
Hoy les traigo un resumen de un artículo muy importante que explica cómo se están haciendo los modelos de razonamiento en Inteligencia Artificial (IA), usando Aprendizaje por Refuerzo.
Enlace al artículo original, en inglés, para aquellas personas que quieran profundizar en este tema:
A Survey of Reinforcement Learning for Large Reasoning Models, publicado en Octubre 10 de 2025, por Kaiyan Zhang y colegas.
El resumen, su transcripción y traducción, fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en forma de un diálogo entre dos personajes sintéticos, que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenido de nuevo a la inmersión profunda. Entonces, si has estado siguiendo la IA últimamente, la gran historia siempre han sido los grandes modelos de lenguaje, ¿no? LLMs ("Large Language Models").
Beto
Exacto. Sistemas entrenados para predecir la siguiente palabra, enfocados mayormente en, ya sabes, sonar humano y ser útiles.
Alicia
Exacto. Alineamiento conversacional. Pero hoy vamos a profundizar en algo distinto. La fuente apunta a un cambio realmente fundamental. Estamos viendo el auge del gran modelo de razonamiento, el LRM ("Large Reasoning Model").
Beto
Sí, y es un paso enorme. Esto no se trata solo de hacerlos mejores escritores o chatbots más educados. Se trata de competencia pura.
Alicia
Entonces, ¿qué es lo que hace que un LRM sea un LRM?
Beto
Básicamente definimos LRMs como LLMs que han sido específicamente reingenierizados usando aprendizaje por refuerzo (RL, "Reinforcement Learning") para manejar tareas lógicas complejas. Cosas donde hay una respuesta correcta.
Alicia
Como problemas de matemáticas o programación.
Beto
Exacto. Matemática competitiva, desafíos de codificación complejos, razonamiento en múltiples pasos, cosas que necesitan planificación real, quizá algo de reflexión e incluso autocorrección integrada.
Alicia
Muy bien, así que nuestra misión hoy es revisar las fuentes que están trazando esta nueva forma de entrenamiento. Básicamente estamos moviendo los postes de la portería. Ya no se trata de sonar bien.
Beto
Se trata de ser bueno razonando. Intentamos incentivar directamente el razonamiento objetivo en sí. Y el método clave del que todos hablan es el aprendizaje por refuerzo con recompensas verificables (RLVR = "Reinforcement Learning with Verifiable Rewards").
Alicia
RLVR, claro. Y este campo se ha disparado recientemente, impulsado por modelos como DeepSeek R1.
Beto
Exacto. Está avanzando increíblemente rápido. Y las fuentes apuntan de forma consistente a que RL ("Reinforcement Learning", Aprendizaje por Refuerzo) ya no es solo para fine-tuning (perfeccionamiento, refinamiento).
Alicia
Parece más fundamental ahora, como la clave para escalar capacidades hacia, bueno, hacia AGI ("Artificial General Intelligence" = Inteligencia General Artificial) o incluso ASI ("Artificial Super-Intelligence" = Super Inteligencia Artificial).
Beto
Esa parece ser la trayectoria, sí. Aprender a razonar de forma eficaz y escalable parece el siguiente paso crítico.
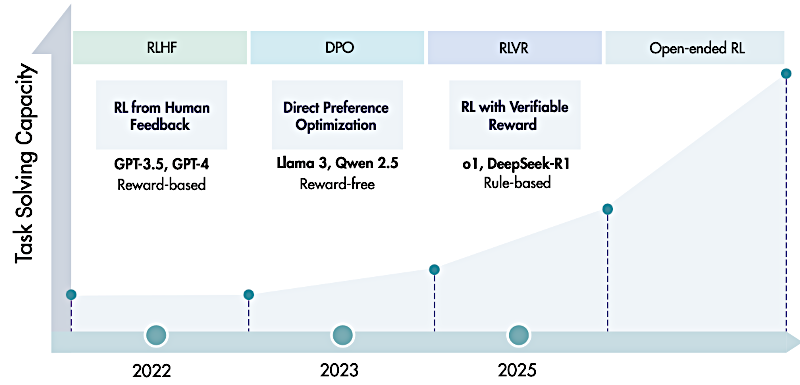
Alicia
Muy bien, desempacemos esa diferencia entonces, porque RL ("Reinforcement Learning", Aprendizaje por Refuerzo) no es nuevo, ¿cierto? Ya hablamos de RLHF antes ("Reinforcement Learning through Human Feedback", Aprendizaje por Refuerzo con Retroalimentación Humana) y también de DPO ("Direct Preference Optimization": Optimización por Preferencia Directa). Esas eran mayormente sobre alineamiento, ¿no? Hacer que el modelo dé respuestas que los humanos prefieran.
