
Este exhaustivo estudio explora el auge de los Modelos de Lenguaje Hablado (SLM), que representan un cambio de paradigma: de herramientas específicas para tareas a sistemas universales de procesamiento del habla. Estos modelos se clasifican en tres tipos principales: SLM de habla pura, que modelan distribuciones de audio; SLM de habla y texto, que aprenden representaciones conjuntas; y SLM de texto con reconocimiento de voz, que integran codificadores de audio en arquitecturas lingüísticas existentes. Mediante el uso de tokens discretos o características continuas, los SLM buscan superar los sistemas tradicionales en cascada para lograr un razonamiento integral y una menor latencia. El texto describe diversas estrategias de entrenamiento, como el ajuste de instrucciones y la optimización de preferencias, que permiten a los modelos seguir indicaciones en lenguaje natural. También se analizan los avances clave en el diálogo bidireccional, destacando cómo las arquitecturas más recientes gestionan la interactividad y las interrupciones en tiempo real. Finalmente, los autores abordan la necesidad crucial de establecer puntos de referencia estandarizados para evaluar capacidades complejas como la comprensión paralingüística, la confiabilidad y el sesgo social.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "On The Landscape of Spoken Language Models: A Comprehensive Survey", por Siddhant Arora y colegas. Publicado el 7 de Abril de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Entonces, si le das a un nuevo modelo de lenguaje hablado, un clip de audio de una habitación completamente silenciosa, en realidad sabe perfectamente que está en silencio.
Alicia
Exacto. Puede identificar fácilmente que está silencioso.
Beto
Exactamente. Pero si le haces al mismo modelo la pregunta, "¿hay un perro ladrando en este audio?", a menudo te dirá con confianza que "sí".
Alicia
Lo cual es bastante alucinante si lo piensas.
Beto
Es totalmente alucinante. Bienvenidos al desordenado, propenso a alucinaciones, pero absolutamente revolucionario mundo de la IA nativa de audio. Hoy vamos a bucear profundo en una encuesta enorme de Siddhant Arora y colegas, titulada "On the Landscape of Spoken Language Models".
Alicia
Y es una mirada realmente completa a dónde estamos ahora mismo.
Beto
Sí. Y nuestra misión hoy para ti, oyente, es trazar este enorme cambio de paradigma. Nos estamos alejando de esos rígidos bots de voz de tarea única que te obligan a pasar por esos interminables menús.
Alicia
Oh, lo peor.
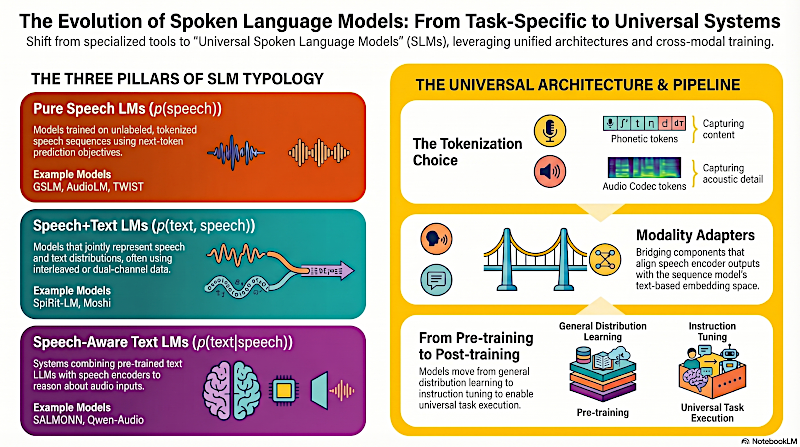
Evolución de los Modelos de Lenguaje Hablado: De específico para tareas a Sistemas Universales
Beto
Claro. Así que avanzamos hacia modelos universales de lenguaje hablado, o "Spoken Language Models", SLMs básicamente, existencias que podrían realizar virtualmente cualquier tarea de audio solo siguiendo una instrucción en lenguaje natural.
Alicia
Lo que realmente representa una reescritura fundamental de cómo las máquinas procesan la comunicación humana por completo.
Beto
¿Cómo es eso?
Alicia
Bueno, cuando pasas de procesar texto a procesar la voz humana de forma nativa, ya no solo estás transmitiendo vocabulario.
Beto
Exacto. Hay mucho más.
Alicia
Estás transmitiendo estado de ánimo, titubeos, identidad e incluso el entorno físico alrededor del hablante.
