
Los documentos proporcionados presentan la serie DeepSeek-V4, un conjunto de modelos de lenguaje avanzados de mezcla de expertos diseñados para el procesamiento de contextos de millones de tokens con alta eficiencia. La serie cuenta con dos versiones principales, DeepSeek-V4-Pro y DeepSeek-V4-Flash, que utilizan una novedosa arquitectura de atención híbrida para reducir drásticamente la sobrecarga computacional y el uso de memoria durante tareas con contextos extensos. Entre las innovaciones técnicas clave se incluyen el optimizador Muon para un entrenamiento estable, las hiperconexiones con restricciones de variedad para mejorar la propagación de la señal y el entrenamiento con conciencia de la cuantización para una mayor velocidad de inferencia. Las pruebas de rendimiento indican que estos modelos destacan en razonamiento complejo, codificación y conocimiento del mundo, a menudo rivalizando o superando a los sistemas abiertos y propietarios contemporáneos. Además, las fuentes detallan un proceso sofisticado, posterior al entrenamiento, que emplea expertos específicos del dominio y destilación basada en políticas para refinar las capacidades de razonamiento y de agencia. En general, el texto presenta a DeepSeek-V4 como un avance significativo en la escalabilidad del razonamiento en tiempo de prueba y en la gestión de secuencias ultralargas.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "DeepSeek V4". Publicado el 24 de Abril de 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Imagina que te encargan construir un puente. Y normalmente, cuanto más largo es el puente, más acero necesitas.
Alicia
Bien. Es básicamente una relación lineal.
Beto
Exacto. A un metro de carretera, añades una tonelada de acero.
Pero imagina que vivieras en este universo extraño donde por cada metro nuevo de puente que construyes tienes que elevar al cuadrado la cantidad total de acero.
Alicia
Oh, wow.
Beto
Así que 10 metros requieren 100 toneladas, 1.000 metros requieren un millón de toneladas. Y muy rápido necesitas más acero del que existe en todo el planeta.
Alicia
Y toda la estructura simplemente colapsa bajo su propio peso matemático. Se vuelve físicamente imposible de construir.
Beto
Claro. Y ese puente imposible es la forma perfecta de describir lo que se siente al intentar procesar contextos ultralargos en inteligencia artificial.
Alicia
Sí. A medida que el contexto se alarga, las matemáticas se vuelven exponencialmente más difíciles.
Beto
Pero, ¿y si un equipo de investigadores averiguó cómo esencialmente reescribir las leyes de la física para ese puente?
Bienvenidos a la inmersión de hoy. Tenemos una misión muy específica: desentrañar un artículo de investigación altamente técnico, honestamente increíblemente denso, de DeepSeek sobre su nueva arquitectura V4.
DeepSeek V4: Rompe la barrera de eficiencia con Inteligencia de millones de tokens
Alicia
El objetivo aquí es entender realmente cómo esta nueva arquitectura hace añicos una barrera de cómputo que antes era enorme. Hablábamos de procesar un contexto ultralargo de un millón de tokens, que, si te lo preguntas, equivale más o menos a unas pocas miles de páginas de un libro.
Beto
Es inmenso.
Alicia
Históricamente, mantener tanta información y memoria activa a la vez era prohibitivamente caro, incluso para las gigantes tecnológicas.
Beto
Y lo más loco es que DeepSeek lo está haciendo de código abierto.
Establezcamos las especificaciones base para que podamos captar la escala de la máquina que estamos viendo. La serie V4 introduce dos modelos distintos.
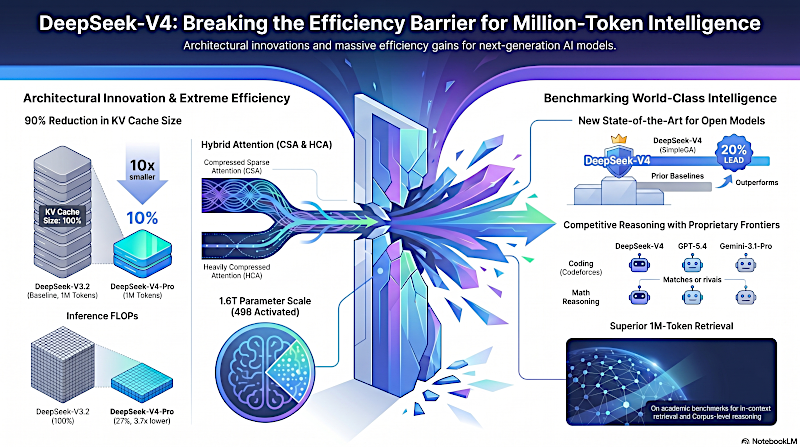
Primero, está DeepSeek V4 Pro. Este modelo tiene unos enormes 1,6 billones (trillones en inglés) de parámetros totales. Pero el artículo señala que solo activa 49.000 millones de parámetros por token.