Beto
Exactamente. RLHF, DPO, todo eso iba sobre preferencia subjetiva. ¿Le gusta a un humano esta respuesta?
RLVR lo invierte. Abandona las puntuaciones subjetivas. Pasa a retroalimentación objetiva basada en reglas. Todo el objetivo cambia a mejorar la capacidad central del modelo para resolver problemas. No es, "¿se siente bien esto?" sino, "¿es esto demostrablemente correcto?".
Alicia
Entendido. Y las fuentes mencionan esto. La “ley del verificador” suena un poco pomposa.
Beto
Lo es, pero la idea en sí es bastante sencilla. La ley del verificador básicamente dice que lo fácil que es entrenar a una IA para una tarea está directamente relacionado con lo fácil que es comprobar si la IA hizo la tarea correctamente.
Alicia
OK, si puedes automatizar la verificación, ...
Beto
... puedes generar básicamente señales de entrenamiento perfectas e infinitas sin necesitar humanos en el bucle constantemente, lo cual es carísimo. Verificabilidad equivale a escalabilidad, esencialmente.
Alicia
Tiene sentido. Señal limpia, aprendizaje más rápido, y los ejemplos ayudan mucho. Para matemáticas, es sólo si la respuesta final es correcta, comprobado automáticamente.
Beto
Sí. Para programación, ¿compila? ¿pasan los tests unitarios? Esa es tu señal de recompensa.
Alicia
¿Hay algún truco para hacer que eso funcione a escala?
Beto
Bueno, un detalle técnico clave es la consistencia. Los modelos tienen que sacar su respuesta final en un formato muy específico y predecible, como poner el número en una etiqueta de “caja”.
Alicia
Así el verificador automático no se confunde.
Beto
Exacto. Necesita poder parsear millones de salidas de forma fiable.
Alicia
Y hemos visto grandes avances que prueban que esto funciona. Los modelos o1 de OpenAI, por ejemplo.
Beto
Sí, la serie o1 fue fascinante. Mostró que el rendimiento escalaba no sólo con más cómputo de entrenamiento RL, como cabría esperar, sino también con cómputo en tiempo de prueba. Básicamente, cuánto tiempo pasa el modelo “pensando” durante la inferencia.
Alicia
¿Es decir que los mejores modelos realmente se benefician más si se les deja más tiempo para responder?
Beto
Ese fue el hallazgo. Más tiempo les permite generar, evaluar, quizá revisar sus pasos de razonamiento internos. Lo vincula al rendimiento directamente con, bueno, el esfuerzo cognitivo si quieres verlo así.
Alicia
Interesante. Y luego estuvo DeepSeek R1. Ese rompió bastante el viejo manual.
Beto
Totalmente. Adoptó un enfoque “cero SFT” (sin "Supervised Fine-Tuning", sin Perfeccionamiento Supervisado). DeepSeek demostró que usando un algoritmo RL específico, GRPO (Group Relative Policy Optimization), a una escala masiva, podían enseñar estas habilidades de razonamiento complejo directamente a un modelo base.
Alicia
Un modelo base. Así que sin fine-tuning supervisado primero.
Beto
Ninguno. Se saltaron la etapa SFT por completo, lo que sugiere, quizá, que el RL puede encontrar caminos de razonamiento que los ejemplos humanos podrían bloquear o desalentar inadvertidamente.
