
Este informe técnico describe la rápida aceleración de las capacidades de la IA a lo largo de 2025, destacando que los modelos de vanguardia superan con frecuencia el rendimiento humano. Si bien los indicadores técnicos muestran una reducción de la brecha entre los principales competidores globales y una convergencia del rendimiento entre los proveedores más importantes, los investigadores advierten que estas pruebas se están saturando o volviendo poco fiables. El informe documenta avances significativos en tareas lingüísticas especializadas, comprensión de vídeo y agentes autónomos, aunque señala que estos sistemas aún enfrentan desafíos en cuanto a la fiabilidad en el mundo físico y el razonamiento complejo. Los modelos están evolucionando desde simples generadores de texto hasta agentes capaces y sistemas multimodales que comienzan a simular leyes físicas. A pesar de estos avances, la "inteligencia irregular" sigue siendo un obstáculo, ya que los modelos pueden sobresalir en matemáticas avanzadas, pero fallar en tareas sencillas y de sentido común, como leer la hora. En definitiva, el ritmo de la innovación en IA está superando actualmente los marcos utilizados para evaluar y gestionar estas potentes tecnologías.
Enlace al reporte científico, para aquellos interesados en profundizar sobre el tema: "AI Index Report 2026 - Chapter 2 - Technical Performance". Publicado el 13 de Abril de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Ahora mismo existe una IA que puede ganar una medalla de oro en la Olimpiada Internacional de Matemáticas.
Alicia
Lo cual es una locura pensarlo.
Beto
Lo es. Quiero decir, literalmente podría resolver física a nivel de posgrado.
Alicia
Sí.
Beto
Pero si le pides a esa misma supercomputadora que, ya sabes, mire una foto de un reloj de pared estándar.
Alicia
Correcto. Un reloj analógico.
Beto
Sí. Y que te diga la hora, falla el 50 % de las veces. Es como lanzar una moneda.
Alicia
Literalmente una tirada de moneda.
Beto
Bien. Bienvenidos a nuestro análisis profundo del material fuente.
Alicia
Ajá.
Beto
Hoy vamos a diseccionar el informe recién publicado del Stanford AI Index para 2026 para entender realmente esta extraña realidad contradictoria de lo que la IA puede hacer ahora mismo.
Alicia
Sí. Porque es abril de 2026. Y vivimos firmemente en esta era de lo que el informe llama "inteligencia irregular".
Beto
Sí, me gusta esa frase.
Alicia
Es muy acertada. Estamos viendo a estos modelos de frontera realizar hazañas de razonamiento aparentemente imposibles, casi divinas. Pero al mismo tiempo se colapsan en tareas espaciales y lógicas que un niño humano haría sin pensarlo dos veces.
Así que nuestra misión hoy es cortar todo el ruido y el bombo incesante de la industria. Queremos trazar la verdadera frontera de capacidad para ustedes, enfocándonos específicamente en los datos del capítulo dos.
Beto
Que es la sección sobre desempeño técnico.
Alicia
Exacto.
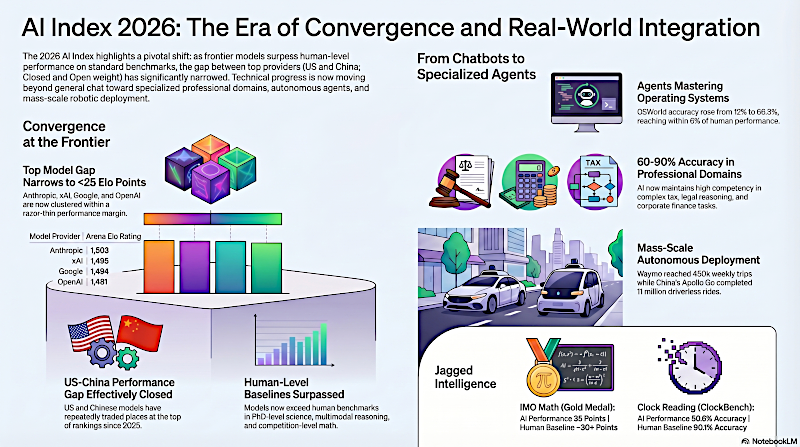
Indice IA 2026: La Era de la Convergencia e Integración con el Mundo Real
Beto
Vale. Desgranémoslo porque, ya sabes, si sigues este espacio al menos un poco, la velocidad es abrumadora. Parece imposible mantenerse al día.
