
Mientras que en EE.UU. las compañías grandes de Inteligencia Artificial (IA) están gastando miles de millones de dólares entrenando los grandes modelos de lenguage (LLMs), los chinos están diseñando arquitecturas más eficientes que se puedan entrenar en fracciones de esos costos. Hoy les traigo un artículo científico reciente que explica una de estas arquitecturas nuevas.
Enlace al artículo, en inglés, para aquellos interesados en profundizar en el tema: "Hierarchical Reasoning Models", por Guan Wang y colegas. Publicado el 4 de Agosto del 2025.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Bienvenidos de nuevo a un nuevo análisis profundo. Hoy vamos a poner, de verdad, los últimos cinco años de desarrollo en IA bajo un microscopio bastante intenso. Porque durante mucho tiempo la idea central, el dogma, ha sido bastante simple: "modelo más grande equivale a IA más inteligente".
Alicia
Esa ha sido la regla, sin duda. Si quieres mejor razonamiento, simplemente escalas más parámetros, más datos.
Beto
Y cuando esos modelos masivos necesitan “mostrar su trabajo”, escupen esos largos procesos de pensamiento paso a paso en forma de lenguaje; a eso todos lo llamamos cadena de pensamiento, o chain-of-thought (CoT).
Pero tenemos un conjunto de fuentes aquí que detallan un contraargumento realmente radical. Se llama modelo de razonamiento jerárquico, "Hierarchical Reasoning Model", o HRM.
Alicia
Y esto es pequeño.
Beto
Minúsculo. Hablamos de 27 millones de parámetros entrenados con quizá 1.000 ejemplos. Aun así, la afirmación es que consigue un rendimiento excepcional en tareas que dejan a esos modelos CoT de miles de millones de parámetros completamente bloqueados.
Alicia
Nuestra misión hoy es desempaquetar realmente esta arquitectura HRM.
Es radical no solo por su tamaño, sino porque el diseño está fundamentalmente inspirado biológicamente. Intenta eludir toda esa carrera armamentista de escala imitando el procesamiento jerárquico y a múltiples escalas temporales del cerebro humano.
Beto
Sugiere que si organizas la inteligencia correctamente, la escala en sí misma llega a ser casi secundaria.
Bien, vamos directo al grano.
Porque los investigadores no se contienen. Llaman a la cadena de pensamiento una muleta, no una solución satisfactoria. Pero si los LLM son tan impresionantes, ¿por qué aquí la CoT se ve como una debilidad en lugar de una fortaleza?
Alicia
Todo se reduce a la arquitectura y a un techo fundamental en su poder computacional. Los transformadores estándar de los LLM son, y esto es la paradoja, superficiales.
Beto
Superficiales. ¿Cómo puede un modelo con 100 capas ser superficial?
Alicia
Porque su profundidad es fija; por muchos bloques que apiles, ese número está fijado. Y esa estructura los coloca en clases de complejidad computacional muy limitadas, cosas como AC0 o TC04.
Beto
Vale, para los que tenemos algún texto de teoría en la estantería, ¿qué significa eso en la práctica?
Alicia
Significa que están diseñados para procesamiento altamente paralelo. Son increíbles en reconocimiento de patrones, en predecir la siguiente palabra. Pero están fundamentalmente bloqueados de realizar razonamientos algorítmicos complejos.
Beto
No pueden hacer ese pensamiento secuencial, iterativo y profundo que requiere la resolución real de problemas.
Alicia
Correcto. No pueden alcanzar la completitud de Turing, al menos no de forma extremo-a-extremo.
Beto
Un momento. Si la estructura es superficial, ¿cómo es posible que cuando le pregunto a un LLM un problema complejo de física me parezca que está pensando profundamente? ¿De dónde viene esa ilusión?
Alicia
Esa ilusión es así de poderosa. La cadena de pensamiento no es cómputo latente genuino. Es una estrategia para — y cito — "externalizar el razonamiento a nivel de tokens de lenguaje".
Beto
Ah, es como verse forzado a escribir cada paso de un problema matemático en un papel. En vez de resolver la mayor parte de forma eficiente “en la cabeza”.
Alicia
Exactamente eso. Estás descomponiendo un gran problema computacional en tokens lingüísticos frágiles, definidos por humanos. Y si el modelo falla en uno solo de esos tokens, toda la cadena se rompe. Todo se descarrila. Es ineficiente y necesita cantidades masivas de datos de entrenamiento para aprender esos patrones humanos de pasos. Y conduce a esas respuestas lentas, de alta latencia que a veces vemos.
Beto
Por eso la meta última siempre ha sido el razonamiento latente.
Alicia
Precisamente. Razonamiento LLM significa que el trabajo real, la búsqueda profunda, los pasos lógicos: todo ocurre de forma eficiente dentro del espacio latente del modelo, en su estado oculto.