Beto
Wow.
Alicia
Y capturar todo eso requiere un salto tecnológico que honestamente abandona por completo la arquitectura en la que hemos confiado durante la última década.
Beto
Para entender qué es realmente un modelo universal de lenguaje hablado, creo que primero tenemos que mirar las grietas en nuestra fundación actual.
Alicia
Sí. Ese es el mejor lugar para empezar.
Beto
Porque los asistentes de voz en nuestros teléfonos ahora mismo nos parecen relativamente fluidos. Pero bajo el capó, son lo que los investigadores llaman un "sistema en cascada".
Alicia
Sí. Como una línea de montaje.
Beto
Hablas, un modelo de speech-to-text, STT, transcribe tu audio a texto, luego alimenta ese texto a un modelo de lenguaje para averiguar la respuesta, y finalmente un modelo de text-to-speech, TTS, te lee la respuesta.
Alicia
Y ese paso intermedio, el cuello de botella del texto, es en realidad un fallo fatal.
Beto
¿En serio? ¿Por qué es fatal?
Alicia
Porque al forzar la interacción a través de una transcripción plana, despojas la comunicación del sonido real.
Beto
Ah, ya.
Alicia
Pierdes la prosodia, ya sabes, el ritmo, la entonación, las micro pausas. Pierdes el tono por completo.
Beto
Bien. Pero déjame hacer de abogado del diablo por un segundo. Ya tenemos análisis de sentimiento muy sofisticados en modelos de texto, ¿no?
Alicia
Claro. Sí, los tenemos.
Beto
Entonces, en lugar de construir una arquitectura masiva nueva desde cero, ¿no podríamos simplemente, no sé, indicarle al modelo speech-to-text que añada una etiqueta? Como que transcriba las palabras pero añada una etiqueta que diga “dicho con sarcasmo” o “tono enojado” junto a ello.
Alicia
Quiero decir, es una solución intuitiva, pero se desmorona matemáticamente.
Beto
Lo hace.
Alicia
Sí, porque la prosodia no es texto discreto. Es un continuo, básicamente un espectro de dimensión infinita. No puedes reducir adecuadamente el susurro entrecortado de una respiración o la caída exacta de tono de un suspiro decepcionado a una etiqueta de texto estandarizada.
Beto
Es demasiado matizado.
Alicia
Exacto. El artículo de la encuesta lo destaca hermosamente con el problema del sarcasmo.
Beto
Ah, sí. Me encanta esa parte.
Alicia
Sí. Si alguien dice, "Oh, buen trabajo". El significado está en la forma acústica como fue dicho.
Beto
Bien. Con un suspiro pesado, y tono de voz que baja, significa todo lo contrario a que si se dijera con un tono de voz alta y energético.
Alicia
Precisamente. Así que incluso si lo etiquetas como sarcástico, el modelo de texto de la etapa siguiente sigue leyendo una etiqueta plana, en lugar de experimentar los datos sin procesar del sarcasmo.
Beto
Así que adopta una interpretación ingenua.
Alicia
Lo hace. Y en realidad es peor que eso, porque los modelos en cascada inherentemente componen errores.
Beto
Como un efecto dominó.
Alicia
Exacto. Si el modelo de speech-to-text interpreta mal esos datos acústicos sarcásticos y no añade tu hipotética etiqueta, ...
Beto
... entonces el modelo de lenguaje alucina una respuesta alegre completamente irrelevante.
Alicia
Sí. Luego el modelo de text-to-speech te lee esa tontería y súmale la latencia computacional.
Beto
¿La demora en responder?
Alicia
Sí. El modelo de transcripción tiene que esperar al límite de la oración. El modelo de lenguaje la procesa. El generador de audio crea un espectrograma. Estás matemáticamente limitado en cuán rápido puede responder el sistema.
Beto
Lo cual lo hace sentirse torpe.
Alicia
Mucho. La solución que describe el artículo es un SLM de extremo a extremo, un modelo que nativamente escucha la forma de onda de audio y nativamente habla audio de vuelta, evitando por completo ese cuello de botella del texto.
Beto
Bien. Pero eso nos lleva al obstáculo central de ingeniería aquí. Sabemos que los modelos de texto procesan la información en fragmentos discretos llamados "tokens".
Alicia
Sí. El texto se divide de manera ordenada.
