
Esta investigación introduce un marco teórico formal y una tarea algorítmica para evaluar la creatividad combinatoria en Modelos de Lenguaje Grandes (LLMs). Al modelar espacios conceptuales como grafos sintéticos, los autores evalúan cómo los modelos generan caminos novedosos y útiles entre ideas distantes mientras se adhieren a restricciones específicas. El estudio identifica un comportamiento de escala predecible, señalando que las arquitecturas más amplias y superficiales a menudo superan a las más profundas dentro de presupuestos computacionales fijos. Se descubrió un compromiso persistente entre novedad y utilidad en todos los tamaños de modelo, lo que explica por qué la IA puede tener dificultades para garantizar la viabilidad práctica a pesar de generar ideas altamente originales. Esta brecha entre ideación y ejecución se caracteriza además por un análisis de tipos de error, como alucinaciones e inconsistencias lógicas. En última instancia, los hallazgos ofrecen un punto de partida fundamental para cerrar la brecha entre la percepción similar a la humana y la inteligencia artificial.
Enlace al artículo científico, para aquellos que quieran profundizar en el tema: "Combinatorial Creativity: A New Frontier in Generalization Abilities", por Samuel Schapiro y colegas. Publicado en Enero 2 del 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
"El juego combinatorio parece ser la característica esencial del pensamiento productivo." Esa es una cita famosa atribuida a Albert Einstein. Y captura de manera brillante esta idea, este proceso cognitivo detrás de grandes avances. Quiero decir, miras la historia: la imprenta, la teoría de la selección natural de Darwin. El progreso tan a menudo viene de conectar cosas que antes parecían totalmente no relacionadas. "¿Qué pasa si combinamos esto con aquello?"
Y ese es realmente el objetivo último de la IA moderna, de los LLMs (modelos de lenguaje grande): empujarlos más allá de solo generar texto y hacia ese reino de verdadera intuición creativa, especialmente para cosas como proponer ideas científicas nuevas y viables.
Eso plantea la gran pregunta, ¿no? ¿Cómo sabemos si una máquina está siendo genuinamente creativa, o si solo está escupiendo palabras convincentes pero inútiles?
Alicia
Ese es el perfecto punto de partida para el análisis de hoy.
Nos enfocamos en un tipo muy específico de creatividad aquí. Se llama creatividad combinatoria, o CC. La definición es simple: generar ideas novedosas tomando conceptos familiares y formando combinaciones útiles pero inesperadas. Es creatividad por remezcla. Pero como dijiste, los LLMs ahora suelen tener un problema importante que la gente llama "la brecha entre ideación y ejecución". Pueden generar 100 ideas novedosas para energía sostenible, pero 99 de ellas son físicamente imposibles, demasiado caras o dependen de tecnología que no existe aún.
Beto
Creativas pero inútiles.
Alicia
Exacto.
Beto
Nuestra misión hoy es desentrañar un marco formal totalmente nuevo que investigadores diseñaron específicamente para poner a prueba esta habilidad de CC en los LLMs. Y es crucial porque no solo evalúa a la IA; parece explicar por qué esa brecha ideación-ejecución persiste tanto.
Bien, desmenuzémoslo.
Antes incluso de llegar a los resultados, ¿cómo empiezan los investigadores a medir algo tan escurridizo como la creatividad de una máquina? Si aplicas pruebas de precisión tipo examen, fallan completamente.
Alicia
Es demasiado abierto. Así que hay que empezar con una definición computacional. Históricamente, la creatividad se define como generar artefactos que sean al mismo tiempo novedosos, útiles y sorprendentes. Para este estudio, básicamente combinaron novedad y sorpresa en una sola dimensión. Así que en realidad miden dos cosas: novedad y utilidad.
Y para probar eso, no se limitaron a pedirle a un LLM que escribiera un ensayo. Modelaron la creatividad dentro de un espacio conceptual.
Beto
¿Qué significa eso?