Alicia
Esta es una distinción enorme.
Beto
Quiero detenerme ahí porque, si alguien no está metido en hardware de IA, eso suena a una contradicción total. ¿Cómo tienes más de un billón de parámetros pero solo usas 49.000 millones?
Alicia
Pues esa brecha se debe a lo que se llama una arquitectura "mixture of experts", o MoE (mezcla de expertos). Piensa en los 1,6 billones de parámetros totales como una gigantesca corporación global con miles de departamentos altamente especializados. Esos parámetros totales representan la vasta capacidad de conocimiento del modelo. Pero cuando le pides que genere una sola palabra, no consulta toda la empresa.
Beto
Eso tomaría una eternidad.
Alicia
Exacto. Usa un mecanismo de enrutamiento para activar solo los expertos específicos, los departamentos necesarios para ese concepto exacto. Esos son los 49.000 millones de parámetros activados. Eso dicta tu coste computacional real.
Beto
Tiene mucho sentido. Es básicamente la diferencia entre el tamaño de una biblioteca y el número de libros que realmente sacas del estante para tu proyecto.
Alicia
Gran forma de decirlo.
Beto
Y luego está el hermano menor, DeepSeek V4 Flash. Ese tiene 284.000 millones de parámetros totales con apenas 13.000 millones activados por token.
Alicia
Y el gancho real aquí es que V4 no es solo una optimización menor. Este modelo abierto compite directamente con los modelos cerrados de gama más alta. Iguala a gigantes propietarios como GPT-5.4 en competiciones de programación complejísimas.
Beto
Lo cual es una locura.
Alicia
Y lo hace con solo una fracción del consumo computacional.
Beto
OK. Quiero profundizar en cómo lo logran. Porque para entender por qué la eficiencia de V4 es revolucionaria, tenemos que volver a esa imposibilidad del puente.
Alicia
Sí. El problema del escalado.
Beto
El artículo llama al problema central la "complejidad computacional cuadrática de la atención vanilla". Traduce esto a un lenguaje sencillo para nosotros.
Alicia
En las arquitecturas transformer estándar, que son el motor detrás de casi todos los modelos de lenguaje modernos, el mecanismo de atención es cómo la IA entiende el contexto. Para captar el significado de una frase, cada token o fragmento de palabra tiene que mirar atrás a cada otro token generado previamente para ver cómo se relacionan.
Beto
Por ejemplo, la palabra “bank” mira atrás para ver si hemos estado hablando de un río o de dinero.
Alicia
Sí, exactamente. Pero matemáticamente, si duplicas la longitud del texto, en realidad cuadruplicas la cantidad de “miradas atrás” que deben ocurrir.
Beto
Oh, wow.
Alicia
Cuadruplica el trabajo computacional. Así que cuando escalas eso a un contexto de un millón de tokens, los costos de procesamiento se disparan ...
Beto
... porque se está elevando al cuadrado cada vez.
Alicia
Correcto. El modelo mantiene algo llamado "caché de claves y valores" o "KV cache". Es esencialmente la libreta de notas de memoria a corto plazo del modelo. Y para un millón de tokens, esa libreta se vuelve tan gigantesca que físicamente se queda sin espacio en las tarjetas gráficas del servidor.
Beto
¿Cómo lo arregló DeepSeek? No podían simplemente comprar más hardware.
Alicia
No, no. El artículo detalla una arquitectura central totalmente nueva: un mecanismo de atención híbrido. Combinan dos conceptos completamente nuevos: CSA, que significa "Compressed Sparse Attention" (atención comprimida y dispersa), y HCA, "Heavily Compressed Attention" (atención fuertemente comprimida).
