobre-simplifiquemos y perdamos matices importantes en el proceso? Por ejemplo, “hipertensión” es más específico que simplemente “presión arterial alta” en una ficha clínica compleja.
Alicia
Ese es un reto muy real. La utilidad está en traducir para el paciente y mejorar su comprensión y adherencia al tratamiento. Para el clínico, el modelo debe mantener absolutamente esa terminología técnica de alta fidelidad. Por tanto, los sistemas necesitan salvaguardas robustas para saber cuándo actúan como comunicadores para el paciente y cuándo como asistentes clínicos. El objetivo es accesibilidad, no desinformación.
Beto
Esa utilidad de traducción es fantástica. Pero cambiemos al área donde vemos el mayor dramatismo clínico: aplicaciones de visión por computadora médica.
Alicia
Dos aplicaciones destacan especialmente: mejora/reconstrucción de imágenes y asistencia aumentada en procedimientos. Los FMs son muy eficaces en la reconstrucción de imágenes, abordando problemas inversos complejos como la reconstrucción acelerada de RM, incluso cuando el sujeto se mueve y arruina a menudo una exploración.
Beto
Pero aquí hay un punto crítico en la mejora que apareció en las fuentes: la idea de sintetizar datos. Háblanos más sobre la posibilidad de tomar hardware de gama baja y generar resultados de alta gama.
Alicia
Esto cambia por completo la ecuación de acceso diagnóstico.
Usando técnicas de superresolución, los FMs podrían potencialmente permitir que hospitales con RM de 1.5 T, que son estándar y asequibles, sinteticen datos comparables a RM de 7 T. Las resonancias de 7 teslas ofrecen una resolución significativamente mayor: permiten detectar estructuras y lesiones mucho más pequeñas, pero son increíblemente caras y raras.
Beto
Sintetizar 7 T a partir de una máquina de 1.5 T cambia la ecuación para hospitales rurales o clínicas en países en desarrollo. ¿Puedes darnos un ejemplo breve de un diagnóstico que se vuelva posible con esos datos sintetizados que antes no lo era?
Alicia
Claro. Piensa en enfermedades neurodegenerativas en etapa temprana como la esclerosis múltiple (EM). Las lesiones sutiles de la sustancia blanca asociadas con la EM suelen ser difíciles de caracterizar definitivamente en una exploración estándar de 1.5 T. La resolución mejorada sintetizada por el FM podría permitir a un radiólogo detectar y analizar esas pequeñas lesiones con la precisión que antes estaba reservada a centros de investigación avanzados. Eso impacta significativamente la precisión diagnóstica y el acceso a capacidades de imagen de alta gama.
Beto
Es una aplicación realmente transformadora para la accesibilidad global.
¿Qué hay de la asistencia en tiempo real durante procedimientos?
Alicia
Los FMs están integrando datos multimodales para proporcionar asistencia en tiempo real durante procedimientos complejos como la cirugía. Esta asistencia va desde anotar transmisiones de vídeo en vivo — identificando instantáneamente anatomía o instrumentos — hasta, aún más crítico, alertar a los equipos quirúrgicos si se omite un paso procedimental requerido, lo que mejora la seguridad del paciente y asegura la consistencia del procedimiento.
Beto
Todo eso suena increíblemente prometedor, pero al avanzar hacia la parte final de nuestra inmersión profunda, tenemos que discutir los desafíos críticos que enfrentan estos FMs en la atención sanitaria, que exige un pensamiento crítico extremadamente cuidadoso.
Alicia
Y esto plantea una pregunta importante: ¿podemos siquiera costearlos?
La inmensa escala de estos modelos presenta un desafío significativo en términos de coste y requerimientos. Entrenar MedSAM, por ejemplo, requirió 20 GPUs Nvidia A100 totalizando 1.600 gigabytes de memoria. Esta pura demanda computacional limita la accesibilidad para muchos investigadores en entornos clínicos más pequeños y podría concentrar la innovación en unas pocas grandes instituciones.