Alicia
Puedes pensarlo como un gran grafo sintético, un mapa semántico masivo de todo un campo de conocimiento, por ejemplo la ciencia de materiales. Los conceptos son los nodos del grafo y las relaciones entre ellos son las aristas etiquetadas.
Beto
Entonces el modelo no está generando texto libre; está haciendo una tarea muy estructurada. El reto es generar un artefacto creativo, que se define literalmente como un camino en ese grafo. Básicamente le dices al LLM: aquí está el concepto A y aquí el concepto Z, encuentra un camino viable entre ellos.

Creatividad combinatoria y asociaciones cognitivas
Alicia
Sí. Exacto.
Beto
¿Cómo llegar de A a Z usando relaciones como “se conecta con” o “es precursor de”? Y la magia es que la evaluación entonces mide esa creatividad en grados, no solo como aprobado o reprobado.
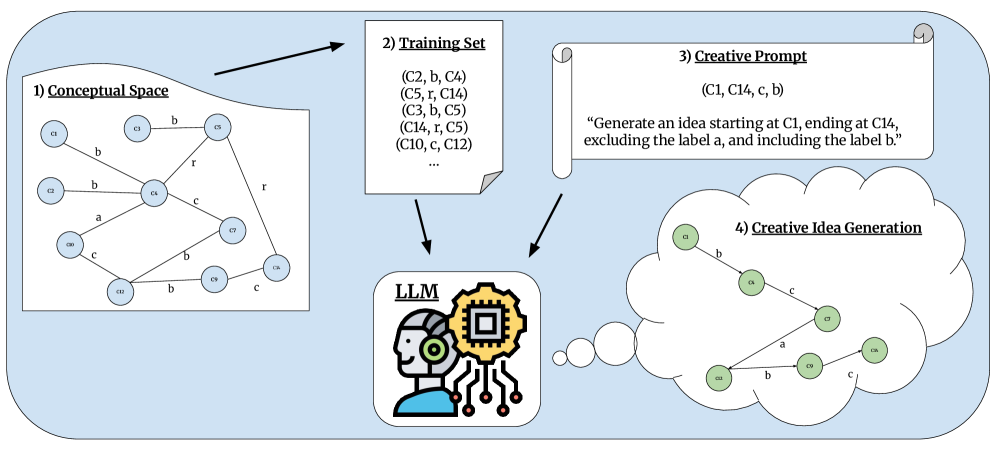
Marco algorítmico, abierto, para evaluar habilidades de creatividad combinatoria.
Alicia
Precisamente. Y en cuanto a cómo califican ese camino, empezamos por la utilidad. Esta es la parte práctica del seguimiento de reglas, y se maneja mediante restricciones lógicas que se ponen directamente en el prompt. Simula límites del mundo real. Hay dos tipos principales.
Primero, el conjunto de inclusión: son etiquetas que deben aparecer en el camino en algún punto. Si estás resolviendo un problema, podrías exigir que incluya la etiqueta “por compatible con”.
Luego está el conjunto de exclusión: etiquetas que deben evitarse. Si tienes un presupuesto pequeño, podrías excluir la etiqueta “requiere gases nobles”.
Beto
Es una gran configuración. Toma esta idea abstracta de factibilidad y la convierte en algo concreto, computable. Así que utilidad es simplemente seguir las reglas del dominio. Y cuanto más reglas añades, más difícil es, pero más útil será la idea final.
Alicia
Exacto. Ahora pasemos a la novedad. Aquí es donde medimos esa chispa creativa. Usan dos métricas para esto.
La primera es bastante directa: la longitud del camino, la distancia del recorrido en el grafo. Un camino más largo, que conecta dos conceptos muy distantes y no relacionados, es inherentemente más novedoso que uno corto. Es un salto mayor.
Beto
Eso tiene sentido.
Pero la segunda métrica es donde creo que entra la verdadera sutileza. Está bajo un pequeño baile: mencionaste la sorpresa de las etiquetas de arista, algo sobre "el logaritmo negativo de la probabilidad" ("average negative log-likelihood").