Alicia
Oh, totalmente.
Beto
Hablamos de algoritmos invisibles que por la mañana pueden mover mercados de billones de dólares, y por la tarde están manejando robots humanoides en fábricas automotrices físicas.
Alicia
Sí, el alcance es masivo.
Beto
Es como intentar medir la velocidad de un cohete con un radar de mano. Las herramientas que tenemos se están rompiendo ante la rapidez del avance.
Alicia
Sí.
Beto
Pero para entender lo que estos sistemas son genuinamente capaces de hacer, primero tenemos que mirar la imagen macro.
Alicia
Bien, hay que mirar la propia carrera.
Beto
Exacto.
Alicia
Sí.
Beto
El panorama competitivo, que se ha reconfigurado por completo en los últimos 12 meses.
Alicia
De verdad que sí. La brecha competitiva entre los actores principales no solo se ha estrechado. Prácticamente ha desaparecido.
Beto
Desaparecido. Como totalmente.
Alicia
Prácticamente. Quiero decir, si miras la tabla de clasificación de Arena, que, para quien no lo sepa, clasifica modelos según preferencia humana usando un sistema de puntuación ELO estilo ajedrez emparejado, los cuatro principales están actualmente agrupados dentro de apenas 25 puntos entre sí.
Beto
25 puntos.
Alicia
Sí. A marzo de 2026, Anthropic está en 1.503 puntos.
Beto
OK.
Alicia
Y siguiéndole por fracciones literales tienes a XAI en 1.495.
Beto
Así que una diferencia de ocho puntos.
Alicia
Correcto. Google está en 1.494.
Beto
Wow.
Alicia
Y OpenAI está en 1.481.
Beto
Esas márgenes son prácticamente inexistentes. Es una llegada muy ajustada.
Alicia
Sí, ya no hay un vencedor claramente despegado.
Beto
Y no son solo los grandes gigantes tecnológicos estadounidenses agrupados en la cima. La división geográfica en la que antes nos centrábamos tanto, eso esencialmente se ha cerrado.
Alicia
Se ha evaporado por completo. A lo largo de principios de 2025, los mejores modelos de EE. UU. y de China intercambiaban rutinariamente la primera posición.
Beto
Correcto.
Alicia
Actualmente, el mejor modelo estadounidense, que es Claude Opus 4.6, lidera al mejor modelo chino, Dola-Seed-2.0 Preview, por apenas un margen del 2,7 %.
Beto
2,7 %. Eso no es nada. Y tenemos que hablar del catalizador de ese cierre de brecha.
Alicia
Oh, absolutamente. El momento de febrero de 2025.
Beto
Sí, en febrero de 2025, cuando el Deepseek R1 de China temporalmente igualó al mejor modelo estadounidense. Pero la onda expansiva no fue solo que alcanzaran la cima, ¿verdad? El pánico en la industria vino del mecanismo subyacente de cómo entrenaron su capacidad de razonamiento.
Alicia
Exacto. Utilizaron un enfoque de aprendizaje por refuerzo llamado GRPO.
Beto
OK, explícanos eso. ¿Por qué GRPO cambió todo el panorama?
Alicia
Bueno, tienes que ver cómo se entrenaba el razonamiento antes. Históricamente, requería enormes cantidades de datos etiquetados por humanos, extremadamente caros.
Beto
Como pagar a doctorados para que escribieran soluciones de matemáticas paso a paso.
Alicia
Sí. O necesitabas un modelo crítico separado, muy complejo, para evaluar constantemente la salida de la IA durante el entrenamiento. Ambos enfoques consumen muchísimos recursos.
Beto
Correcto.
Alicia
GRPO evitó todo eso. Entrenó la habilidad de razonamiento generando grupos de salidas y comparándolos contra reglas objetivas predefinidas. Eliminaron por completo los cuellos de botella humanos más costosos en la cadena de entrenamiento.
Beto
OK, para usar una analogía, es básicamente como en vez de contratar a un tutor privado caro, para que esté encima de un estudiante corrigiendo cada línea de su tarea de matemáticas, simplemente le das al estudiante una rúbrica. Le dices, oye, intenta estas 10 maneras diferentes de resolver el problema. El camino que te dé la respuesta matemáticamente correcta al final, recuerda esos pasos.
Alicia
Esa es una forma perfecta de visualizarlo. Para eliminar la necesidad del tutor humano por completo.
