
El informe detalla el panorama global de la investigación y el desarrollo en inteligencia artificial hasta 2025, destacando una transición hacia el dominio de la industria y una menor transparencia. Si bien la capacidad de procesamiento se ha expandido significativamente, la cadena de suministro de hardware sigue siendo vulnerable debido a su fuerte dependencia de una única fundición taiwanesa. China lidera en volumen de investigación y concesión de patentes, mientras que Estados Unidos sobresale en la producción de modelos de alto impacto y atrae la mayor participación en el código abierto. Los datos revelan desafíos ambientales críticos, señalando que las demandas de energía y agua de los modelos de vanguardia ahora rivalizan con el consumo de naciones enteras. Además, a pesar del rápido escalamiento tecnológico y los cambios en la distribución geográfica del talento, las brechas de género de larga data en la fuerza laboral de IA permanecen inalteradas. En definitiva, el texto ilustra un ecosistema definido por una intensa competencia empresarial, una inversión masiva en infraestructura y las crecientes preocupaciones sobre la sostenibilidad de los datos.
Enlace al reporte científico, para aquellos interesados en profundizar en el tema: AI Index Report 2026 - Chapter 1 - Research and Development. Publicado el 13 de Abril de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Así que para finales de 2025, más de la mitad del contenido recién publicado en Internet fue en realidad escrito por máquinas.
Beto
Es una estadística asombrosa si lo piensas bien.
Alicia
Sí, es una locura. Y paradójicamente, por esa misma razón, la industria global de la inteligencia artificial de repente se está muriendo de hambre.
Beto
Claro. Literalmente se están quedando sin “comida”, por así decirlo.
Alicia
Exacto. Quiero decir, todos hemos sido condicionados a pensar en la tecnología como algo sin peso. Sacas el teléfono, escribes y una respuesta parece materializarse como por arte de magia.
Beto
Sí, se siente completamente etéreo.
Alicia
Y por eso la industria lo bautizó tan brillantemente como “la nube”. Es una metáfora que hace invisible para ti toda la maquinaria física masiva y pesada.
Beto
Pero si realmente levantas esa interfaz pulida, revelas algo completamente distinto. No encuentras ninguna nube. Encuentras una cadena de suministro industrial, voraz en recursos y fuertemente protegida.
Alicia
Bienvenidos a nuestro análisis en profundidad. Hoy vamos a profundizar en el estado de la investigación y desarrollo en IA en 2026. Y vamos a usar el capítulo uno del recién publicado informe del Índice de IA de Stanford como plano.
Beto
Es un informe enorme. Y hay muchísimo que abordar.
Alicia
De verdad que sí. Y nuestro objetivo hoy es mirar más allá del implacable ciclo de marketing de todos esos chatbots llamativos. Vamos directamente al taller de producción, básicamente.
Beto
Exacto. Queremos descubrir los cuellos de botella fuertemente guardados de los gigantes tecnológicos, las fuerzas físicas brutas que están rompiendo nuestras redes eléctricas y el mapa geopolítico que cambia rápidamente sobre quién controla realmente el hardware y el talento.
Alicia
Porque para quien nos escucha, entender estas limitaciones físicas ocultas es en última instancia el marco definitivo para predecir dónde chocará esta industria a continuación.
Beto
Y para mapear eso, tenemos que empezar por la fuente real de estos modelos.
Alicia
Que ha cambiado por completo.
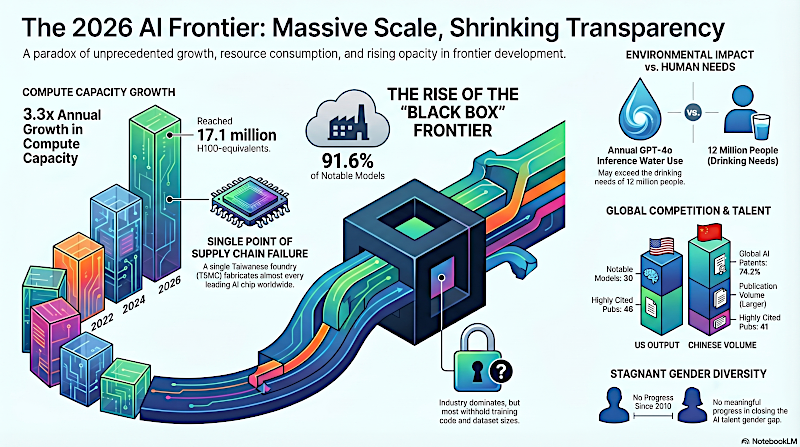
La frontera de la IA en 2026: escala masiva, cada vez más reducida.