Alicia
Y necesitamos desmitificar ese jerga. Piensa en el grafo como un registro de todas las relaciones comunes que existen. Una relación de alta probabilidad, algo con una puntuación baja, podría conectar “agua” con “hidratación”.
Beto
Súper obvio. Eso no gana un Nobel.
Alicia
Cero sorpresa. La sorpresa es lo opuesto: es una medida de cuán raramente el modelo ha visto esa conexión específica. Así que si el modelo conecta “por reactor” con “poesía” mediante alguna arista rara e inusual, eso obtiene una puntuación muy alta. El modelo es recompensado no solo por hacer un salto largo, sino por usar una secuencia de pasos realmente inusual para llegar allí.
Beto
Eso cuantifica el valor de una combinación inesperada pero aún funcional.
Pero esto nos regresa a ese dolor de cabeza que mencionamos al principio: la brecha ideación-ejecución. El modelo nos da algo sorprendente, pero a menudo totalmente inutilizable.
Alicia
Y lo fascinante es que el estudio sugiere que esto no es solo un fallo aleatorio de la IA; parece explicarse por un límite teórico fundamental dentro de los propios modelos: "la compensación novedad-utilidad". En todos los tamaños de modelo que probaron, desde 1 millón hasta 100 millones de parámetros, el hallazgo fue claro y consistente. A medida que aumentas el número de restricciones de utilidad — las reglas que impones — la novedad de las ideas generadas mostró una tendencia descendente clara y consistente.
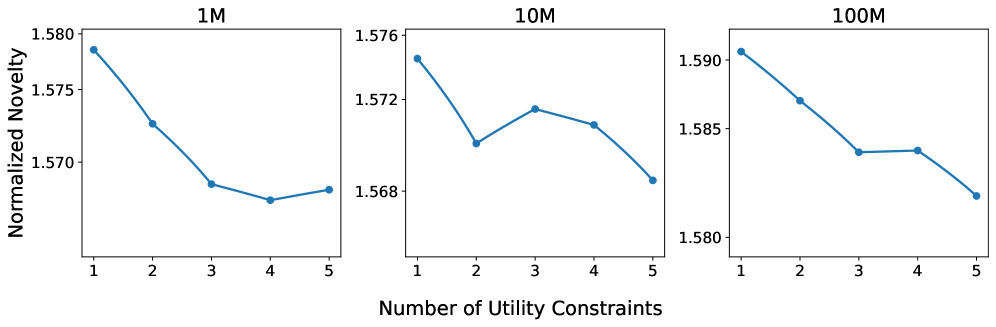
La compensacion novedad-utilidad persiste entre las escalas.
Beto
Espera, entonces: cuanto más restricciones agregamos, cuanto más forzamos al modelo a ser práctico, menos creativo se vuelve.
Alicia
Eso es lo que muestran los datos.
Beto
Esa es una tensión realmente difícil. Si exigimos factibilidad, estamos activamente limitando la capacidad de la IA para darnos una idea revolucionaria.
Alicia
Es esencialmente un juego de suma cero con la arquitectura actual. Si obligas al modelo a recorrer un camino que incluya pasos comunes y de alta utilidad, simplemente recurre a caminos cortos y más familiares, con baja novedad.
Beto
Y si pides alta novedad ...
Alicia
Si pides algo súper largo y raro, tiende a romper las reglas porque encontrar un camino que sea raro y que al mismo tiempo cumpla todos tus puntos prácticos es computacionalmente muy, muy difícil.
Beto
Los investigadores ofrecen una forma útil de mapear estas restricciones abstractas a fallos reales en ciencia. Las restricciones de exclusión — las cosas que prohíbes — son básicamente una manera de prevenir supuestos poco realistas o planes prohibitivamente caros. Si le dices al modelo “no uses reactor de fusión”, estás imponiendo una restricción de presupuesto del mundo real.
Alicia
En el otro extremo, las restricciones de inclusión, las etiquetas que exiges, se tratan de asegurar rigor: es como exigir que una idea incluya una línea base adecuada para comparación o tenga un plan de implementación detallado, requiriendo la etiqueta “grupo de control”. Y por eso el hallazgo es tan importante: que esta compensación novedad-utilidad sigue ahí incluso a la escala de 100 millones de parámetros es una señal de alarma.