Beto
Y más allá del coste del hardware, hay un problema de confianza en situaciones de vida o muerte. Tenemos que hablar de interpretabilidad o la naturaleza de «caja negra» de los FMs, que es un gran obstáculo para la adopción clínica. Los clínicos exigen transparencia y una justificación clara para un diagnóstico.
Alicia
Y el problema es que las técnicas generales de interpretabilidad — como fijarse en qué partes de los datos el modelo prestó más atención — sólo proporcionan intuiciones superficiales: muestran correlaciones. En asistencia sanitaria necesitamos métodos causales. Debemos ir más allá de “esto está correlacionado con la enfermedad” a “esto causa la enfermedad”.
Beto
Necesitamos métodos causales, no correlaciones espurias.
Para un clínico, ¿cuál es la diferencia práctica entre saber que algo ayuda y saber exactamente por qué ayuda?
Alicia
Es la diferencia entre confiar ciegamente en una caja negra y tener una validación biológica. Si una IA sugiere un diagnóstico basado en una correlación espuria — por ejemplo, asociar cáncer de pulmón con que el expediente del paciente fue escaneado un martes — eso es peligroso. Los métodos causales obligan al modelo a basar su decisión en mecanismos biológicos subyacentes, como identificar la expresión de una proteína específica o la morfología celular. Sin una causalidad clara que vincule la lógica del IA con el conocimiento biológico aceptado, la adopción clínica seguirá siendo limitada.
Beto
Luego está la amenaza crítica a la seguridad del paciente: la imprecisión y la preocupación más inmediata y peligrosa en medicina son las alucinaciones.
Alicia
La alucinación, para quienes no lo conocen, es la generación de información plausible pero inexacta o no verificada. Si un modelo genera una nota clínica alucinada o recomienda un plan de tratamiento no verificado, el potencial de daño al paciente es extremadamente alto. En un entorno sanitario, ese nivel de falta de fiabilidad es simplemente inaceptable.
Beto
Entonces, ¿qué significa todo esto para los investigadores y desarrolladores que intentan navegar estos enormes desafíos técnicos y logísticos? ¿Cuál es la lección principal aprendida aquí?
Alicia
La lección mayor es que los modelos fundacionales deben ser rigurosamente adaptados al dominio médico. No pueden simplemente portarse desde dominios generales sin una intensa especialización para ser efectivos. Y esto lo vemos consistentemente: modelos especializados como el GatorTronGPT que discutimos antes superan de forma significativa y consistente a sus contrapartes generalizadas en tareas médicas complejas como preguntas biomédicas y reconocimiento de entidades nombradas. La especialización no es negociable para la seguridad y la eficacia.
Beto
Así que los modelos fundacionales están aquí y están revolucionando la atención sanitaria al permitir la síntesis comprensiva de datos diversos — texto, imagen y ómicas — para ofrecer soporte diagnóstico y terapéutico poderoso que antes era inimaginable.
Alicia
Y las oportunidades futuras son particularmente emocionantes, sobre todo en áreas actualmente limitadas por la escasez de datos, como las enfermedades raras. Los FMs, mediante aprendizaje por transferencia, pueden adaptar representaciones robustas aprendidas en enfermedades comunes y luego afinarse a nuevos dominios con datos especializados mínimos usando lo que se llama aprendizaje few-shot o zero-shot. Esta capacidad de generalizar conocimientos fundamentales abrirá verdaderamente nuevas fronteras diagnósticas y terapéuticas.
Beto
Eso nos devuelve al mayor desafío que tocamos antes: el que está ligado directamente al coste y la escala. Y aquí hay algo en qué pensar mientras procesas esta inmersión profunda: si los únicos que pueden permitirse entrenar estos enormes modelos de 70.000 millones de parámetros son un puñado de instituciones con muchos recursos, ¿cómo garantizamos que la IA resultante, que nos afecta a todos, sea verdaderamente representativa y no esté sesgada hacia la población global, en lugar de ser simplemente un reflejo de los bancos de datos más ricos y de mayor intensidad de recursos?



{kind=link}