Beto
Párate un momento y desglosa CSA primero. Si estoy comprimiendo la libreta de notas de la IA, ¿acaso no la estoy volviendo más tonta al tirar contexto?
Alicia
Suena así, ¿no?
Beto
¿Cómo comprime sin perder el hilo?
Alicia
Bueno. Es altamente dirigido. CSA toma un bloque de tokens —digamos cuatro tokens— y comprime matemáticamente su caché de claves y valores en una sola entrada.
Beto
OK, lo reduce.
Alicia
Sí. Has encogido instantáneamente la longitud de la secuencia. Pero la verdadera magia es lo que ocurre después: usa una estrategia de atención dispersa potenciada por lo que llaman un "indexador relámpago".
Beto
El indexador relámpago suena bonito.
Alicia
Sí. Evalúa todos esos bloques comprimidos y selecciona solo los mejores, los más relevantes.
Beto
Ah, entiendo.
Alicia
El modelo se niega a leerlo todo. Atiende selectivamente solo a los bloques comprimidos más críticos.
Beto
Interesante. ¿Y el otro lado del sistema híbrido, el HCA?
Alicia
HCA opera en otra frecuencia. Usa una tasa de compresión mucho más fuerte, denotada en las fórmulas como n-prima. En lugar de comprimir cuatro tokens, puede comprimir 128 tokens en una sola entrada.
Beto
Wow. Eso es una compresión enorme.
Alicia
Sí. Porque la compresión es tan extrema, la libreta resultante es diminuta, así que no necesita ser dispersa; mantiene atención densa.
Beto
Lo mira todo.
Alicia
Exacto. Observa todos esos bloques fuertemente comprimidos, pero como son muy pocos, la carga computacional es despreciable.
Beto
Déjame ver si puedo mapear esto a un escenario del mundo real para asegurarme de seguir la lógica.
Alicia
Adelante.
Beto
Imagina que pegas un enorme libro de historia de 500 páginas en el chat y haces una pregunta muy específica. HCA es como mi investigador de alto nivel que me da una página con un resumen amplio de cada capítulo. Leo todos esos resúmenes para obtener el contexto general de la línea temporal.
Alicia
Exacto.
Beto
Mientras tanto, CSA es mi especialista que escanea esos resúmenes, localiza las cinco páginas exactas que contienen la respuesta y lee solo esas páginas de cerca.
Alicia
Sí.
Beto
Juntos, me ahorran tener que leer las 500 páginas de cabo a rabo.
Alicia
Muy buena visualización. HCA mantiene el entendimiento macro del documento entero, mientras que CSA aísla los detalles micro allí donde importan, y las ganancias de eficiencia de combinarlos son asombrosas.
En un contexto de un millón de tokens, DeepSeek V4 Pro requiere solo el 27 % de los FLOPs de inferencia por token comparado con su predecesor V3.2.
Beto
Para cualquiera que no esté en servidores, FLOPs son floating point operations — operaciones de punto flotante — básicamente el esfuerzo de cálculo bruto que la máquina tiene que hacer. Una caída del 73 % en cálculo es masiva.
Alicia
Y además solo necesita el 10 % del tamaño del KV cache. Están reduciendo la huella de memoria en un 90 %.
Beto
Wow.
Alicia
Ahora, hay una trampa. Si comprimes todo, puedes perder los detalles finos exactos de las palabras que el usuario acaba de escribir en el cuadro de prompt.
Beto
Oh, claro. Porque todo está resumido.
Alicia
Exacto. Para contrarrestar eso, añadieron una rama de atención de ventana deslizante.
Beto
¿Qué hace eso?
Alicia
Esto obliga al modelo a mantener los tokens más recientes —digamos los últimos 128 tokens de la conversación— completamente sin comprimir. Actúa como un ancla para que la IA nunca pierda el rastro del intercambio inmediato.
Beto
Es una solución increíblemente elegante.
Alicia
Así es.
Beto
Pero diseñar una arquitectura hiper eficiente en papel es una cosa; entrenar un modelo de 1,6 billones de parámetros con compresiones agresivas suena como construir una torre matemática muy inestable.
Alicia
Y lo es.
Beto
Cuando las cosas crecen tanto, tienden a romperse. ¿Cómo evitaron que el sistema masivo colapsara durante el entrenamiento?