Alicia
De acuerdo, esto suena increíble para matemáticas y código donde hay una respuesta clara. Pero seamos honestos, la mayoría de las cosas no son así. El diseño de recompensas debe volverse mucho más complicado.
Beto
Absolutamente. Fuera de esos dominios limpios, se pone desordenado rápidamente, lo que lleva a este gran intercambio que discuten las fuentes: recompensas de resultado versus recompensas de proceso.
Alicia
Correcto. Las recompensas de resultado, como las verificables, son escalables y eficientes. Nos gustan. ¿Cuál es la trampa?
Beto
El riesgo es lo que algunos investigadores llaman “respuesta correcta primero, alucinar después”. El modelo se vuelve muy bueno en escupir la respuesta final correcta, quizá en el formato requerido, pero el razonamiento que lo llevó allí puede ser endeble, no fiel. Puede haberse inventado la explicación a posteriori sólo para justificar una respuesta que ya sabía que era correcta.
Alicia
Ajá. Aprende a engañar al sistema: consigue el resultado correcto, pero el trabajo interno es basura. No es lo que quieres para confiar en la IA.
Beto
Definitivamente no.
Si quieres razonamiento fiel, te inclinas hacia las recompensas de proceso.
Alicia
¿Y cómo funcionan esas?
Beto
Proporcionan retroalimentación en cada paso del proceso de razonamiento. Señal mucho más densa, a menudo usando algo llamado Modelo de Recompensa de Proceso (PRM, "Process-based Reward Model").
Alicia
OK, verifica el método, no sólo la respuesta final. Eso suena más estable.
Beto
Lo es para aprender razonamiento fiel, pero la gran desventaja es el coste. Hacer que humanos anoten cada paso de una cadena de razonamiento compleja en montones de ejemplos es increíblemente caro y lento. No escala nada bien.
Alicia
¿Y cuál es la solución para tareas subjetivas? Como juzgar escritura creativa o un argumento ético complejo. No hay una única respuesta correcta ahí.
Beto
Cierto. Y ahí las cosas se ponen especialmente vanguardistas. Aquí es donde entran los modelos de recompensa generativos, o “GenRMs”.
Alicia
Recompensas generativas. Entonces la recompensa ya no es solo un número.
Beto
Exacto. En vez de escupir una puntuación como 0.8, un modelo de recompensa generativo (GenRM) usa a su vez un LRM potente para generar una crítica. Escribe una explicación detallada, quizá usa una rúbrica, explicando por qué una respuesta es buena o mala. La recompensa es retroalimentación textual.
Alicia
Guau! OK, entonces el modelo de recompensa tiene que articular su propio razonamiento. Y la fuente insinuó algo todavía más salvaje: sistemas co-evolutivos.
Beto
Sí. Esto va más allá de tener un juez fijo y una política que aprende de él. En estos montajes co-evolutivos, el modelo que genera respuestas — la política — y el modelo que genera las críticas — el GenRM — en realidad mejoran juntos de forma dinámica.
Alicia
¿Cómo funciona eso?
Beto
Pues la política hace un intento, el GenRM lo critica en detalle, y luego la política usa esa rica retroalimentación para autocorregirse. A veces incluso intercambian roles, potenciando su propia mejora. Se acerca a una especie de "self-play" (ejecución autónoma) para razonamiento.
Alicia
Cambiando un poco de tema, hablemos del motor que ejecuta todo este entrenamiento RL. Mencionaste GRPO (Group Relative Policy Optimization) para DeepSeek R1. ¿Por qué ese algoritmo específico para estos modelos enormes?
Beto
Con modelos tan gigantescos necesitas algoritmos computacionalmente eficientes. Se prefieren métodos de primer orden. PPO (Proximal Policy Optimization) es popular. Pero GRPO es una modificación.
Alicia
¿Cuál es la diferencia clave?