Beto
Claro. Fundamentalmente, el cambio más masivo documentado en el informe de 2026 es el cierre radical de la frontera del código abierto. Si miras los modelos notables publicados en 2025, más del 90 % se originaron estrictamente en el sector industrial.
Alicia
Hablamos de gigantes como OpenAI, Google, Alibaba.
Beto
Exacto. Y la academia, que históricamente construyó los cimientos teóricos de todo este campo, produjo exactamente un modelo notable, solo uno.
Alicia
Vaya. Bien, desgranemos esto porque eso señala una fractura estructural enorme en cómo se hace la ciencia.
Beto
De verdad que sí.
Alicia
Con la academia completamente excluida de estas guerras por el cómputo, parece que las universidades van a tener que abandonar por completo la construcción de modelos de vanguardia, ¿no? Tendrán que pivotar estrictamente hacia seguridad de la IA, auditorías o quizás arquitecturas teóricas.
Beto
Porque matemáticamente ya no pueden competir con las granjas de servidores corporativas.
Alicia
Correcto. Están totalmente fuera de juego. Es como si hubiéramos pasado de una comida comunitaria donde todos compartían sus recetas a un mundo de fórmulas corporativas altamente guardadas, como la receta de Coca‑Cola.
Beto
Es una analogía perfecta. Y lo fascinante aquí es por qué este cambio importa tanto. Esta opacidad creciente limita severamente la capacidad de investigadores independientes para reproducir resultados.
Alicia
Que es la base del método científico.
Beto
Exacto. Si no puedes auditar cómo se desarrollan estos sistemas, no puedes validar de forma independiente afirmaciones de seguridad o benchmarks. El poder se desplaza por completo a las corporaciones. La primera víctima inmediata de esa centralización es la transparencia.
Alicia
Pero, ¿qué dicen realmente los datos sobre esa opacidad?
Beto
Bueno, de los 95 modelos notables lanzados en 2025, 80 se publicaron sin su código de entrenamiento. El procedimiento operativo estándar ahora es solo acceso estricto por API. La era de la divulgación abierta está efectivamente terminada.
Alicia
Puedes hacer peticiones al modelo como usuario, pero los pesos internos, la arquitectura, la tubería de entrenamiento, todo eso está completamente oculto. Literalmente estás interactuando con una caja negra.
Beto
Correcto. Esto deja la carga de la confianza enteramente sobre los departamentos de relaciones públicas de unas cinco o seis mega-corporaciones.
Alicia
Y la ocultación va mucho más allá del código de entrenamiento. Los laboratorios fronterizos han dejado de divulgar recuentos de parámetros, tamaños de conjuntos de datos, duraciones de entrenamiento.
Beto
Sí, estamos completamente a ciegas respecto a las leyes de escalado que están experimentando. No tenemos idea de cuánto hardware están arrojando al problema solo para exprimir incrementos de rendimiento.
Alicia
Tratan esos datos como secretos comerciales altamente clasificados.
Beto
Lo hacen. Incluso con las puertas de los laboratorios firmemente cerradas, los datos del ecosistema más amplio nos dicen exactamente con qué están lidiando dentro.
Alicia
¿Los ingredientes?
Beto
Sí, están chocando contra una pared masiva respecto a su insumo primario: datos humanos de alta calidad. Esta es la crisis del pico de datos.
Alicia
Correcto. Porque las proyecciones actuales del informe de Stanford indican que la industria podría agotar por completo la reserva global de texto humano y datos web de alta calidad en algún momento entre 2026 y 2032.
Beto
Que está a la vuelta de la esquina.
Alicia
Básicamente mañana, en años tecnológicos. Estamos hablando de alcanzar los límites absolutos de la producción humana. Y esta colisión ocurre justo cuando Internet se está inundando de basura sintética. Como mencioné al principio, más del 50 % del contenido nuevo en línea ahora es generado por IA.
