
Hoy les traigo el resumen de un artículo científico reciente que resalta algo novedoso en arquitectura de Modelos de Razonamiento de Inteligencia Artificial. Los investigadores de Samsung han logrado diseñar un modelo pequeño que razona de manera profunda usando recursión y dos capas de redes neuronales jerárquicas.
Enlace al artículo original, en inglés:
"Less is More: Recursive Reasoning with Tiny Networks", publicado el 6 de Octubre de 2025, por Alexia Jolicoeur-Martineau, de Samsung Montreal.
En el resumen también incluimos algunos enlaces, para aquellos que quieran profundizar en el tema.
El resumen, la transcripción y traducción de este artículo fueron hechos usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bueno, durante buena parte de la última década, la creencia central que ha impulsado la investigación en IA ha sido realmente la ley de escalado, ya sabes: dicho sencillamente, más grande es mejor.
Beto
Más parámetros, modelos más anchos.
Alicia
Exacto, pilas más profundas. Se supone que todo eso conduce a un mejor rendimiento, especialmente en esas tareas realmente difíciles de razonamiento de alto nivel.
Beto
Y esa ley ciertamente parece mantenerse en lo que es conocimiento general y fluidez del lenguaje, sin duda.
Pero hoy profundizamos en algunas fuentes que le lanzan una curva realmente fuerte a esa filosofía de “más es mejor”, un desafío poderoso y contraintuitivo.
Alicia
De verdad que lo hacen. Estamos hablando de un avance bastante importante centrado en esta nueva arquitectura llamada el Modelo de Recursión Diminuto o TRM (Tiny Recursion Model).
Beto
¿Preocupante, verdad?
Alicia
Y lo que sorprende es que este modelo diminuto no solo compite, sino que en realidad está superando a esos enormes LLMs e incluso a su propio predecesor más complejo en algunos rompecabezas serios de lógica y espacio.
Beto
Sí. Nuestra misión hoy es desentrañar toda esta idea de “menos es más”. Las fuentes que tenemos detallan cómo TRM logra, bueno, una generalización y una precisión superiores con una arquitectura ridículamente simplificada.
Alicia
“Ridículamente simplificada” es correcto.
Beto
En un conteo de parámetros que a menudo baja hasta, ¿qué?, siete millones; compáralo con los modelos de los que solemos hablar, cientos de miles de millones e incluso billones de parámetros. Es otro mundo.
Alicia
Y necesitamos con urgencia este tipo de eficiencia. Porque, enfrentémoslo, a pesar de sus increíbles habilidades de lenguaje, los LLMs luchan fundamentalmente con el razonamiento duro.
Beto
Lo hacen.
Alicia
Piénsalo: cuando un LLM genera una solución, digamos para un problema matemático complejo, lo hace auto-regresivamente, ¿verdad? Un token tras otro.
Beto
Sí, de forma secuencial. Y esa generación secuencial lo hace muy propenso a un efecto dominó: un pequeño error al principio, una vuelta equivocada, ...
Alicia
... y toda la solución de varios pasos se viene abajo.
Beto
Exacto. No pueden retroceder y corregirse con facilidad.
Alicia
Correcto. Y por eso el campo recurre a estos trucos costosos y a menudo complejos, cosas como la cadena de pensamiento (CoT, Chain of Thought).
Beto
Ajá. Donde el modelo se habla a sí mismo a través de los pasos esperando que sean correctos.
Alicia
O el cómputo en tiempo de prueba (Test-Time Compute, TTC), donde básicamente ejecutan el modelo una y otra vez y esperan que la respuesta más frecuente sea la correcta. Suena un poco a adivinanza.
Beto
Es lento. Es caro. Y en los benchmarks realmente difíciles, estas soluciones todavía no bastan. Hablamos de conjuntos de rompecabezas como "Sudoku Extreme", y "Maze Hard".
Sudoku-Extreme es un dataset nuevo que consiste en 3.8 millones de problemas de Sudoku difíciles de resolver, que requieren planificación a largo plazo.
Y Maze-Hard es un laberinto de 30x30 cuadros donde el objetivo es encontrar el camino óptimo.
Ejemplos:

Fuente: Hierarchical Reasoning Model, Guan Wang y colegas, publicado en Agosto 4 de 2025.
Alicia
Y esos rompecabezas ARC-AGI de razonamiento abstracto realmente difíciles.
ARC-AGI-2 consiste en un dataset de tareas de entrenamiento y evaluación, que usa rejillas con puntos de colores, con reglas de razonamiento y composición, fáciles para resolver por un ser humano, que no se pueden memorizar.

Fuente: "ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems", por François Chollet y colegas, publicado en Mayo 17 de 2025.
Beto
Sí, son asesinos. Las fuentes son claras. Incluso los LLMs de primer nivel no han alcanzado la precisión humana ahí todavía. Ni cerca, a veces.