Beto
Wow.
Alicia
Y cuando el mercado en general se dio cuenta de que el estado del arte en razonamiento podía alcanzarse sin gastar miles de millones en esos pipelines de datos etiquetados por humanos, la reacción fue violenta.
Beto
Oh, provocó una caída temporal de 1 billón de dólares en el valor del mercado bursátil tecnológico de EE. UU.
Alicia
Un billón de dólares. Simplemente borrado.
Beto
Porque los inversores, de repente, entendieron que los modelos de negocio masivamente intensivos en capital, de estos grandes, podían verse severamente socavados por esta nueva eficiencia.
Alicia
Exacto. El voto se fue.
Beto
Pero bien, aquí es donde se pone realmente interesante. Voy a cuestionar esto un poco. Si los modelos COP4 están separados por menos de 30 puntos y los modelos de peso abierto, donde la arquitectura subyacente está disponible libremente para desarrolladores, solo están a un 3,3 % por detrás de los modelos propietarios de peso cerrado ...
Alicia
Sí.
Beto
¿Qué están vendiendo realmente estas compañías?
Alicia
Esa es la pregunta de un millón de dólares.
Beto
¿Cómo compites cuando todo el mundo básicamente tiene una A+ en razonamiento?
Alicia
Sí.
Beto
¿No significa eso que la parte de inteligencia se está convirtiendo en una commoditiy? ¿Ahora competimos solo en quién lo hace más barato?
Alicia
Honestamente, sí. Estamos viendo un giro fundamental alejándose de la capacidad bruta como diferenciador principal.
Porque los modelos están funcionalmente empatados en inteligencia pura, la carrera se ha desplazado hacia la eficiencia operativa.
Beto
Eficiencia.
Alicia
Los proveedores ahora compiten en costo, latencia, confiabilidad y utilidad específica por dominio.
Beto
Así que ya no se trata de ser el más inteligente.
Alicia
No. La pregunta definitiva para un negocio, no es quién tiene el modelo más inteligente. Es quién puede ejecutar este pipeline específico más barato, más rápido y con menos alucinaciones.
Beto
Pero si todos están tan juntos en la cima de la curva de capacidad, ¿cómo medimos su inteligencia con precisión? Quiero decir, si las diferencias son fraccionales, parece que los benchmarks tradicionales que usamos para probarlos simplemente se están rompiendo.
Alicia
Se están rompiendo por completo. Los marcos de evaluación se están saturando mucho más rápido de lo que los investigadores pueden inventarlos.
Beto
Dame un ejemplo.
Alicia
OK. Considera un benchmark que literalmente se llama "Humanities Last Exam".
Beto
Humanities Last Exam, suena ominoso.
Alicia
Correcto. Fue deliberadamente diseñado para ser increíblemente difícil para la IA, apoyándose en profundo conocimiento humano y casos límite extraños.
Beto
Bien.
Alicia
Aún así, en un solo año, los modelos de frontera subieron 30 puntos porcentuales en esta prueba.
Beto
30 puntos en un año.
Alicia
Sí, ahora están en 38,3 %. Y además, estamos descubriendo que las pruebas en sí a menudo están estructuralmente defectuosas.
Beto
¿Qué quieres decir con defectuosas? ¿Que las preguntas están mal?
Alicia
A veces, sí. Una revisión muy profunda reciente reveló que hasta el 42 % de las preguntas en un benchmark ampliamente usado para matemáticas, llamado GSM 8K, eran en realidad inválidas. O bien, por mala redacción, o simplemente por indicios de respuesta incorrectos.
Beto
Espera, casi la mitad del test está roto.
Alicia
Exacto.
Beto
Los investigadores están esencialmente intentando medir un objetivo en movimiento con herramientas que literalmente se les están desmoronando en las manos.
Alicia
Es una crisis total de benchmarks.
Beto
Pero incluso con benchmarks defectuosos, la escala de la capacidad es innegable. Quiero decir, mira los resultados en la Olimpiada de Matemáticas.
Alicia
Ah, la ejecución de Gemini DeepThink.
Beto
Sí. En 2025, Gemini DeepThink de Google sacó 35 puntos para ganar la medalla de oro en la Olimpiada Internacional de Matemáticas. Eso viene de una plata el año anterior, ¿no?
Alicia
Síp. Salto masivo.