Beto
Y la hipótesis inicial de la industria era que podrían simplemente usar esos datos sintéticos para cerrar la brecha.
Alicia
Como hacer que modelos más antiguos generen trillones de tokens de texto para entrenar la siguiente generación de modelos en un bucle continuo.
Beto
Exacto. Pero los datos empíricos muestran que esa estrategia fracasa completamente a nivel fundamental. Reentrenar con puro dato sintético no iguala al dato real para modelos grandes.
Alicia
Bien, aquí es donde se pone realmente interesante, porque tengo que objetar un poco. Si más del 50 % de Internet es ahora generado por IA, ¿no acabarán estos modelos comiéndose su propia cola, como una fotocopia de una fotocopia de una fotocopia?
Beto
Sí, absolutamente. Es un fenómeno matemático documentado llamado "colapso del modelo".
Alicia
Oh, vaya, colapso del modelo.
Beto
Sí, y no es solo que la fotocopia se degrade. Es más bien un aplanamiento estadístico. Mira, una IA entrenada con datos humanos aprende los bordes raros, creativos e impredecibles del pensamiento humano.
Alicia
Correcto, la matiz.
Beto
Exacto. Captura la sutileza de nuestro lenguaje.
Alicia
Sí.
Beto
Pero una IA entrenada con datos generados por IA solo aprende las respuestas más probables y promedio. Literalmente elimina los bordes. En generaciones sucesivas, el modelo básicamente muere de aburrimiento.
Alicia
Muere de aburrimiento, me encanta eso.
Beto
Sí, acaba produciendo nada más que un estático hiper‑genérico. Esto confirma exactamente el riesgo del que hablas, y por eso el entrenamiento híbrido y el depurado meticuloso de datos son tan vitales ahora.
Alicia
Lo que significa que forzar conjuntos de datos masivos es de golpe un callejón sin salida si esos conjuntos están contaminados.
Beto
Preciso. Eso explica el violento giro de la industria que estamos viendo: del escalado de datos indiscriminado, que consistía en raspar toda la web, hacia métodos centrados en datos altamente curados. La calidad oficialmente supera a la cantidad.
Alicia
Porque los datos malos ahora perjudican activamente al modelo.
Beto
Correcto. Así que el foco está totalmente en el filtrado algorítmico. En lugar de alimentar a un modelo con miles de millones de publicaciones de foros al azar, los investigadores están aumentando matemáticamente la relación señal‑ruido antes de que el modelo vea siquiera el texto.
Alicia
Ejecutan tuberías agresivas de desduplicación, eliminan frases redundantes, tal vez aíslan contenidos de alta densidad como demostraciones matemáticas paso a paso.
Beto
Exacto. Eliminando todo el código repetitivo. Un ejemplo perfecto de esto en el informe es OLMo 3.1, de unos 32.000 millones de parámetros.
Alicia
Bien, contextualicemos ese modelo porque su rendimiento trastoca por completo la narrativa de que “más grande siempre es mejor”.
Beto
De verdad que sí.
Alicia
OLMO tiene aproximadamente 32.000 millones de parámetros. Grok‑4, por otro lado, está en un colosal orden de 3 billones de parámetros. OLMO es casi 90 veces más pequeño y, sin embargo, iguala a Grok‑4 en benchmarks de matemáticas complejas.
Beto
Y el mecanismo detrás de esa paridad es completamente la curación de datos. Alimentar una arquitectura altamente eficiente con un conjunto de datos impecablemente limpio e hiperdenso produce las mismas capacidades de razonamiento que tirar miles de GPUs a 3 billones de parámetros de datos ruidosos.
Alicia
Demuestra que la densidad de la información importa mucho más que el mero volumen de parámetros.
Beto
Muy bien. Y esta desesperación por datos humanos incontaminados e hiperdensos está impulsando una enorme economía en la sombra de acuerdos de licencias propietarios.
Alicia
Oh, absolutamente. Las empresas tecnológicas saben que la web abierta se está secando, así que están cerrando el acceso exclusivo a información de pago. Ves a Amazon cerrando acuerdos con el New York Times.