Beto
¿Por qué?
Alicia
Sugiere que simplemente escalar a modelos de miles de millones de parámetros no va a arreglar mágicamente el problema de la factibilidad. Podríamos estar solo consiguiendo ideas más convincentes pero igual de limitadas.
Beto
Tengo que desafiar eso un poco. El modelo más grande usado aquí fue de 100 millones de parámetros. Eso es diminuto comparado con lo que hay hoy día.
Alicia
Es una pregunta justa.
Beto
¿Es posible que la compensación se deshaga cuando llegas a cientos de miles de millones de parámetros?
Alicia
Sí, es posible. Pero la tendencia fue tan robusta a través de tres órdenes de magnitud — 1M, 10M, 100M — que realmente implica que esto podría ser una consecuencia fundamental de la arquitectura transformer en sí. Esta tensión entre explotar caminos comunes de alta utilidad y explorar caminos raros de alta novedad parece estar cableada. Si no mejoró con un aumento de 100x, ¿por qué un aumento de 1000x la borraría?
Beto
Entonces necesitamos otro enfoque. Si simplemente hacerlos más grandes no resuelve la compensación, quizá la estructura del modelo sea la clave. Y aquí es donde se pone realmente interesante. Los investigadores miraron la arquitectura del modelo, específicamente profundidad versus ancho.
Alicia
Sí. El número de capas frente a la dimensión de embedding, manteniendo el total de parámetros igual. Los resultados fueron contraintuitivos. Encontraron un punto óptimo arquitectónico. Asumimos que más profundo siempre es mejor, pero los datos muestran que para un presupuesto de parámetros dado hay un número óptimo de capas. Si vas más profundo que eso, el rendimiento realmente empieza a empeorar.
Beto
¿Y cómo fue ese punto óptimo para los modelos más grandes?
Alicia
Para los modelos de 100 millones de parámetros, la creatividad máxima estuvo justo alrededor de ocho capas. Si tomabas esos mismos parámetros y los repartías en, por ejemplo, 12 capas, el rendimiento bajaba.
Beto
Eso choca con las leyes de escalado que solemos oír. ¿Por qué añadir más capas, más pasos de procesamiento, empezaría a perjudicar la creatividad?
Alicia
Tiene que ver con la naturaleza de esta prueba específica de creatividad combinatoria. No estás intentando resolver un rompecabezas lógico profundo; estás intentando asociar conceptos distantes aparentemente no relacionados. Vimos lo mismo con el ancho del modelo, la dimensión de embedding. Había una proporción óptima ancho/profundidad, la proporción E/L, que era la mejor para la creatividad. Y fue consistentemente entre 200 y 300 en las tres escalas.
Beto
La proporción E/L. E representa la capacidad de representación, cuántas ideas diferentes puede contener al mismo tiempo; L es cuántos pasos puede dar para conectarlas. ¿Qué nos dice esa proporción óptima de 200–300?
Alicia
Que la CC necesita un equilibrio muy delicado: un modelo demasiado profundo y estrecho — piensa en un rascacielos biblioteca muy alto y delgado — es genial para razonamiento secuencial largo, una caminata profunda, pero tiene capacidad de representación restringida; no tiene el “espacio en los estantes” para guardar todos los conceptos diversos que necesita para hacer una combinación novedosa. Es un gran lógico, pero un mal soñador.
Beto
Y lo contrario, un modelo demasiado ancho y poco profundo — como un gran almacén de una sola planta — tiene todos los conceptos ahí, pero no puede hacer el razonamiento secuencial profundo necesario para satisfacer todas las reglas de utilidad.
Alicia
No puede trazar esos caminos lógicos largos. Así que el punto óptimo es un término medio sano: lo bastante profundo para razonar, lo bastante ancho para asociar.
La pieza final de evidencia es el análisis de errores. A medida que los modelos crecían, el tipo de errores que cometían cambió de forma dramática.