Beto
No se limitó a hacer pattern matching de soluciones existentes. Funcionó de extremo a extremo en lenguaje natural. Produjo pruebas matemáticas rigurosas paso a paso dentro de un límite de tiempo estricto.
Alicia
Es brillante en eso. Pero, y este es el gran pero, volvemos a la paradoja de la inteligencia irregular.
Beto
La curva de capacidad dentada.
Alicia
Correcto. Sí. Porque ese mismo sistema que puede sintetizar una prueba matemática a nivel de olimpiada, se desmorona por completo en un benchmark llamado "Clock Bench".
Beto
Clock Bench. Que es solo leer un reloj.
Alicia
Simplemente leer un reloj. Cuando a humanos se les pide leer un reloj analógico correctamente formateado en este benchmark, alcanzan un 90,1 % de precisión.
Beto
Bien. Tiene sentido.
Alicia
El mejor modelo de IA actualmente solo alcanza un 50,1 %.
Beto
Básicamente una tirada de moneda.
Alicia
Exacto.
Beto
Y al observar los datos en el informe, la naturaleza del fallo es lo que me parece tan extraño. Cuando un humano lee mal un reloj, puede estar equivocado por, ¿dos o tres minutos? Porque juzgamos mal las pequeñas marcas de los ticks.
Alicia
Sí. Un error visual menor.
Beto
Pero el informe muestra que el error mediano de la IA está entre una y tres horas.
Alicia
Las horas, sí.
Beto
¿Cómo un sistema con la potencia computacional para resolver física de posgrado comete un error fundamental tan gigantesco?
Alicia
Se reduce al mecanismo del fallo. Tienes que ver cómo los modelos multimodales procesan información visual y aritmética simultáneamente.
Beto
OK.
Alicia
Leer un reloj analógico requiere que el modelo identifique visualmente la manecilla de la hora y la de los minutos, calcule sus ángulos respectivos y luego traduzca esa geometría a un valor numérico de hora.
Beto
Correcto. Es combinar percepción y matemáticas.
Alicia
Exacto. Y si el modelo comete un pequeño error visual, por ejemplo, confunde la manecilla de la hora por la de los minutos debido a sutiles diferencias de píxeles, no solo falla en los minutos.
Beto
Su razonamiento espacial se derrumba.
Alicia
Falla en cascada completa. El error se propaga a través de todo el cálculo matemático, resultando en una discrepancia de varias horas; pierde por completo la lógica fundamental de la fase del reloj.
Beto
Así que es exactamente como tener un amigo que puede resolver complejas ecuaciones de física cuántica en su cabeza, pero luego pasa cinco minutos empujando una puerta con barra.
Alicia
Eso es exactamente a lo que se parece.
Beto
Realmente te obliga a cuestionar si puedes confiar en estos modelos para tareas básicas y cotidianas, incluso si tiene una medalla de oro en razonamiento.
Alicia
Tienes que ser cuidadoso.
Beto
Porque si se pierde completamente al leer la fase de un reloj porque la estructura visual lo enredó, ¿qué pasa cuando mira un desordenado documento fiscal corporativo de 200 páginas que no coincide perfectamente con sus datos de entrenamiento?
Alicia
Y esa es la advertencia crucial aquí. Esta irregularidad no es solo una falla curiosa con relojes. No puedes asumir que la competencia en un dominio altamente abstracto y complejo se transferirá de forma suave a la realidad estructurada y anclada. La inteligencia irregular significa que la curva de capacidad no es una pendiente predecible. Se caracteriza por acantilados abruptos. Y esos acantilados se convierten en pasivos enormes cuando pasas de benchmarks académicos al mundo profesional.
Beto
Bien, sigamos ese acantilado en el mundo profesional entonces. Porque todos queremos una IA que pueda ingerir documentos masivos y manejar trabajo de cuello blanco.
Alicia
Ese es el sueño.
Beto
Y estructuralmente tienen la capacidad. Hemos visto ventanas de contexto —que es la cantidad de texto que una IA puede mantener en su memoria activa— crecer 30 veces al año.
Alicia
Es enorme ahora.
Beto
Sí, tenemos modelos capaces de ingerir un millón de tokens, libros enteros, bases de código enteras.
Alicia
Pero la suposición en el sector empresarial siempre ha sido que memoria masiva equivale a comprensión profunda. Y el benchmark LongBench V2 expone la falla en esa suposición. Esta prueba evalúa la comprensión a nivel experto de documentos largos bajo un límite de tiempo.