Alicia
La estabilidad del entrenamiento fue su segundo gran escollo. Al escalar un MoE a más de un billón de parámetros, las señales que atraviesan las capas profundas de la red pueden explotar fácilmente.
Beto
¿Explotar cómo?
Alicia
Bueno, las matemáticas se acumulan, los números se vuelven tan astronómicos que la computadora literalmente arroja “not a number” y toda la corrida de entrenamiento de millones de dólares se cae. Para evitar esto introdujeron algo llamado MHC, o "manifold constrained hyperconnections", hiperconexiones restringidas por una variedad.
Beto
Me perdí leyendo esa sección. Es difícil de entender.
Alicia
Esa sección es densa.
Beto
Actualizaron las conexiones residuales tradicionales. ¿Pero qué significa “manifold constrained” sin un doctorado en álgebra lineal?
Alicia
Piensa en una conexión residual estándar como una vía de desvío —una autopista de bypass— que permite que la información salte sobre ciertos bloques de procesamiento para mantener la señal fuerte al viajar por capas profundas de la red. Si ensanchas esa autopista demasiado, que es lo que hacen las hiperconexiones estándar, la señal puede amplificarse descontroladamente.
Beto
Ah, y entonces explota.
Alicia
Exactamente. Lo que MHC hace es forzar que el mapeo matemático de esa autopista se ajuste a una variedad específica, concretamente la variedad de matrices doblemente estocásticas.
Beto
Vas a tener que desglosarme lo de las "matrices doblemente estocásticas".
Alicia
Con gusto. Imagina una enorme mesa de mezclas de audio cuyos faders están físicamente y matemáticamente bloqueados de modo que el volumen total de todos los canales combinados nunca pueda exceder el 100 %. Una matriz doblemente estocástica garantiza que las probabilidades a lo largo de las filas y las columnas sumen estrictamente uno.
Beto
Ah, ya veo.
Alicia
Actúa como un límite de velocidad matemático inquebrantable. Asegura que la señal nunca pueda amplificarse más allá de un límite seguro por muy profunda que sea la red.
Beto
Así que MHC actúa como el límite de velocidad que mantiene las señales de explotar.
Alicia
Precisamente.
Beto
También noté que cambiaron por completo el motor bajo el capó: se alejaron del optimizador tradicional "AdamW" para la mayoría de los módulos.
Alicia
Sí. Adoptaron el optimizador "Muon". Muon logra convergencia más rápida y estable durante el entrenamiento usando iteraciones Newton–Schulz híbridas para ortogonalizar las actualizaciones de pesos.
Beto
Espera, tienes que parar de decirme eso tal cual: “iteraciones Newton–Schulz híbridas para ortogonalizar las actualizaciones de pesos” — eso no significa nada para mí.
Alicia
Cierto, lo siento.
Beto
¿Qué hace realmente distinto el optimizador Muon?
Alicia
Piensa en un optimizador tradicional como AdamW como un excursionista que busca el punto más bajo de un valle con los ojos vendados. Da pequeños pasos cautelosos hacia abajo sintiendo la pendiente justo bajo sus pies. Funciona, pero toma millones de pasos diminutos.
Beto
Muy lento.
Alicia
Bien. El optimizador Muon, usando iteraciones Newton–Schulz, no solo “siente” la pendiente, calcula la curvatura más amplia de toda la montaña. Puesto que entiende la geometría general, puede dar saltos enormes y muy calculados hacia el fondo del valle sin tropezar. Es maravillosamente más eficiente para matrices de parámetros enormes.
Beto
Me gusta esa analogía: grandes saltos calculados en lugar de pasos de bebé vendados.
Alicia
Exacto.
Beto
Pero sobre la estabilidad: el artículo menciona picos severos de pérdida e inestabilidad causados por el mecanismo de enrutamiento del Mixture of Experts.
Alicia
Sí, ese fue un punto importante.
Beto
El enrutador envía tokens a diferentes expertos. Ocasionalmente, manda un atasco de datos a un mismo lugar, causando un outlier que básicamente destroza las matemáticas. Si el modelo hace spike o se cae durante el entrenamiento por un mal enrutamiento, ¿por qué no simplemente deshacer? ¿recargar un checkpoint de hace una hora y probar de nuevo?