Beto
Pero la voz humana no es en absoluto discreta.
Alicia
Sí.
Beto
Es una forma de onda desordenada y ondulante que vibra a miles de hercios. Entonces, ¿cómo ingiere un modelo realmente una onda sonora continua?
Alicia
Tienes que construir una canalización altamente especializada. La forma de onda cruda primero entra en un codificador de voz. El trabajo entero del codificador es cortar esa onda continua en tokens discretos.
Beto
Ah, para que sea legible.
Alicia
Exacto. Esos tokens luego pasan por un adaptador de modalidad y finalmente entran en el modelo de secuencia.
Beto
Que es como el cerebro neuronal real del sistema.
Alicia
Sí. Exacto.
Beto
Y un momento con el codificador de voz, porque los investigadores trazan una línea muy marcada entre dos filosofías completamente diferentes de tokenizar audio.
Alicia
Correcto. Tokens fonéticos y tokens de códec de audio.
Beto
Sí. ¿Por qué es tan importante esa distinción?
Alicia
Esta distinción es crítica porque básicamente dicta cómo la IA percibe la realidad.
Beto
Vaya.
Alicia
Sí. Los tokens fonéticos capturan los bloques lingüísticos, el contenido hablado, las consonantes, las vocales.
Beto
Pero eliminan la identidad, ¿verdad?
Alicia
Exacto. Y eliminan la identidad específica del hablante. Filtran si la voz es más aguda o grave y descartan el ruido de fondo. Aíslan la palabra hablada pura.
Beto
Vale. Entonces piensa en cómo tú, el oyente, estás escuchando esta conversación ahora mismo. Si tu cerebro solo procesara tokens fonéticos, sería como leer la partitura de una sinfonía.
Alicia
Es una analogía perfecta.
Beto
Sabes exactamente qué notas se están tocando. Pero la experiencia es completamente abstracta.
Los tokens de códec de audio, en cambio, son como escuchar a la orquesta en vivo.
Alicia
Sí.
Beto
Capturan el timbre específico del violonchelo, la acústica de la sala de conciertos y hasta el chirrido de la silla del violinista.
Alicia
Exacto. Y yendo más allá, esos tokens de códec de audio se derivan de modelos de compresión neuronal como EnCodec o SoundStream.
Beto
Vale.
Alicia
Capturan todos esos finos detalles acústicos, tu acento específico, el eco de tu cocina, el zumbido de tu refrigerador.
Beto
Todo.
Alicia
Pero esto crea un enorme cuello de botella computacional.
Beto
Porque son muchos datos.
Alicia
Sí. El audio se muestrea a 16.000 veces por segundo, o más. Incluso después de la compresión inicial, estás manejando cientos de tokens por un solo segundo de habla.
Beto
Oh, vaya. Por segundo.
Alicia
Sí. Si alimentas todos esos datos acústicos crudos y de alta resolución directamente en un modelo de lenguaje estándar, la longitud de la secuencia simplemente se dispara. El modelo se abruma por el volumen de tokens.
Beto
Claro. Porque estos modelos de secuencia fueron diseñados originalmente para texto, donde una oración entera podría ser solo 10 tokens. Pero una sola oración de audio podría ser miles de tokens de códec.
Alicia
Lo que es precisamente por lo que ese paso intermedio en la canalización, el adaptador de modalidad, fue inventado.
Beto
Ah. Bien.
Alicia
Los investigadores están usando herramientas como la compresión CTC o (Connectionist Temporal Classification).
Beto
Entonces, ¿cómo comprime CTC los datos sin perder el significado?
Alicia
Bueno, mira los marcos de audio secuencialmente. Y cuando ve marcos idénticos adyacentes, simplemente los fusiona.
Beto
Ah, vale.
Alicia
Como si alargas una palabra y dices “aquí”, la forma de onda continua genera docenas de tokens redundantes para el sonido de la “a” y la “i”.
Beto
CTC simplemente colapsa eso.
Alicia
Exactamente. Colapsa esas vocales alargadas y los silencios en representaciones únicas. Otra herramienta es el Q-Former, que actúa como un cuello de botella de atención cruzada.
Beto
¿Qué hace eso?
Alicia
Saca solo los embeddings acústicos más relevantes y los pasa hacia adelante. El adaptador de modalidad esencialmente actúa como un embudo altamente inteligente.
Beto
Así que alinea el ritmo de los tokens de audio para que el “cerebro” de la IA pueda digerirlos sin simplemente colapsar.