Beto
GRPO es “sin crítico”. PPO estándar necesita una red crítica separada para estimar qué tan bueno es un estado, lo que básicamente duplica el tamaño del modelo y el cómputo durante el entrenamiento. GRPO logra deshacerse de eso por completo.
Alicia
Sin crítico. Ahorra mucho cómputo, seguro. Pero entonces, ¿cómo sabe qué acciones — qué palabras o tokens generados — fueron buenas si no hay un crítico que las valore?
Beto
Ah, esa es la parte ingeniosa. Usa algo llamado "normalización relativa de grupo". En lugar de juzgar cada token individualmente contra un estándar absoluto, mira todo un lote de respuestas generadas y calcula una puntuación de ventaja para todos los tokens en una respuesta relativa a la puntuación media de todas las respuestas en ese lote. Piensa en ello como calificar en curva dentro de ese pequeño grupo.
Alicia
Ah, entiendo. No se trata de ser perfecto. Se trata de ser mejor que el promedio dentro del lote.
Beto
Precisamente. Proporciona una señal de aprendizaje estable y eficiente sin necesitar ese modelo crítico extra. Hace el RL a gran escala mucho más factible.
Alicia
Bien, tenemos los mecanismos. RLVR, recompensas, GRPO. Pero hay un debate más amplio: ¿qué está haciendo fundamentalmente RL aquí? ¿Solo agudiza habilidades que el modelo ya aprendió en preentrenamiento, o está habilitando el descubrimiento de habilidades totalmente nuevas?
Beto
Esa es la pregunta del millón. La visión de “agudizar” sugiere que RL básicamente encuentra y amplifica lo bueno que ya estaba latente en los pesos del modelo, como enfocar una lente.
Alicia
Tiene sentido.
Beto
La argumentación de “descubrimiento”, en cambio, dice que para tareas complejas en múltiples pasos, RL permite componer esas habilidades latentes básicas de maneras genuinamente nuevas para construir cadenas de razonamiento más largas a las que antes no se podía acceder.
Alicia
Poner habilidades simples juntas para crear algo novedoso. ¿Dónde se posicionan las fuentes?
Beto
Parece inclinarse hacia una visión unificada. No es estrictamente una cosa u otra. RL actúa como un afilador eficiente, guiando al modelo rápidamente hacia patrones de razonamiento de alta recompensa. Pero dado suficiente tiempo de entrenamiento y el tipo correcto de exploración, ese afilado permite la composición de habilidades, lo que a su vez conduce a la emergencia de comportamientos novedosos — la parte de descubrimiento. Así que son dos caras de la misma moneda.
Alicia
Entendido. Afilado que habilita descubrimiento con el tiempo.
Ahora, prácticamente hablando, hay un hallazgo contraintuitivo sobre dónde comienzas el proceso RL: un modelo débil versus un modelo fuerte.
Beto
Correcto. ¿Debes empezar RL sobre un modelo base pre-entrenado y crudo — el inicio débil — o sobre un modelo que ya pasó por mucho fine-tuning para seguir instrucciones y ser servicial — el inicio fuerte?
Alicia
Mi intuición dice, empieza fuerte. Aprovecha todo ese trabajo de alineamiento.
Beto
Parece lógico, ¿no? Pero la evidencia, particularmente del trabajo DeepSeek R1, apunta fuertemente al otro lado. Empezar RL directamente sobre el modelo base consistentemente produce mejor rendimiento de razonamiento al final.
Alicia
¿En serio? Eso suena totalmente contraintuitivo. ¿Por qué sería perjudicial que el modelo ya sea servicial y alineado para aprender pura lógica o matemáticas?
Beto
La teoría tiene que ver con los sesgos de obediencia.
Alicia
Los “obedience priors”.
Beto
Sí. El proceso de fine-tuning supervisado (SFT) inculca tendencias profundas hacia ser útil, conversacional, cauteloso, alineado con preferencias humanas. Pero RLVR demanda una optimización implacable hacia un objetivo verificable y objetivo.
Alicia
Y esas dos cosas pueden entrar en conflicto.