Beto
Laboratorios de IA licencian discretamente registros médicos propietarios de empresas de ciencias de la vida como Bristol‑Myers Squibb.
Alicia
Están comprando la señal humana pura restante antes de que sus competidores puedan acceder a ella.
Beto
Pero este giro hacia datos hipercurados no se trata solo de hacer el modelo más inteligente. También es un intento desesperado por reducir el cómputo físico necesario para operarlos.
Alicia
Porque ahora mismo, el procesamiento por fuerza bruta de estos modelos masivos está literalmente rompiendo la infraestructura física de la red eléctrica.
Beto
Correcto. Puedes curar y podar tus datos cuanto quieras, pero aun así necesitas máquinas físicas masivas para procesarlos.
Alicia
¿Qué significa todo esto?
Nos han condicionado a pensar en la IA como esta nube mágica sin peso. Pero en realidad es una fábrica industrial masiva, sedienta y hambrienta de energía.
Beto
Exacto. Esto nos saca de la capa del software y nos lleva al taller. La huella física es impactante. La capacidad global de cómputo para IA se ha disparado, creciendo 3,3 veces por año desde 2022.
Alicia
Vaya.
Beto
Recientemente alcanzó los 17,1 millones de equivalentes H100. Y Nvidia controla más del 60 % de ese cómputo.
Alicia
Y la fragilidad geopolítica de ese número es aterradora porque casi todos los chips líderes de IA del planeta son fabricados por una compañía, TSMC, en Taiwán.
Beto
Toda la base del auge global de la IA pasa por una sola isla. Los puntos de estrangulamiento en la cadena de suministro son totalmente sin precedentes.
Alicia
Es una locura de pensar.
Beto
Pero una vez que esos chips salen de la isla y se instalan en racks dentro de servidores, la termodinámica de operarlos toma el control. Estados Unidos aloja la gran mayoría de este hardware, operando 5.427 centros de datos.
Alicia
Y el consumo energético es difícil de asimilar. La capacidad energética de centros de datos globales para IA acaba de alcanzar los 29,6 gigavatios.
Beto
Sitúa ese número: un gigavatio es una abstracción para la mayoría.
Alicia
Sí.
Beto
29,6 gigavatios equivalen a la demanda pico de energía del estado de Nueva York entero.
Alicia
Todo el estado.
Beto
Cada tren del metro, cada hospital, cada unidad de aire acondicionado funcionando simultáneamente. Esa es la potencia mínima necesaria solo para mantener estos modelos en funcionamiento.
Alicia
Es una locura. Y obviamente la huella de carbono escala directamente con ese consumo. Entrenar a Grok‑4 produjo un estimado de 72.816 toneladas de CO2.
Beto
Para ponerlo en términos humanos: una persona promedio conduciendo un coche de combustión genera alrededor de 63 toneladas de CO2 a lo largo de toda su vida.
Alicia
A lo largo de toda la vida.
Beto
Exacto.
Alicia
Pero aquí está la distinción crítica: esas 72.000 toneladas de CO2 son solo el coste único inicial para entrenar el modelo.
Beto
Correcto. Si conectamos esto con el panorama mayor, el verdadero impuesto, el drenaje continuo y compuesto en la red eléctrica viene de la inferencia. Eso es el uso real de los modelos.
Alicia
Porque cada vez que un usuario envía un prompt, esas GPUs tienen que arrancar y ejecutar miles de millones de multiplicaciones de matrices continuas solo para calcular la respuesta.
Beto
Exacto. Y las cuentas sobre inferencia son alarmantes. Una sesión diaria de solo ocho consultas de longitud media requiere la misma cantidad de energía que cargar dos smartphones del 0 al 100 %.
Alicia
Ocho preguntas. La mayoría de los usuarios mantienen conversaciones de horas, con múltiples intercambios, iterando sobre código o escribiendo ensayos.
Beto
Así que cuando escalas eso a cientos de millones de usuarios activos diarios, la energía requerida para la inferencia eclipsa por completo el coste inicial de entrenamiento.
Alicia
Y ese disparo continuo genera calor concentrado masivo, lo que nos lleva al uso de agua. No puedes enfriar racks de GPUs densamente empaquetadas con aire acondicionado estándar.