Alicia
Precisamente.
Beto
Porque resolver ese cuello de botella de tokens es tan difícil, el campo no ha llegado realmente a un consenso sobre una sola arquitectura unificada todavía.
Alicia
No, para nada.
Beto
La encuesta detalla cómo los desarrolladores se han dividido en tres sabores distintos de SLMs, dependiendo enteramente de los compromisos que estén dispuestos a hacer entre matiz acústico y lógica factual.
Alicia
Sí. El panorama está definitivamente fragmentado, pero la categorización ayuda a clarificar los objetivos de distintos laboratorios de investigación.
Beto
Correcto. Hablemos del sabor uno.
Alicia
El sabor uno es lo que el artículo cataloga como "SLMs de habla pura". Estos son modelos entrenados exclusivamente en conjuntos de datos masivos de audio no etiquetado.
Beto
Es decir, no ven texto.
Alicia
Nunca ven texto durante el entrenamiento. Están aprendiendo la distribución fundamental de los patrones del habla humana totalmente desde cero.
Beto
Un pionero aquí fue GSLM, ¿verdad?
Alicia
Sí. Exacto.
Beto
Pero la compensación con el habla pura es que, si bien suena increíblemente natural, carece de anclaje semántico. Si dejas correr un modelo de habla pura, a menudo balbucea.
Alicia
Exacto. Domina las reglas acústicas, pero lucha con la coherencia lógica. Genera audio que posee la cadencia e intonación perfectas del inglés, pero las palabras reales son sin sentido.
Beto
Es algo inquietante.
Alicia
Lo es. AudioLM intentó tender un puente usando una jerarquía por coarsing.
Beto
¿Cómo funciona eso?
Alicia
Genera primero los tokens fonéticos estructurales para asegurar que la oración tenga sentido lógico. Y luego superpone los tokens acústicos de alta resolución del códec para hacer que suene como una voz humana específica.
Beto
Oh, eso es ingenioso.
Alicia
Es un enfoque muy elegante, puro audio-entrada audio-salida. Pero para resolver verdaderamente el problema de la lógica, vemos el sabor dos.
Beto
Que es speech+text LMs, modelos como Moshi o Spirit LM.
Alicia
Sí.
Beto
Estos me fascinan porque modelan conjuntamente ambas modalidades simultáneamente. Intercalan tokens de texto y de audio juntos en la misma secuencia.
Alicia
Sí. Y al intercalarlos, el modelo obtiene lo mejor de ambos mundos.
Beto
¿Cómo es eso?
Alicia
Puede apoyarse en el enorme conocimiento factual y las capacidades de razonamiento embebidas en los tokens de texto, lo que ancla la generación de audio a la lógica textual.
Beto
Así evita los balbuceos.
Alicia
Exacto. Eso es lo veraz del audio mientras que el audio proporciona el matiz emocional.
Beto
Eso tiene mucho sentido.
Luego está el sabor tres, que parece ser el enfoque más común ahora mismo. "SLMs conscientes del habla".
Alicia
Sí. Muy populares.
Beto
¿Por qué tantos desarrolladores eligen esta ruta específica, tomar un potente LLM de texto ya entrenado como LLAMA y simplemente enchufarle un codificador de voz al frente?
Alicia
Honestamente, se reduce a la economía computacional.
Beto
Dinero.
Alicia
Siempre. Cargar un modelo de 70 mil millones de parámetros desde cero en intercalado de audio y texto cuesta decenas de millones de dólares. Pero si ya tienes un modelo de texto de código abierto increíblemente inteligente, puedes aprovechar esos pesos existentes.
Beto
Ah, ya veo.
Alicia
Así que modelos como SALMONN o Qwen-Audio simplemente entrenan un adaptador para traducir los tokens de audio a un espacio de embeddings que el modelo de texto ya entiende. El modelo de texto de repente gana la capacidad de oír.
Beto
Lo que transforma completamente cómo interactuamos con ellos.
Alicia
Absolutamente.
Beto
No necesitas una aplicación específica para traducción y otra distinta para transcripción. Porque el cerebro subyacente sigue siendo un modelo de texto que sigue instrucciones, puedes darle a un SLM consciente del habla un archivo de audio y decir, describe el estado emocional del hablante, o traduce este audio francés agresivo a inglés calmado.