Alicia
Es un impulso muy común. Pero el equipo de DeepSeek se dio cuenta de que los rollbacks no arreglan el mecanismo subyacente. Si retrocedes, el modelo probablemente dará con el mismo bache matemático 10 minutos después y volverá a hacer spike.
Beto
Oh, porque la lógica está defectuosa.
Alicia
Correcto. El enrutamiento MoE crea un ciclo vicioso: un dato atípico provoca un mal enrutamiento y ese mal enrutamiento agrava el error, creando un outlier aún peor.
Beto
¿Cómo rompes ese bucle de fallos sin empezar de cero?
Alicia
DeepSeek inventó el enrutamiento anticipatorio. Normalmente, una IA usa sus parámetros actuales, al segundo, para decidir dónde enrutar tokens. DeepSeek desacopló el enrutamiento: calculan los índices de enrutamiento usando parámetros históricos de un paso de entrenamiento anterior.
Beto
Ah, ya veo. El cerebro principal procesa los datos en el momento presente, pero el semáforo que dirige el tráfico opera con un pequeño retraso usando el mapa estable y probado de ayer.
Alicia
Precisamente. Al usar parámetros históricos para las decisiones de enrutamiento evitas que una anomalía repentina en tiempo real arruine instantáneamente la lógica de enrutamiento.
Beto
Eso es muy inteligente.
Alicia
Rompe por completo el ciclo vicioso de outliers.
Beto
Así que con MHC, Muon y enrutamiento anticipatorio, tenemos una arquitectura rápida y matemáticamente a prueba de balas.
Alicia
Sí.
Beto
Pero un cerebro rápido y estable que no sabe nada es totalmente inútil. ¿Cómo pones la inteligencia en esta arquitectura, especialmente en campos complejos y recientes como matemáticas avanzadas y programación?
Alicia
Aquí su pipeline de post-entrenamiento diverge completamente de las normas de la industria. Tradicionalmente, tras la fase cruda de preentrenamiento, los desarrolladores usan una mezcla de reinforcement learning from human feedback (RLHF) para alinear el modelo.
Beto
Para enseñarle a responder apropiadamente.
Alicia
Exacto. DeepSeek reemplazó por completo esa etapa mixta de RL con "distilación on-policy multi-profesor", o OPD.
Beto
Explícanos cómo funciona un setup multi-profesor. Suena a universidad de IA.
Alicia
Básicamente lo es. Primero, no intentan entrenar un modelo gigante que domine todo al mismo tiempo. Entrenan modelos docentes separados y altamente especializados: uno se entrena agresivamente para ser un experto mundial en matemáticas usando recompensas específicas de RL; otro se entrena exclusivamente en ingeniería de software. Una vez que tienen esa “facultad” de especialistas brillantes, usan OPD para destilar todo ese conocimiento aislado en un único modelo estudiante.
Beto
Pero con la distilación suele haber una gran pérdida de fidelidad.
Alicia
Normalmente lo hace.
Beto
Es como sacar una fotocopia de una fotocopia. Normalmente el estudiante obtiene la idea general pero pierde matices.
Alicia
Eso es un fallo conocido, por eso DeepSeek usa distilación de lógica de vocabulario completo. En métodos antiguos, el modelo estudiante solo mira al profesor y trata de copiar la única palabra final que el profesor emite:
Beto
Solo la respuesta.
Alicia
Pero DeepSeek obliga al estudiante a observar la distribución completa de probabilidades del profesor a lo largo de todo el vocabulario de más de 100.000 palabras.
Beto
¿Qué significa eso en la práctica?
Alicia
Significa que el estudiante no solo ve la respuesta final; aprende exactamente cómo el profesor ponderaba cada opción posible antes de hablar. Por qué el profesor de matemáticas consideró la palabra "hence" con un 40 % de probabilidad pero al final eligió "therefore" con un 60 %.
Beto
Así ve el proceso de pensamiento.
Alicia
Exacto. El estudiante absorbe la duda, la confianza y la lógica subyacente del profesor en cada token. Transfiere la verdadera profundidad del razonamiento del profesor.
Beto
Así que si usas este modelo, no es una licuadora que machacó datos de matemáticas y programación en una masa gris. Dependiendo del prompt, el modelo unificado puede encauzar dinámicamente los patrones lógicos del experto en matemáticas o del experto en código según el trabajo.