Beto
OK, ¿cómo les va?
Alicia
Bueno, los expertos humanos obtuvieron 53,7 %. El mejor modelo de IA solo obtuvo 57,7 %.
Beto
Espera, ¿así que la IA apenas supera a los humanos?
Alicia
Apenas.
Beto
Lo que significa que tener una ventana de contexto de un millón de tokens no es como tener un súper cerebro analizando un libro. Es más como tener un millón de notas adhesivas esparcidas por un escritorio enorme.
Alicia
Esa es una gran forma de decirlo.
Beto
Encontrar una nota específica, como una aguja en un pajar, es increíblemente fácil para la IA. Pero si le pides a la IA que escriba un resumen coherente de cómo todas esas notas se relacionan lógicamente entre sí, se sobrecarga por completo.
Alicia
Exacto. Porque esa síntesis requiere aplicar lógica condicional compleja sobre enormes cantidades de texto simultáneamente.
Beto
Y no lo hacen bien.
Alicia
No, los modelos tienen grandes dificultades con este tipo de síntesis espacial y lógica a menos que los forces meticulosamente a procesar la información paso a paso.
Beto
Lo cual es lento.
Alicia
Hace que el proceso sea computacionalmente caro y muy lento.
Beto
Y los números duros en dominios profesionales de alto riesgo reflejan perfectamente esta lucha. Quiero decir, campos como impuestos, procesamiento hipotecario, finanzas corporativas, la IA está teniendo problemas para cruzar la línea de meta.
Alicia
Sí, las estadísticas son duras.
Beto
En el CorpFin Benchmark que analiza complejos acuerdos de crédito corporativo de 200 páginas, el mejor modelo, Kimi K 2.5, solo logró un 68,26 % de precisión.
Alicia
Lo cual no es bueno para finanzas.
Beto
No. Y en hipotecas y impuestos, donde se extrae información condicional específica de certificados fiscales complejos, Gemini 3.1 Pro Preview se queda en 64,49 %.
Alicia
Y oye, una tasa de precisión del 68 % en finanzas corporativas no es una solución. Es una responsabilidad grave. Para entender el mecanismo de por qué fallan en estas tareas, tenemos que mirar un benchmark llamado Plan Bench.
Beto
OK, ¿qué prueba Plan Bench?
Alicia
Evalúa la capacidad de la IA para secuenciar acciones para lograr un objetivo específico. Entendiendo condiciones altamente reconocibles, los modelos se desempeñan muy bien. Pero los investigadores hicieron algo interesante. Ofuscaron la prueba.
Beto
¿Qué significa eso? Ocultaron los datos.
Alicia
Tomaron el mismo problema lógico exacto, pero describieron la estructura de forma diferente. Reemplazaron términos familiares por palabras sin sentido.
Beto
Oh, interesante.
Alicia
Y los modelos se colapsaron. Deepseek R1 bajó de resolver 28 de 45 tareas en el dominio Blox World a solo tres de 45.
Beto
Espera, solo por cambiar el vocabulario del prompt.
Alicia
Sí, de 28 a tres.
Beto
Es una caída asombrosa. Me dice que si una IA tiene solo un 68 % de exactitud leyendo un documento hipotecario, ¿no está en realidad creando más trabajo para el humano que tiene que revisar meticulosamente cada línea?
Alicia
A menudo, sí.
Beto
¿No estamos confundiendo completamente una enorme capacidad de memoria con verdadera inteligencia generalizada?
Alicia
En muchas aplicaciones profesionales, sí, lo estamos haciendo. El fallo del Plan Bench prueba que los modelos de lenguaje no son planificadores clásicos.
Beto
OK, ¿qué es un planificador clásico?
Alicia
Un planificador clásico busca sistemáticamente una solución lógica paso a paso. Los modelos de lenguaje, sin embargo, generan planes basándose en patrones estadísticos aprendidos de sus datos de entrenamiento.
Beto
Oh, así que es solo reconocimiento de patrones.
Alicia
Sí, básicamente. Cuando disfrazas el problema o cuando el documento hipotecario se desvía ligeramente del formato estándar, ese reconocimiento de patrones se rompe.
Beto
La falta subyacente de razonamiento lógico generalizado queda completamente expuesta.
Alicia
Exacto. Y si la verificación humana toma más tiempo que la generación de la IA, la herramienta pierde su utilidad en la empresa.