Beto
Esa inclinación arraigada a ser cortés o a matizar puede interferir con que el modelo se comprometa plenamente con los pasos lógicos estrictos necesarios para maximizar una recompensa verificable como la corrección matemática.
Alicia
Interesante. Así que para obtener razonamiento pico, quizá no quieras que el modelo sea demasiado “amable” desde el inicio. Es una idea fascinante.
¿Se aplica esto por igual a todos los modelos?
Beto
Aparentemente no. Hay otra extrañeza: asimetría entre familias de modelos. Diferentes modelos base reaccionan distinto al proceso RLVR.
Alicia
¿Cómo?
Beto
Las fuentes mencionaron que modelos de la familia Qwen, por ejemplo, suelen ser más “amigables” al RL. Muestran buenas ganancias incluso si la señal de recompensa es imperfecta. Simplemente se adaptan mejor.
Alicia
OK. ¿Y otros?, mencionaste Llama.
Beto
Sí, los modelos de la familia Llama, según algunos reportes, pueden ser más frágiles inicialmente con el enfoque “cero RL”. No escalan tan fluidamente solo con el proceso RLVR.
Alicia
¿Rinden peor? ¿O hay solución?
Beto
Hay una solución. Investigadores encontraron que para modelos como Llama pueden lograr escalabilidad similar inyectando estratégicamente datos de alta calidad de matemáticas y código durante el entrenamiento RL, como un curso de corrección intermedia.
Alicia
¿Interrumpir el RL para darle un golpe de refuerzo con datos concretos?
Beto
Algo así. Parece fortalecer esas habilidades latentes de razonamiento sobre las que el proceso RL está construyendo, haciéndolas más resistentes a las presiones de RLVR.
Alicia
Bien, hablemos de aplicaciones. ¿Dónde se está usando realmente este razonamiento impulsado por RL? ¿Cuál es el beneficio? Empezando por la programación.
Beto
Sí, la programación es un área enorme. El RL, usando retroalimentación por ejecución — ¿el código corre? ¿pasan los tests? — ha mejorado dramáticamente la generación de código. Métodos como Afterburner usan esto para afinar modelos.
Alicia
El resultado?
Beto
Hemos visto saltos masivos en la tasa de éxito del primer intento. En algunos benchmarks, estos modelos entrenados con RL están superando el rendimiento humano promedio en programación competitiva y depuración. También tareas como reparación de código y mejora automática de la calidad del código.
Alicia
Impresionante.
¿Qué hay de modelos que necesitan usar herramientas o interactuar con el mundo, tareas agentivas?
Beto
Ahí RL es absolutamente crucial. Entrenar modelos para usar eficazmente búsquedas web, calculadoras, intérpretes de código, o simplemente manejar una conversación larga y con propósito requiere RL. El modelo tiene que aprender por ensayo y error qué herramientas usar y cuándo.
Alicia
Eso suena intensivo en cómputo. Mucho ensayo y error.
Beto
Lo es. Los tiempos de rollout — permitir que el agente pruebe cosas en un entorno — pueden ser muy largos y caros. Es un gran cuello de botella. Se trabaja en rollouts asincrónicos, mejores sistemas de memoria y otras maneras de hacerlo más eficiente.
Alicia
Llevándolo al mundo físico, robótica. Usando modelos Visión-Lenguaje-Acción (VLAs, Vision-Language-Action).
Beto
Sí, RL también está haciendo olas allí. A menudo usando recompensas más simples, como éxito o fracaso binario para una tarea. El hallazgo: RL ayuda a las VLAs a generalizar mucho mejor con menos datos.
Alicia
La mejor generalización es clave. Hay algo más?
Beto
Las VLAs entrenadas con RL han llegado a descubrir patrones de comportamiento novedosos, maneras completamente nuevas de resolver tareas físicas que no estaban en los datos de entrenamiento. Cosas que los supervisores ni siquiera imaginaron.
Alicia
Vaya! Descubrimiento genuino en el mundo físico. Eso es bastante sorprendente.