Alicia
Y lo hace. Se generaliza a tareas para las que no fue codificado explícitamente. Entiende la intención a través de modalidades.
Beto
Eso es increíble.
Alicia
Lo es. Nos lleva a una limitación severa de los modelos que hemos discutido hasta ahora.
Beto
Bien. ¿Cuál es el inconveniente?
Alicia
Operan mayormente en lo que los ingenieros llaman half-duplex.
Beto
Ah, el paradigma de walkie-talkie. Presionas un botón, das un prompt, esperas y la máquina da una respuesta, fin.
Alicia
Sí. Pero la conversación humana natural no es así. La comunicación humana es full-duplex.
Beto
Es caótica. Si estamos teniendo una conversación real, no espero a que termines un párrafo entero antes de reaccionar.
Alicia
Exacto. Estás reaccionando ahora mismo.
Beto
Correcto. Yo asiento. Digo “sí”, y ese backchanneling está constante. O si dices algo factualmente incorrecto, no espero mi turno para interrumpirte.
Alicia
Pero un bot en cascada tipo walkie-talkie no puede manejarlo. Su micrófono suele estar silenciado mientras su altavoz está reproduciendo para evitar que transcriba su propia voz.
Beto
Ah, así que simplemente sigue con su respuesta preescrita.
Alicia
Exacto. Resolver este desafío de full-duplex es la frontera actual para los SLMs de extremo a extremo. Tienen que aprender a procesar audio entrante mientras generan simultáneamente audio saliente sin confundirse con su propia salida.
Beto
Suena increíblemente difícil.
Alicia
Lo es. La encuesta apunta a dos soluciones arquitectónicas principales para esto. La primera es un enfoque de doble canal utilizado por modelos como Moshi o dGSLM.
Beto
Es decir, hay literalmente dos pistas paralelas de información corriendo al mismo tiempo.
Alicia
Correcto. Es una arquitectura especializada de torre dual. Un canal continuo está dedicado exclusivamente a la secuencia de escucha, tomando tu voz, procesando el ruido de la habitación. Y el canal paralelo es la secuencia de habla donde el modelo produce su propia voz. Está monitoreando constantemente su propia salida mientras escucha tu entrada.
Beto
Es como un pianista de jazz cuya mano izquierda marca la línea de bajo mientras la derecha improvisa la melodía, coordinando ambas corrientes en tiempo real según los otros músicos en la sala.
Alicia
Exactamente.
Beto
Bien, ¿cuál es el segundo enfoque?
Alicia
Multiplexado en el tiempo. En vez de ejecutar dos canales paralelos, el modelo comparte un único canal de secuencia, pero cambia rápidamente entre modos de escucha y habla a nivel de milisegundos.
Beto
Pero espera, ¿cómo decide la arquitectura cuándo tomar la palabra y cuándo cederla?
Alicia
Lo logra prediciendo dinámicamente tokens especiales de acción. Mientras el modelo te escucha, en cada paso computacional está calculando la probabilidad de predecir un token de “hablar”.
Beto
Oh, vaya.
Alicia
Sí. Entonces, si el contexto conversacional dicta una respuesta, predice “hablar”, toma la palabra y empieza a generar tokens de audio.
Beto
Bien, ¿pero qué pasa si lo interrumpo?
Alicia
Crucialmente, mientras está generando audio, continúa evaluando tu flujo de audio entrante. Si de repente irrumples e interrumpes, esos nuevos datos acústicos forzan la matriz de probabilidades del modelo a predecir un token de “escuchar”.
Beto
Así que simplemente se detiene.
Alicia
Al instante. Trunca instantáneamente su generación de audio y cede la palabra de vuelta a ti.
Beto
Literalmente está mapeando los contratos sociales no escritos de la interacción humana en matemáticas.
Alicia
Sí. Y les permite acercarse al tempo real de una conversación auténtica. Ya sabes, la latencia cognitiva de una respuesta humana, la brecha entre cuando dejas de hablar y cuando empiezo a hablar es naturalmente de unos 200 milisegundos.
Beto
Ya es rápido.
Alicia
A veces es incluso negativa, lo que significa que nos solapamos. Los viejos bots en cascada tienen latencias de tres a cinco segundos por ese pipeline de transcripción a text-to-speech.
Beto
Esas pausas dolorosas.
Alicia
Exacto. Al procesar la secuencia de audio directamente y usar estos tokens de acción conversacionales, los SLMs de extremo a extremo apuntan a alcanzar ese punto dulce humano de 200 milisegundos.