Alicia
Esa precisión cambia mucho el comportamiento del modelo en tiempo de inferencia. Y lo vemos en sus paradigmas de escalado en test time: el modelo tiene tres modos de razonamiento distintos: non-think, think y think-max.
Beto
OK. Non-think es autoexplicativo: respuestas rápidas e intuitivas para tareas rutinarias como redactar un correo. Think es para problemas complejos donde muestra su cadena de pensamiento. Pero think-max es cuando dejan al modelo completamente desatado.
Alicia
Think-max empuja las capacidades de razonamiento al límite absoluto, no se permiten atajos. Inyectan un prompt de sistema oculto que ordena al modelo descomponer el problema exhaustivamente, poner a prueba su propia lógica contra casos extremos y documentar cada hipótesis rechazada antes de dar una respuesta final.
Beto
Y gracias a ese contexto barato de un millón de tokens del que hablamos, tiene un superpoder agentivo que el artículo llama "interleaved thinking" —pensamiento entrelazado—.
Alicia
Esto es quizás la mejora más crucial para flujos de trabajo reales. En modelos anteriores, si la IA usaba herramientas externas —por ejemplo, ejecutar código Python, buscar en la web, comprobar resultados— y luego el usuario enviaba un nuevo mensaje de seguimiento, el modelo a menudo tenía que borrar sus trazas de razonamiento previas para ahorrar memoria.
Beto
Ay, Dios.
Alicia
Tenía que reconstruir su estado de resolución de problemas desde cero.
Beto
Si has trabajado con una IA en un proyecto largo y de repente olvida por qué escribió la línea 40, es muy frustrante.
Alicia
Exacto. En V4, porque procesar ese contexto masivo es tan barato usando CSA y HCA, retiene la cadena completa de pensamiento a través de múltiples rondas de llamadas a herramientas y mensajes de usuario.
Beto
Eso es impresionante.
Alicia
Mantiene un proceso de pensamiento coherente y acumulativo a lo largo de tareas de largo horizonte.
Beto
Y los resultados del modo think-max son francamente impresionantes: en el benchmark Putnam 2025 de matemáticas, que exige pruebas formales rigurosas y es notoriamente brutal, DeepSeek V4 Pro Max sacó 120 de 120 — una puntuación perfecta en verificación matemática formal.
Alicia
Increíble.
Beto
Y en Codeforces, que es una plataforma de programación altamente competitiva para humanos, el modelo alcanzó una clasificación ELO de 3206. Eso lo sitúa en el puesto 23 a nivel mundial entre todos los concursantes humanos. Demuestra que los modelos de código abierto pueden igualar sin ambigüedades a los gigantes cerrados más avanzados.
Alicia
Igual de impresionante es que incluso el modelo más pequeño, V4 Flash, cuando se pone en modo think-max, logra un rendimiento de razonamiento comparable al de modelos mucho más grandes.
Beto
¿En serio?
Alicia
Sí. Prueba que escalar el cómputo en tiempo de prueba —simplemente dar al modelo más tiempo para pensar— puede cerrar la brecha de inteligencia causada por tener menos parámetros.
Beto
Ahora jugaré al escéptico un minuto.
Alicia
Adelante.
Beto
Todo eso suena increíble, pero ejecutar un modelo tan brillante con un contexto de un millón de tokens normalmente requiere un superordenador del tamaño de un almacén. ¿Cómo se despliega eficientemente sin que el usuario espere 10 minutos por una respuesta?
Alicia
DeepSeek V4 brilla en su infraestructura de despliegue. La primera innovación mayor para reducir la huella es la cuantización FP4.
Beto
Espera. ¿Bajar a un formato de punto flotante de 4 bits? ¿No hace que el modelo se vuelva estúpido e inexacto de inmediato?
Alicia
Naturalmente uno lo asumiría. Reducir la precisión suele destruir el matiz. Pero comprimen los enormes pesos MoE —que ocupan la mayor parte de la memoria física de la GPU— a FP4. Durante el cómputo real, usan una des-cuantización sin pérdida a FP8.
Beto
¿Cómo puede ser sin pérdida si ya tiraste bits para comprimirlo?