Beto
No, no puedes. El agua es el sumidero de calor más eficiente disponible. Estos centros de datos están evaporando millones de galones de agua solo para evitar que el silicio se funda.
Alicia
El informe de Stanford estima que el consumo anual de agua solo para ejecutar las inferencias de GPT‑4o podría superar las necesidades de agua potable de 12 millones de personas.
Beto
12 millones de personas. Así que cada vez que le pides a un chat que te resuma un PDF, estás tirando de un embalse literal.
Alicia
Cambia fundamentalmente cómo ves la utilidad de estas herramientas cuando te das cuenta del coste ambiental de una sola consulta.
Beto
De verdad que sí.
Alicia
Y si la infraestructura física, los centros de datos y los recursos hídricos están muy concentrados en EE. UU. y el hardware depende de Taiwán, tenemos que mirar también la tubería humana global que diseña realmente las arquitecturas. El tablero geopolítico del talento en IA está cambiando dramáticamente.
Beto
Correcto. Si evaluamos el volumen bruto de investigación, China está ejecutando una estrategia masiva a escala. Representan el 17,8 % de todas las publicaciones globales sobre IA.
Alicia
Vaya.
Beto
Y su dominio en concesiones de patentes es abrumador. Poseen más del 74 % del total mundial de patentes en IA.
Alicia
Pero planteo una pregunta directa aquí: si EE. UU. está viendo una caída del 89 % en la atracción de talento internacional y China domina la producción en bruto de investigación y patentes, ¿estamos ante un cambio inminente de guardia en el liderazgo global de la IA?
Beto
Esto plantea una cuestión importante y requiere sintetizar un poco los datos porque el volumen bruto en presentación de patentes a menudo oscurece el liderazgo tecnológico real. Una patente no significa necesariamente que una tecnología sea viable o influyente. El informe sigue específicamente las citas hacia delante, que miden con qué frecuencia inventores posteriores referencian una patente para construir su propio trabajo. EE. UU. recibe más del 50 % de las citas hacia delante globales.
Alicia
Es decir, esas patentes estadounidenses son altamente influyentes.
Beto
Exacto. Esa métrica de citas hacia delante es el indicador crucial de influencia a largo plazo. China claramente está persiguiendo una estrategia asimétrica de inundar la zona con volumen puro, pero EE. UU. sigue siendo el núcleo central de la comercialización de alto impacto.
Alicia
Y vemos esto reflejado directamente en el despliegue de modelos. EE. UU. produjo 50 de los modelos notables en 2025 frente a los 30 de China.
Beto
También lo vemos en el ecosistema de código abierto. De 5,6 millones de proyectos globales en GitHub, los proyectos con base en EE. UU. acaparan 30 millones de “stars” acumuladas, dominando la participación comunitaria.
Alicia
Pero la tubería humana que sostiene esa supremacía estadounidense está parpadeando en rojo intenso. Mencionaste que la movilidad del talento está cambiando drásticamente.
Beto
Correcto. Históricamente, la ventaja de EE. UU. era su capacidad para actuar como pozo gravitatorio, atrayendo al talento de ingeniería de primer nivel de todo el mundo. Pero los datos muestran que el número de investigadores en IA que migran a Estados Unidos se ha desplomado un 89 % desde 2017.
Alicia
Y cayó un 80 % solo en el último año, ¿verdad?
Beto
Sí.
Alicia
Quiero decir, una caída del 89 % en la adquisición de talento es un fallo sistémico. Con el acceso al cómputo centralizado en unas pocas corporaciones monopolísticas y las vías de inmigración más estrictas, los investigadores ya no ven a EE. UU. como el destino por defecto.
Beto
El talento se está distribuyendo a hubs alternativos. Cuando miras la densidad de talento en IA por habitante, naciones pequeñas están rindiendo muy por encima de su peso. Suiza lidera actualmente el mundo con más de 110 investigadores en IA por cada 100.000 personas.
Alicia
Y Singapur va por detrás muy de cerca.
Beto
Exacto. Estamos pasando, de un mapa unipolar del talento, a una red altamente fragmentada y distribuida, de potencias regionales.