Beto
Están evitando por completo las pausas torpes y agonizantes que asociamos con la asistencia por voz.
Pero esa velocidad y fluidez similar a la humana introduce una nueva categoría de riesgos, ¿no?
Alicia
Definitivamente.
Beto
Porque a medida que estos modelos generan audio crudo en vez de texto, evaluarlos se vuelve increíblemente difícil. No puedes simplemente ejecutar un script estándar de precisión de texto para calificar su tarea.
Alicia
Correcto. Las métricas de evaluación tienen que ser reinventadas por completo. La encuesta cubre en realidad varios nuevos benchmarks desarrollados específicamente para la modalidad de audio. Uno es una métrica de verosimilitud llamada "sWUGGY".
Beto
sWUGGY.
Alicia
Sí, sWUGGY. Es una prueba ingeniosa para ver si un modelo de habla pura realmente ha aprendido las reglas fonéticas fundamentales de un idioma o si simplemente está memorizando sonidos.
Beto
Vaya. ¿Cómo hace eso?
Alicia
Es una prueba que usa una palabra real hablada y una palabra falsa que suena fonéticamente plausible, como la palabra “blick”.
Beto
Ok, “blick”.
Alicia
El modelo debe demostrar que reconoce que “blick” viola la distribución real del vocabulario del inglés, aunque las consonantes y vocales sigan las reglas fonéticas del inglés.
Beto
Ah, entonces está probando la intuición del modelo por el idioma.
Alicia
Exactamente. También hay enormes suites de pruebas automatizadas como el benchmark Dynamic SUPERB.
Beto
¿Qué hace ese?
Alicia
En lugar de solo comprobar la precisión de la traducción, Dynamic SUPERB usa un LLM superior como evaluador para puntuar al SLM en cientos de tareas de audio novedosas e inéditas. Prueba capacidades zero-shot para asegurar que el modelo realmente pueda generalizar instrucciones al audio crudo, en lugar de simplemente regurgitar sus datos de entrenamiento.
Beto
Bien, pero incluso con estos benchmarks avanzados, los modelos siguen fallando de maneras que los modelos de texto no.
Alicia
Lo cual nos lleva de nuevo al "perro alucinante" del principio de nuestro análisis.
Beto
Sí, el perro.
Alicia
Si le das a un SLM un clip de audio de completo silencio y le pides que subtitule ese audio, correctamente responde que "no hay sonido". Pero en el momento en que cambias el prompt a, "¿hay un perro ladrando en este audio?" el modelo insiste en que oye un perro.
Beto
Correcto.
Alicia
¿Por qué la instrucción anula los datos reales del audio?
Beto
Este es un fenómeno conocido como "alucinación de objetos", y proviene de la forma en que estos modelos se entrenan, específicamente los SLMs conscientes del texto.
Alicia
¿Cómo es eso?
Beto
Como el cerebro central es un modelo de texto afinado por instrucciones, ha sido fuertemente reforzado para ser servicial y prestar mucha atención a las palabras clave del usuario. El lado de texto de la arquitectura sobrepondera la frase “perro ladrando”.
Alicia
Ah, ya veo.
Beto
Sí, ese peso semántico anula los datos acústicos reales que vienen del codificador de audio. El cerebro de texto básicamente se convence a sí mismo de que oyó lo que le pediste que escuchara. Es un conflicto fascinante entre la modalidad de texto y la de audio dentro del mismo cerebro.
Alicia
Lo es.
Beto
Las cosas se vuelven mucho más oscuras que perros imaginarios, porque estos modelos utilizan tokens de códec de audio que capturan detalles acústicos de alta resolución. Son increíblemente hábiles para imitar voces humanas reales.
Alicia
Y las implicaciones de deepfake de eso son severas. Si una arquitectura puede mapear el timbre exacto, los patrones de respiración y la acústica de una persona específica con solo un clip de tres segundos, ...
Beto
... el potencial de explotación maliciosa es obvio.
Alicia
Completamente. La comunidad de investigación se ve obligada a construir contramedidas junto con los modelos mismos. El artículo describe la creación de conjuntos de datos como CodecFake.
Beto
Entonces, ¿cómo combate un dataset como CodecFake la clonación de voz?