Beto
Como cuando resolvemos un acertijo lógico.
Alicia
No estamos hablándonos paso a paso en voz alta; el razonamiento ocurre silenciosa y rápidamente en la actividad neural. Y el HRM está diseñado para alcanzar esa profundidad latente, para sortear el techo fijo del transformador.
Beto
Eso nos lleva al nuevo plano de diseño. Si la arquitectura transformadora es el problema, los investigadores del HRM miran a la naturaleza, a nuestras propias líneas, por una solución. El cerebro humano organiza la computación de forma jerárquica, con diferentes regiones operando a velocidades completamente distintas. ¿Cómo lo traducen a una arquitectura de IA?
Alicia
Básicamente, diseñaron un sistema con estructura de sistema uno y sistema dos directamente dentro de la red. El núcleo del HRM tiene dos módulos recurrentes interdependientes y cada uno corre a una velocidad diferente.
Beto
Los principales neurocientíficos lo llaman "separación temporal".
Alicia
De acuerdo. Piénsalo como una guía estratégica lenta emparejada con una ejecución táctica rápida.
Beto
Entonces, ¿cómo funcionan esos dos módulos juntos? ¿Quién planifica y quién hace?
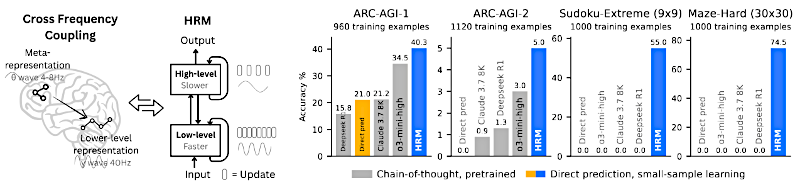
La arquitectura HRM.
Alicia
El planificador es el módulo de alto nivel, o "H" ("High"). Este es el pensador lento. Es responsable de la planificación abstracta, la estrategia global. Y, crucialmente, solo actualiza su estado interno una vez por cada ciclo del bajo nivel. Fija los grandes objetivos.
Beto
¿Y el motor que hace el trabajo pesado, los cálculos rápidos?
Alicia
Ese es el módulo de bajo nivel, o "L" ("Low"). Maneja todo el cómputo detallado y rápido. Ejecuta la búsqueda intensa y el refinamiento que se necesita para cada paso que el módulo H le encomienda.
Beto
Así que se actualiza muchas veces por cada actualización de alto nivel.
Alicia
Muchas veces. Esta estructura permite que el pensamiento de alto nivel guíe el trabajo detallado y, a su vez, que se vaya refinando iterativamente el propio estado interno con esa estrategia de evolución lenta.
Beto
La idea arquitectónica es fascinante. Pero también recuerda la debilidad clásica de las redes recurrentes, de las RNN: tienen dos problemas paralizantes. Gradientes que se desvanecen, lo que provoca que se estanquen; y los enormes costes de memoria de la retropropagación a través del tiempo ("BackPropagation Through Time", BPTT). ¿Cómo sortea el HRM esos viejos fantasmas?
Alicia
Y aquí están los avances técnicos que resultan verdaderamente impresionantes. Abordaron ambos problemas de frente.
Beto
Empecemos con el problema del estancamiento, con la convergencia. Si el modelo debe correr muchos pasos iterativos para simular un pensamiento profundo, ¿cómo evitar que simplemente se estabilice y se rinda?
Alicia
Lo resolvieron con algo que llaman "convergencia jerárquica". En una red recurrente normal, tienes razón: el estado se asienta, las actualizaciones se hacen más y más pequeñas y la red se atasca. El HRM está construido para movimiento dinámico. Piénsalo como resolver un cubo de Rubik.
Beto
OK, te sigo.
Alicia
El módulo de bajo nivel, el solucionador táctico, corre intensamente hasta encontrar una solución temporal, un equilibrio local. Digamos que resuelve una cara del cubo. Ese resultado se envía al módulo de alto nivel. El módulo H lo observa, actualiza su estrategia general y entonces reinicia el estado oculto del módulo L.
Beto
Ah, ese reinicio es la clave.
Alicia
Es crítico. Provoca toda una nueva fase de convergencia hacia otra solución, quizá resolver la siguiente cara. Así, este proceso dinámico de que el módulo L alcance un punto estable solo para ser “sacado” estratégicamente por H permite a la red mantener alta actividad computacional durante muchos, muchos pasos. Logra verdadera profundidad.
Beto
Así que, en vez de estancarse, la red es constantemente “sacudida” de vuelta al trabajo productivo por su propio planificador.
Alicia
Muy buena forma de decirlo.
Beto
Eso resuelve la profundidad. ¿Pero la memoria? Ejecutar cómputos durante cientos de pasos internos exigiría memoria O(T) en BPTT: crece con cada paso.