Alicia
Pero independientemente de si el talento está en Zúrich, Singapur o Silicon Valley, hay un punto ciego sistémico y evidente que está lastrando a toda la fuerza laboral global. Y es un déficit que limita activamente la capacidad de los modelos que están construyendo.
Beto
Es un fallo masivo. La brecha de género en la ingeniería de IA sigue sólidamente enquistada, y las estadísticas globales son bastante sombrías. En hubs tecnológicos importantes como Brasil, Corea del Sur y Japón, más del 80 % del talento identificado en IA es masculino.
Alicia
Y el hallazgo más sobrecogedor del informe es que, en todo el mundo, no ha habido progreso significativo hacia la paridad de género en la fuerza laboral de IA desde 2010.
Beto
No en ningún país. 15 años de crecimiento explosivo, billones de dólares en capitalización de mercado y la demografía de quienes diseñan estas tecnologías no se ha movido ni un centímetro.
Alicia
Y esto no es solo una crítica de equidad, ¿verdad? Quiero decir, lo es, pero es también una responsabilidad de ingeniería fundamental. El objetivo último de estos laboratorios de vanguardia es construir sistemas de inteligencia artificial general diseñados para entender, predecir e interactuar sin fisuras con la totalidad del comportamiento humano.
Beto
Exacto. No puedes modelar matemáticamente la sutileza de la experiencia humana cuando las personas que diseñan las funciones de recompensa, curan los conjuntos de datos de comportamiento y establecen la alineación de seguridad representan solo una fracción de la población.
Alicia
Correcto. Al excluir perspectivas diversas, la industria está incorporando de forma directa un enorme punto ciego comportamental en los pesos fundacionales de la inteligencia que intenta crear. Limita la capacidad del modelo para interpretar realmente contextos humanos complejos.
Beto
Está privando al ecosistema global de las perspectivas que más necesita ahora.
Alicia
Entonces, para juntar todas estas piezas móviles para quien nos escucha: empezamos intentando mirar en la “nube” de la IA y lo que encontramos fue una fábrica increíblemente pesada en recursos.
Beto
Y además fuertemente protegida.
Alicia
Sí. Estamos viendo una industria que choca contra los límites de los datos humanos, pivotando hacia la curación algorítmica para evitar el colapso del modelo. Estamos rastreando una infraestructura física que consume la energía de estados enteros y evapora el agua potable de millones.
Beto
Todo mientras el mapa global del talento se reconfigura drásticamente y surgen hubs regionales que desafían monopolios históricos.
Alicia
Entender esta realidad física, geopolítica y humana evita que te lleve la marea del marketing. Te permite ver las restricciones que dictarán los próximos cinco años de desarrollo.
Beto
Porque el paradigma actual de escalado es esencialmente un callejón sin salida termodinámico, lo que te deja con una reflexión final realmente provocadora para masticar.
Alicia
Oh, me gusta a dónde va esto.
Beto
Si la industria está golpeando rápidamente un muro físico absoluto con escasez de datos, límites de energía y consumo de agua, entonces el próximo verdadero salto en inteligencia artificial probablemente no se parecerá a Grok-4.
Alicia
“Más grande y más pesado”. El método de fuerza bruta es matemáticamente insostenible.
Beto
Exacto. Así que el próximo gran avance puede que no sea un coloso corporativo de tres billones de parámetros que requiera una central nuclear para funcionar. Es mucho más probable que sea una arquitectura radicalmente nueva, inspirada biológicamente.
Alicia
Porque el cerebro humano logra verdadero razonamiento, adaptabilidad fluida y comprensión compleja con aproximadamente 20 vatios de potencia.
Beto
20 vatios. Eso es una fracción de lo que requiere un solo chip H100 solo para calcular probabilidades estadísticas.
Alicia
Vaya. Así que alejándose de la fábrica industrial por fuerza bruta y volviendo a la brutal eficiencia de la biología, el futuro pertenece a quien descubra cómo ejecutar razonamiento complejo con radicalmente menos cómputo.
Beto
Ese es el verdadero frente. Ten en mente ese umbral biológico de 20 vatios la próxima vez que hagas una petición a una API y observes cómo la enorme e invisible máquina industrial se pone en marcha para ofrecerte la respuesta.



{kind=link}