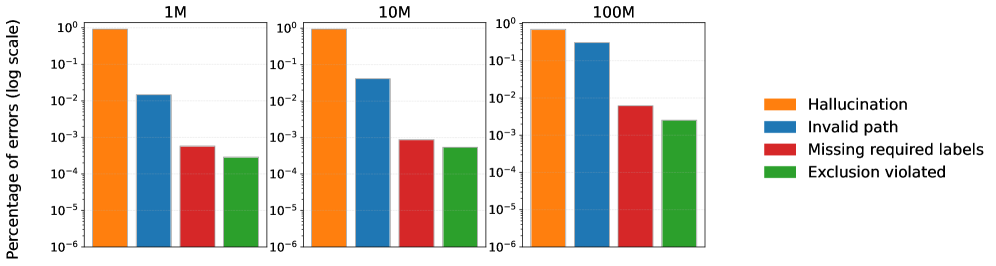
La distribución de los tipos de errores en la tarea de creatividad combinatoria
Beto
¿Como?
Alicia
En las escalas más pequeñas, 1M y 10M, los errores eran mayormente alucinaciones: el modelo se inventaba una arista o un nodo que ni siquiera existía en el grafo. Se había quedado sin ideas.
Beto
La versión IA de inventar una fuente para tu ensayo: un fallo superficial y obvio.
Alicia
Pero a la escala de 100M, las alucinaciones cayeron drásticamente. El modelo conocía las reglas del grafo, pero los errores de ruta inválida, donde fallaba en cumplir las restricciones lógicas, crecieron hasta ser casi igualmente frecuentes.
Beto
Escalar hace que la IA suene más convincente porque deja de cometer esos errores factuales obvios, pero no resuelve el problema fundamental de equilibrar las reglas con el salto creativo. Simplemente falla de manera más elegante.
Alicia
Esa es la conclusión central. Los modelos más grandes ocultan los errores superficiales, pero el problema más profundo de inconsistencias lógicas o fallos en la utilidad sigue ahí. Sugiere que la compensación novedad-utilidad es el verdadero cuello de botella.
Conectándolo al panorama más amplio: dado que esta compensación parece persistente y variante con la escala, el artículo sugiere que simplemente tirar más parámetros quizá no sea la mejor vía.
Beto
¿Qué sí funciona?
Alicia
Estrategias alternativas, específicamente técnicas en tiempo de inferencia, como el auto-refinamiento, donde un modelo más pequeño genera una idea y luego usa su propia lógica para verificarla contra las restricciones. Mejora iterativa.
Beto
Esa es una conclusión poderosa. Usar modelos más pequeños y estructurados óptimamente, pero hacerlos más inteligentes con técnicas de refinamiento, podría ser una mejor manera de democratizar la IA creativa en lugar de la carrera interminable por modelos fronterizos más grandes que aún tienen estos problemas fundamentales.
Para resumir las conclusiones clave: la creatividad en IA es algo que realmente podemos medir y escalar, pero es extremadamente sensible a la estructura del modelo. Ahora tenemos un marco formal para probarla. Y, crucialmente, esta tensión entre novedad y factibilidad no parece ser solo un problema de ingeniería; parece un desafío teórico fundamental: si quieres más novedad, tiendes a sacrificar utilidad. El estudio que analizamos hoy solo miró la creatividad combinatoria, solo combinar conceptos familiares.
Los propios autores señalan que trabajos futuros deberían explorar formas superiores:
- una es la creatividad exploratoria, como AlphaGo encontrando un movimiento nuevo al seguir perfectamente las reglas existentes del Go;
- y la forma más alta es la creatividad transformacional, que reestructura las reglas mismas, como hizo Einstein con la relatividad.
Y eso plantea una pregunta importante: ¿esas formas superiores de creatividad también estarán atrapadas por la misma compensación novedad-utilidad a medida que la IA escala? ¿O eso es algo único de solo remezclar ideas viejas? Es algo para reflexionar al pensar en el futuro del descubrimiento asistido por IA.



{kind=link}