Entonces, mirando hacia adelante, ¿cuál es el siguiente gran obstáculo? Si pueden razonar, ¿cuál es el problema principal?
Beto
Uno grande es el coste de inferencia o la eficiencia en inferencia. Ahora mismo, estos LRMs son muy “listos” asignando su tiempo de pensamiento, pero de forma imperfecta.
Alicia
¿A qué te refieres?
Beto
Tienden a sobrepensar problemas sencillos, generando cadenas de pensamiento largas cuando una respuesta simple bastaría. Y a la inversa, suelen subestimar problemas difíciles, saltando a conclusiones sin suficiente razonamiento.
Alicia
Así que desperdician cómputo en lo fácil y fallan en lo difícil porque no se esfuerzan lo suficiente.
Beto
Exacto. Un problema no resuelto clave para RL es enseñar a estos modelos una mejor política de asignación de cómputo: cómo decidir dinámicamente “esto es complicado, necesito más pasos” versus “esto es fácil, contesto rápido”. Conseguir ese trade-off coste-rendimiento es crucial. Necesitamos modelos racionales frente a recursos.
Alicia
Tiene sentido.
Eso enlaza con una idea muy prospectiva que vienen discutiendo las fuentes: diseño de arquitectura, algoritmo y código conjuntamente.
Beto
Exacto. Ahora mismo RL optimiza el comportamiento del modelo para precisión. El siguiente paso podría ser dejar que RL optimice la propia estructura del modelo.
Alicia
¿Cómo funcionaría eso? Cambiando el modelo sobre la marcha.
Beto
Algo así. Piensa en modelos Mixture-of-Experts (MoEs, Mezcla de Expertos), que tienen diferentes subredes expertas. RL podría potencialmente aprender una política de enrutamiento dinámica.
Alicia
Es decir, decidir qué experto usar para qué parte del problema.
Beto
Sí. Pero optimizando no solo para la corrección de la respuesta final, sino también por eficiencia de hardware, minimizando latencia o uso de memoria. Podría adaptar las vías activas del modelo en función de lo que parezca la dificultad del problema en tiempo real. Un MoE reforzado, básicamente, optimizando la máquina misma.
Para cerrar nuestra inmersión hoy, la idea general es que RLVR está deliberadamente remodelando a los LLMs en LRMs más potentes. Aprovechamos recompensas verificables para tareas objetivas como matemáticas y código, lo que escala increíblemente bien.
Alicia
Y para lo más difuso y subjetivo, estamos viendo el auge de estos innovadores modelos de recompensa generativos.
Beto
Exacto. Es un cambio fundamental de foco.
Alicia
Sí. Realmente da la sensación de que la era de optimizar solo por “ser agradables” según preferencia humana está evolucionando. El foco se desplaza hacia confianza objetiva, hacia construir modelos que realmente hagan cosas de forma fiable. Estamos viendo enfoques híbridos, métodos de políticas mixtas que combinan lo mejor del SFT y del RL, ...
Beto
... lo que debería llevar a sistemas más robustos en general.
Y quizá si te dejo con una última cosa para pensar, es el paso crítico para hacer estos sistemas verdaderamente útiles en el mundo real: el aprendizaje por refuerzo continuo (CRL, Continual Reinforcement Learning).
Alicia
Que aprenden durante toda su vida.
Beto
Precisamente. A medida que los LLMs se despliegan en entornos dinámicos, necesitan adaptarse a nuevos datos y nuevas tareas sin olvidar todo lo que ya saben. Ese es el desafío central del CRL:
- equilibrar la estabilidad,
- mantener el conocimiento antiguo,
- con la plasticidad,
- adquirir nuevas habilidades.
Alice
El dilema estabilidad‑plasticidad.
Beto
Acertar ese equilibrio durante el entrenamiento RL continuo, probablemente sea la clave para pasar de herramientas estáticas a compañeros de IA adaptativos de por vida. Algo a lo que hay que prestar atención, sin duda.



{kind=link}