Alicia
Pero simplemente eliminaron la necesidad de almacenar todo ese historial. Usan una aproximación del gradiente de un solo paso, una idea inspirada en los "modelos de equilibrio profundo" ("Deep Equilibrium Models", o DEQ).
Beto
¿Cuál es la consecuencia práctica de pasar a una aproximación de un solo paso?
Alicia
La consecuencia es una revolución arquitectónica. La complejidad de memoria cae de O(T) hasta O(1).
Beto
Huella de memoria constante.
Alicia
Constante. No importa si el modelo toma 10 pasos internos o 10.000, el uso de memoria se mantiene igual.
Beto
Eso es una eficiencia masiva. Hacer práctico este tipo de pensamiento profundo e iterativo en hardware mucho más pequeño. Y, según recuerdo de las fuentes, dijeron que esta actualización O(1) es en realidad más biológicamente plausible.
Alicia
Lo es. El cerebro no tiene un mecanismo para mantener una historia perfecta cuadro por cuadro de cada disparo neuronal durante un largo proceso de pensamiento. Esta aproximación de gradiente de un solo paso solo necesita retroalimentación local, lo que encaja mucho mejor con lo que sabemos sobre cómo aprenden las neuronas.
Beto
También hicieron que el modelo fuera inteligente sobre cuándo dejar de pensar. El tiempo de ejecución no está fijado.
Alicia
Exacto. Incorporaron tiempo computacional adaptativo ("Adaptive Computational Time", ACT). Esto es otra clave de su eficiencia. Igual que nosotros variamos entre el pensamiento rápido y automático del sistema uno y el pensamiento lento y deliberado del sistema dos, el HRM usa una forma de aprendizaje por refuerzo, Q-learning, para decidir dinámicamente cuántos pasos computacionales necesita realmente para un problema dado.
Beto
Así que solo gasta sus costosos recursos de pensamiento profundo cuando un problema realmente lo exige.
Alicia
Esa es la idea. Las fuentes dicen que ACT permite ahorros computacionales significativos con impacto mínimo en el rendimiento. Si un laberinto simple puede resolverse en cinco pasos internos, se detiene. Si un Sudoku extremo necesita 50, los toma. Es una inteligencia consciente de sus propios recursos.
Beto
Bien. Tenemos un modelo pequeño inspirado en el cerebro, convergencia inteligente, memoria constante, tiempo de ejecución adaptativo. Vamos a los resultados. ¿Qué pasa cuando enfrentas este modelo de 27 millones de parámetros contra los gigantes de miles de millones?
Alicia
Las cifras de rendimiento no son solo algo mejores: muestran una diferencia cualitativa fundamental en lo que el modelo puede hacer. La comparación es asombrosa, sobre todo en tareas que requieren búsqueda profunda y retroceso sistemático, que es exactamente donde los modelos de profundidad fija tocan pared.
Beto
Danos las cifras. Empieza con Sudoku extremo, los rompecabezas 9x9.
Alicia
Esto es un benchmark muy duro. Estos puzzles están diseñados para requerir una búsqueda sofisticada, mucho backtracking: un promedio de 22 retrocesos por puzzle para un buen solucionador.
Beto
Y HRM.
Alicia
HRM alcanzó casi precisión perfecta en uno de los subconjuntos más difíciles: 74.5%.
Beto
74.5% frente a los modelos CoT de la competencia. ¿Qué sacaron los modelos CoT?
Alicia
Los modelos CoT de última generación, que tienen que escribir su lógica token por token, fracasaron por completo.
Beto
¿Qué significa?
Alicia
0% de precisión.
Beto
¿En serio 0%?
Alicia
0. Simplemente no pueden sostener ese tipo de búsqueda secuencial profunda sin cometer un error y descarrilar todo el proceso.
Beto
Así que casi 75% versus literalmente 0. Eso no es una brecha de rendimiento: es un abismo. Es otro tipo de inteligencia en acción.
¿Y en una tarea no tipo rompecabezas?
Alicia
Mira la tarea difícil de navegación de laberinto, una cuadrícula de 30x30. Se trata de encontrar el camino óptimo. HRM consiguió casi precisión perfecta aquí también.
Beto
¿La comparación?
Alicia
Un transformador LLM incluso mucho más grande, con 175 millones de parámetros, apenas tuvo éxito: su precisión quedó muy por debajo del 20%. La arquitectura es simplemente errónea para el razonamiento secuencial espacial.
Beto
¿Y el gran desafío? El ARC-AGI, que es la referencia para probar la generalización.
Alicia
En ARC-AGI, HRM, nuevamente entrenado con datos mínimos, obtuvo 40.3%. Esto supera sustancialmente a modelos CoT mucho más grandes. Claude 3.7, por ejemplo, sacó 21.2%. Otro gran modelo obtuvo 34.5%. El modelo más pequeño y mejor organizado es, francamente, mejor resolviendo problemas novedosos.