Alicia
No es volver a quemar un papel; es más como comprimir un archivo para transporte. FP8 tiene dos bits de exponente adicionales comparado con FP4, dándole un rango dinámico mucho mayor. Mientras la información de escala fina del bloque FP4 se mantenga dentro de cierto umbral, ese rango dinámico extra en FP8 absorbe por completo los factores de escala al descomprimirlo.
Beto
Ya entiendo.
Alicia
El modelo calcula exactamente como si estuviera en mayor precisión, pero en despliegue ahorras enormes cantidades de ancho de banda de memoria.
Beto
Un truco de hardware brillante.
También atacan la caché con almacenamiento del KV cache en disco. Imagina que pegas un PDF legal de 500 páginas en el chat y haces una pregunta y responde. Al día siguiente, tu colega inicia sesión, accede al mismo documento compartido y hace otra pregunta. Normalmente la IA tiene que volver a leer las 500 páginas desde cero, costeando tiempo y cómputo.
Alicia
Pero DeepSeek guarda esas entradas comprimidas de CSA y HCA directamente en disco SSD. Si haces una nueva pregunta sobre un documento compartido, simplemente carga el estado comprimido desde el disco. Elimina el rellenado repetido para solicitudes con prefijos compartidos, que es un cuello de botella masivo al servir modelos de lenguaje a millones de usuarios.
Beto
Pero el verdadero cuello de botella en chats de IA no siempre es la lectura; es la preparación.
Alicia
Sí, la sobrecarga.
Beto
Si pregunto algo en un chat, normalmente un modelo pequeñito tiene que ejecutarse primero solo para decidir tareas auxiliares: ¿requiere esta petición una búsqueda web? ¿En qué dominio está?
Alicia
Exacto.
Beto
Correr un modelo separado añade tiempo. Si DeepSeek tuviera que ejecutar un modelo pequeño primero para ver si hay que buscar en la web, ¿no mataría eso la velocidad?
Alicia
Normalmente sí, porque requiere rellenados redundantes. DeepSeek lo evita totalmente inventando tokens de instrucción rápidos.
Beto
¿Qué son esos?
Alicia
Adjuntan tokens especiales dedicados —por ejemplo, un token disparador de búsqueda o un token de intención— directamente a la secuencia de entrada del modelo principal.
Beto
Ah. Es como una cocina que reutiliza una gran olla de agua hirviendo para múltiples órdenes de pasta en vez de hervir una olla nueva desde fría cada vez que entra un ticket. Ya computaron el KV cache para esas tareas auxiliares. Reduce drásticamente el tiempo hasta el primer token. Obtienes tu respuesta al instante.
Alicia
Elimina la sobrecarga de ingeniería de mantener un modelo extra pequeño y mejora la experiencia de usuario.
Beto
En resumen: lo que DeepSeek V4 ha hecho es tomar el puente imposible de la atención cuadrática y encontrar una nueva física para construirlo usando la compresión inteligente de CSA y HCA. Lo estabilizaron para el delicado entrenamiento de 1,6 billones de parámetros inventando enrutamiento anticipatorio para detener bucles de fallos matemáticos. Alcanzaron inteligencia de primera línea usando distilación con vocabulario completo para aprender de expertos especializados. Y lograron desplegar todo esto eficientemente en hardware mediante cuantización y almacenamiento en disco.
Alicia
Es una clase magistral de optimización full-stack, desde las variedades matemáticas centrales hasta el despliegue físico en servidores.
Beto
Hemos hablado de contexto como una ventana para que tú la uses: un millón de tokens para examinar un proyecto masivo. Pero si el contexto ahora es barato de mantener y las trazas de razonamiento de la IA pueden conservarse indefinidamente sin arrasar un centro de datos, la ventana básicamente se convierte en memoria.
Alicia
Un hilo continuo.
Beto
Imagínate una IA que nunca se reinicie cuando cierras el navegador. Una que aprenda de una vida de conversaciones contigo, actualizando su propio entendimiento interno en tiempo real. Ya no estamos hablando solo de calculadoras más rápidas. Estamos ante la arquitectura fundamental para entidades digitales con memorias permanentes y en evolución.
Alicia
La muralla del cómputo ha caído. Cambia exactamente a dónde podemos viajar a continuación.
Beto
Gracias por acompañarnos en esta inmersión. Sigue cuestionando los límites.



{kind=link}