Alicia
Entrenando modelos de detección para detectar las firmas acústicas microscópicas de los propios SLMs; incluso la mejor generación de audio deja tras de sí artefactos sutiles de alta frecuencia durante el proceso de tokenización del códec.
Beto
Como cosas que un humano no podría producir.
Alicia
Exacto. Patrones que las cuerdas vocales humanas simplemente no pueden generar. Al construir conjuntos de datos masivos de estos artefactos específicos, los desarrolladores pueden entrenar modelos de seguridad independientes para marcar audio sintético, incluso si suena perfectamente humano para nuestros oídos.
Beto
Bueno, es una carrera de armamentos continua.
Alicia
Realmente lo es.
Beto
Pero hay otro problema de seguridad que la encuesta aborda, que parece mucho más difícil de resolver mecánicamente: la toxicidad no verbal.
Alicia
Sí, esto expone un enorme punto ciego en los protocolos de seguridad actuales de IA. Ahora mismo, cuando las empresas evalúan un modelo de IA por comportamiento tóxico, casi exclusivamente están evaluando las palabras transcritas. Si la secuencia de tokens de texto no contiene blasfemias, discurso de odio o amenazas explícitas, la salida pasa el filtro de seguridad. Pero ya hemos establecido que el texto no captura la prosodia.
Beto
Lo que significa que una IA podría generar palabras perfectamente educadas y totalmente inocuas, pero entregarlas en un tono de voz violentamente agresivo.
Alicia
O con sarcasmo profundamente malicioso. O un susurro amenazante.
Si una IA dice una frase útil con una entrega acústica agresiva, la transcripción de texto se ve completamente inofensiva para el filtro de seguridad, pero la experiencia real del usuario es abusiva.
Beto
Eso da miedo.
Alicia
Lo es. Nuestros benchmarks de seguridad actuales están anclados en el mundo plano del texto, mientras que estos nuevos SLMs operan en el complejo y emocional mundo del audio. Simplemente aún no tenemos un marco matemático estandarizado y fiable para medir y restringir un tono de voz tóxico.
Beto
Es una omisión asombrosa al pensar en cómo se desplegarán públicamente.
Alicia
Es un gran desafío.
Beto
Juntando todo esto: estamos presenciando el fin del cuello de botella del texto. Estamos moviéndonos de sistemas en cascada que retranscriben ciegamente en voz alta a modelos universales de lenguaje hablado que procesan de forma nativa la forma de onda humana. Ya sean modelos de habla pura, mapeando acústica, o modelos speech-to-text que enchufan codificadores a LLAMA, están utilizando tokens fonéticos y tokens de códec para capturar no solo lo que decimos, sino cómo lo decimos.
Alicia
Y empleando canales duales o multiplexado temporal, están comenzando a manejar conversaciones full-duplex.
Beto
Correcto.
Alicia
Están modelando el back-channeling, las interrupciones y ese tempo de 200 milisegundos de la interacción humana genuina.
Beto
Empezamos hablando de cómo el texto es limpio y preciso, mientras que el habla es turbia e infinitamente compleja. Y estos SLMs finalmente están aprendiendo a navegar ese lodo.
Alicia
Realmente lo están.
Beto
Pero viendo cuán granular llega esto, hasta predecir tokens de acción milisegundo a milisegundo, me deja con un pensamiento final que rumiar.
Alicia
¿Cuál es?
Beto
Si una IA ahora puede mapear perfectamente los tokens fonéticos y acústicos de la conversación humana, cada respiración, cada micropausa, cada momento de solapamiento, ¿en qué momento el silencio que elige generar se vuelve tan significativo como las palabras que pronuncia?
Alicia
Vaya. El sistema aprende a ceder la palabra dinámicamente o pausar por efecto dramático basado en el contexto acumulado. Ya no está solo procesando datos. Está interpretando activamente las señales sociales de empatía.
Beto
Exacto. Así que aquí hay un desafío para ti, oyente. La próxima vez que estés profundamente comprometido en una conversación natural cara a cara, no escuches solo el vocabulario. Intenta escuchar la corriente de datos.
Alicia
Es un gran ejercicio.
Beto
Observa los solapamientos, los sutiles, el milisegundo exacto en que deciden tomar la palabra después de tu pausa. Intenta detectar los tokens de códec reales que ocurren en el aire a tu alrededor. Porque muy pronto, la inteligencia artificial con la que hables va a estar haciendo exactamente lo mismo.



{kind=link}