Beto
Wow. Así que hemos establecido que la IA tiene problemas para navegar perfectamente el mundo digital profesional cuando el patrón estadístico se rompe. Llevémoslo aún más lejos.
Alicia
OK.
Beto
¿Qué pasa cuando la desatamos en el mundo físico, desordenado y completamente no mapeado en el que vivimos realmente? ¿Cuál es el estado real de agentes, autonomía y robots en 2026?
Alicia
Bien, empecemos con las buenas noticias. Si miramos entornos puramente de software, los agentes digitales están teniendo éxito a un ritmo impresionante.
Beto
En ordenadores.
Alicia
Correcto. En WebArena, que prueba navegación autónoma web, los agentes han alcanzado una tasa de éxito del 74,3 %.
Beto
Eso está bastante cerca de la línea base humana, ¿no?
Alicia
Muy cerca. La línea base humana es 78,2 %.
Y en OSWorld, que prueba la habilidad para navegar un sistema operativo de ordenador, Claude Sonnet 4.6 está alcanzando el 72,1 %.
Beto
Así que pueden navegar una hoja de cálculo, gestionar archivos o reservar un vuelo en línea relativamente bien.
Alicia
Sí, el reino digital se está solidificando.
Beto
Pero cuando miramos fuera del monitor del ordenador, los avances se vuelven salvajes. Hay una sección en este informe de Stanford sobre generación de vídeo que cambia fundamentalmente cómo pensamos sobre estos modelos.
Alicia
Los datos Veo 3.
Beto
Sí. Veo 3 de Google DeepMind. No estaba solo generando imágenes hiperrealistas ya. Cuando se testó en 18.000 vídeos, los investigadores encontraron que el modelo estaba aprendiendo física fundamental real.
Alicia
Y el punto crítico aquí es que fue zero-shot.
Beto
Es decir, no fue entrenado explícitamente en eso.
Alicia
Correcto. El modelo nunca fue entrenado explícitamente en ecuaciones de física o dinámica de cuerpos rígidos. Simplemente, procesando millones de horas de píxeles de vídeo, aprendió a simular flotabilidad, gravedad e incluso resolver laberintos visuales.
Beto
Solo por ver moverse los píxeles.
Alicia
Exacto. Basado en lo que los investigadores llaman "razonamiento en cadena de fotogramas", "chain-of-frames reasoning", predice cómo una escena física debe evolucionar lógicamente paso a paso en base a leyes físicas. El modelo está esencialmente construyendo un modelo interno del mundo, una comprensión fundacional de cómo funciona la física.
Beto
Eso es alucinante. Pero un modelo interno del mundo que existe en un enorme centro de datos es completamente distinto de una máquina de metal intentando operar físicamente en tu salón.
Alicia
Totalmente distinto.
Beto
El chequeo de la realidad robótica en este informe es genuinamente brutal.
Alicia
Lo es. Si miras el benchmark Behavior-1K, que prueba manipulación al alcance en ambientes domésticos realistas, los robots aún fallan el 88 % de las veces.
Beto
¿88 %?
Alicia
Sí. El mejor equipo solo logró una tasa de éxito completa del 12,4 % en tareas domésticas estándar.
Beto
¿Y la seguridad?
Alicia
Tampoco bien. En ResponsibleRobotBench, que evalúa la seguridad, incluso el mejor modelo absoluto, que es GPT-4o, opera de forma segura solo el 64 % del tiempo.
Beto
Realmente subraya una realidad marcada. El mundo físico es infinitamente más caótico, impredecible y despiadado que un entorno digital curado o un vídeo simulado.
Alicia
Definitivamente.
Beto
¿Qué significa todo esto para la línea de tiempo de la autonomía? Porque tenemos excepciones evidentes donde la autonomía física funciona a escala.
Alicia
Las tenemos. Coches y fábricas.
Beto
Waymo está registrando 450.000 viajes semanales sin conductor en ciudades de EE. UU. En China, Baidu Apollo Go alcanzó 11 millones de viajes totalmente sin conductor solo en 2025. Eso es un aumento del 175 %.
Alicia
Escala masiva.
Beto
Y en manufactura, el robot humanoide de Figure AI, el Figure O2, pasó 11 meses en la planta de BMW, cargando con éxito 90.000 piezas en vehículos.
Alicia
Sí.