Beto
Lo más fascinante es lo que vieron los investigadores al asomarse dentro y analizar sus pasos intermedios. No solo usó un algoritmo para todo: adaptó su estilo de pensamiento al problema, ¿no es así?
Alicia
Sí. Para Sudoku, que va de decisiones muy constriñidas, lo vieron adoptar una clásica estrategia de búsqueda en profundidad (depth-first search) con su correspondiente backtracking.
Pero para la tarea de laberinto, que es sobre exploración espacial, el modelo exploró múltiples caminos a la vez, lo que se parece más a una búsqueda en amplitud (breadth-first search). La propia arquitectura le dio la flexibilidad de usar estrategias computacionales fundamentalmente diferentes.
Beto
Y esa flexibilidad nos lleva al hallazgo final y quizá el más profundo de todo esto: el que refuerza la conexión biológica. Los investigadores buscaron una estructura emergente dentro de la red entrenada y usaron una medida llamada "razón de participación", o "Participation Ratio" (PR).
Alicia
Correcto. La razón de participación es una forma de medir la dimensionalidad efectiva de una representación.
Beto
Cuánto del “espacio mental” disponible de la red se está usando.
Alicia
Excelente forma de pensarlo.
Una PR más alta significa que la información está repartida en un subespacio más rico y complejo.
Beto
Y biológicamente, esto no es aleatorio.
Alicia
Para nada. Estudios del córtex de ratón muestran que la PR aumenta al moverse hacia arriba en la jerarquía de procesamiento: desde áreas sensoriales de bajo nivel hasta áreas asociativas de alto nivel. La planificación de alto nivel necesita un espacio más flexible y de mayor dimensionalidad para operar.
Beto
Entonces, la gran pregunta: ¿el HRM entrenado descubrió este principio biológico por sí solo?
Alicia
Sorprendentemente, sí. La estructura aprendida en el HRM entrenado casi reflejó perfectamente el patrón organizativo del cerebro.
Beto
¿Cómo?
Alicia
El módulo de ejecución de bajo nivel, ZL, se asentó en un subespacio más especializado y más constreñido con una PR de alrededor de 30. Pero el módulo de planificación estratégica de alto nivel, ZH, operó en un subespacio sustancialmente más rico, más grande, con una PR de casi 90.
Beto
Vaya. Así que el planificador de alto nivel opera en un espacio casi tres veces más complejo que el ejecutor de bajo nivel.
Alicia
La relación PR alto/bajo está en torno a 2.98. Los investigadores señalan que esto se aproxima mucho a la ratio que observan en el córtex de ratón, que está cerca de 2.25.
Beto
Así que el modelo no solo resolvió los problemas: repartió sus propios recursos en planificación abstracta y ejecución especializada siguiendo un principio organizativo fundamental que vemos en cerebros de mamíferos.
Alicia
Y esto no fue programado: fue una propiedad emergente del aprendizaje. Apareció solo tras el entrenamiento.
Beto
¿Cómo lo saben?
Alicia
Porque cuando analizaron un HRM idéntico con pesos aleatorios no entrenados, los valores de PR eran bajos y casi iguales para ambos módulos, ambos alrededor de 40. La jerarquía estructural había desaparecido.
Beto
Es una evidencia poderosa. Sugiere que la jerarquía no es solo una elección de diseño elegante, sino una condición necesaria para lograr esa cognición flexible de alto nivel.
Para terminar: ¿qué significa esto para el panorama de la IA?
HRM parece mostrar que podemos obtener razonamiento superior y eficiencia priorizando la estructura jerárquica y el procesamiento a múltiples escalas temporales, no solo la escala de parámetros.
Alicia
Sugiere que este marco es un paso prometedor hacia una máquina capaz de cómputo universal completo (completitud de Turing), no solo el autocompletado hipereficiente que los LLM fundamentalmente son. Le da la vuelta al argumento de la escala.
Beto
Lo que nos deja con una reflexión provocadora:
- si el HRM descubrió y aplicó autónomamente un principio organizativo biológico fundamental — esta jerarquía de dimensionalidad — solo para resolver problemas de forma eficiente, ¿sugiere eso que todos los sistemas inteligentes, biológicos o sintéticos, están estructuralmente constreñidos de formas similares?
- Y si el razonamiento profundo y complejo puede lograrse en un espacio latente con tan pocos ejemplos de entrenamiento, ¿qué dice eso sobre el foco abrumador que la comunidad de IA pone en el volumen de datos? Y sobre la herramienta frágil y cara del razonamiento explícito basado en lenguaje como la cadena de pensamiento.
Tal vez el futuro de la IA no sea hacerse más grande, sino construir cerebros más inteligentes y organizados de forma más eficiente.



{kind=link}