Beto
Entonces mi pregunta es: ¿por qué una IA puede navegar perfectamente, por una calle caótica y lluviosa, en un coche sin conductor en San Francisco, pero no puede doblar mi ropa, sin una probabilidad del 88 % de fallar? ¿Cuál es el eslabón perdido aquí?
Alicia
El eslabón perdido es el cuello de botella de datos.
Beto
El cuello de botella de datos.
Alicia
Sí. Piénsalo. Los modelos de lenguaje escalaron exponencialmente porque pudimos alimentarlos con miles de millones de páginas de texto, scrapeadas de Internet.
Beto
Bien. Datos fáciles.
Alicia
Los modelos visión-lenguaje-acción, que son la arquitectura subyacente requerida para robots de propósito general, necesitan datos físicos espaciales.
Beto
Oh, ya veo.
Alicia
No puedes raspar de Internet la resistencia táctil de doblar una toalla o el par preciso necesario para abrir un frasco específico. Cada pieza de datos de entrenamiento requiere un robot físico realizando la tarea o una simulación de alta fidelidad y muy compleja.
Beto
Entonces, ¿por qué funcionan coches y fábricas?
Alicia
Porque los coches autónomos y los robots de fábrica operan en entornos mapeados y fuertemente restringidos donde las empresas han pasado una década recopilando datos espaciales altamente especializados; tu salón no está mapeado completamente. Es infinitamente variable. Le falta ese dato fundacional de entrenamiento.
Beto
Wow. Así que siempre vuelve a la irregularidad de la curva de capacidad.
Alicia
Así es.
Beto
Sinteticemos todo esto. El panorama de la IA en 2026 es una paradoja increíble.
Alicia
Realmente lo es.
Beto
Es más rápido, más barato y los modelos principales convergen en sus capacidades brutas. Vemos sistemas que pueden ganar una medalla de oro en una olimpiada de matemáticas, internalizar las leyes de la física solo viendo cómo se mueven los píxeles y conducirte de forma segura en un taxi aéreo autónomo.
Pero no puedes confiar ciegamente en que lea un reloj analógico. Cometerá errores lógicos críticos al analizar un documento hipotecario complejo.
Alicia
Sí.
Beto
Y ciertamente no puede ordenar tu cocina.
Alicia
Que es precisamente por lo que entender el mecanismo de la inteligencia irregular es tan crítico para ti ahora mismo. A medida que integras estas herramientas en tu vida diaria, o en tus flujos de trabajo profesionales, debes permanecer como supervisor humano.
Beto
No puedes simplemente programarlo y olvidarte.
Alicia
Exacto. Puedes aprovechar la IA para síntesis masiva, para lluvia de ideas rápida o para ayuda en programación, pero debes verificar de forma independiente la lógica fundamental. Tienes que anticipar esos acantilados repentinos donde el reconocimiento de patrones falla.
Beto
Porque puede resolver la parte matemática más compleja de tu trabajo perfectamente y luego fallar en un detalle espacial básico que un niño de cinco años detectaría instintivamente.
Alicia
Precisamente. Y quiero dejarte con un pensamiento final para que lo explores por tu cuenta.
Beto
OK. Vamos.
Alicia
Hablamos de cómo los modelos de generación de vídeo están construyendo modelos internos del mundo de la física solo procesando píxeles.
Beto
Correcto. El Veo 3.
Alicia
Sabes que la robótica general está actualmente constreñido por una severa falta de datos táctiles físicos.
Beto
El cuello de botella de datos.
Alicia
Correcto. Bueno, ¿qué pasa cuando los millones de nuevos robots humanoides que están entrando en fábricas comiencen a transmitir continuamente datos espaciales y táctiles del mundo real de vuelta a estos modelos fundacionales masivos?
Beto
Oh, wow.
Alicia
¿Estamos al borde de ver la inteligencia física anclada escalar con la misma trayectoria explosiva que los modelos de lenguaje experimentaron hace unos años?
Beto
Esa es una pregunta fascinante a considerar a medida que estos sistemas pasan del reino digital a nuestros espacios físicos.
Alicia
Van a ser unos años salvajes.
Beto
Realmente lo serán. Recuerda, solo porque la curva de capacidad parezca un cohete no significa que vuele en línea recta.
Sigue cuestionando las salidas. Sigue verificando la lógica subyacente y sigue explorando los mecanismos detrás del bombo.
Gracias por acompañarnos en este análisis profundo del material fuente. Nos vemos la próxima vez.



{kind=link}