Alicia
Solo para poner un número a esa tasa de fallo, las fuentes mencionaron a Gemini 2.5 Pro, un modelo supuestamente de última generación. Solo consiguió, ¿qué?, 4.9% de precisión en la prueba del nuevo benchmark ARC-AGI-2. Incluso usando mucho cómputo en tiempo de prueba.
Beto
4.9%.
Alicia
Eso es una tasa de fallo del 95%. Eso te dice todo lo que necesitas saber sobre por qué necesitamos un motor de razonamiento mejor y más fiable.
Beto
Precisamente.
Para entender cómo TRM logró esto, en realidad tenemos que mirar el modelo que vino justo antes: el Modelo de Razonamiento Jerárquico, o HRM (Hierarchical Reasoning Model). Este modelo fue en sí un gran avance, aunque seguía operando con un tamaño relativamente pequeño, 27 millones de parámetros en total.
Alicia
Todavía diminuto comparado con los gigantes de hoy, pero bueno.
Beto
HRM fue novedoso porque se centró en la profundidad mediante la recursión, no solo en la fuerza bruta.
Alicia
Exacto. Se apoyó en dos conceptos realmente clave. El primero fue la supervisión profunda.
Beto
Supervisión profunda. ¿Qué es eso?
Alicia
Esencialmente le da al modelo una especie de memoria perfecta y verificable de sus propios estados internos previos, sus propios “pensamientos”. En lugar de simplemente ejecutar hacia adelante una vez, el modelo reutiliza las características latentes, los datos internos del paso de procesamiento anterior, y los usa como punto de partida para el siguiente.
Beto
Ah, así que construye directamente sobre su trabajo anterior.
Alicia
Correcto. Le permite al modelo razonar recursivamente a lo largo de muchos pasos —probaron hasta 16— sin los enormes costos de memoria de construir físicamente una red de 16 capas.
Beto
Darle un bloc de notas interno que debe revisar antes de empezar el siguiente cálculo, ¿no?
Alicia
Es una gran analogía. Profundidad efectiva lograda recursivamente, no físicamente.
Beto
Tiene sentido. ¿Y el segundo concepto?
Alicia
El segundo fue el razonamiento jerárquico recursivo. Y aquí es donde HRM empezó a ponerse, bueno, un poco complicado.
Beto
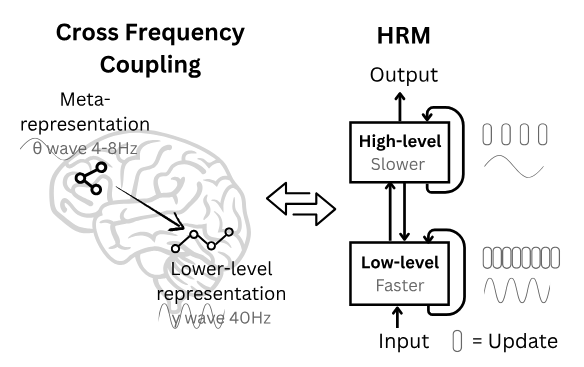
Usaba dos redes pequeñas separadas, de dos “niveles” o “bandas”. Estaban diseñadas para procesar información a diferentes “frecuencias conceptuales”, como una red de detalle de alta frecuencia y una red de contexto de baja frecuencia.
Alicia
Bien. ¿Dos redes? ¿Por qué?
Beto
Incluso fueron un paso más allá e intentaron justificar esta estructura con argumentos biológicos bastante complejos que sugerían que imitaba cómo los cerebros podrían manejar entradas sensoriales rápidas frente a una comprensión contextual más lenta.
Alicia
IA inspirada en la biología; ya hemos visto eso antes.
Pero espera, dijiste “complicado”. Entonces construyeron este sistema complejo de dos redes. ¿Cuál fue el problema? ¿Cuál fue el defecto?
Beto
El fallo estuvo realmente en la complejidad teórica y las suposiciones que tuvieron que hacer. Para lograr que esas dos redes funcionaran juntas de forma eficiente, HRM se apoyó fuertemente en matemáticas avanzadas, específicamente en algo llamado el teorema de la función implícita (Implicit Function Theorem, IFT).
Alicia
IFT. Vale. Vago recuerdo de cálculo, tal vez. ¿Qué asume aquí?
Beto
Básicamente asumía que este proceso recursivo paso tras paso eventualmente se estabilizaría, convergiendo a un punto fijo estable.
Alicia
¿Y por qué necesitaban esa suposición? ¿Qué les daba?
Beto
Porque si asumían que convergía, podían usar un atajo masivo durante el entrenamiento llamado la aproximación del gradiente de un paso (One-step Gradient Approximation).
Alicia
Un atajo. Vale.
Beto
Significaba que, cuando calculaban cómo actualizar el modelo, solo tenían que retropropagar la señal de error a través de los dos últimos pasos de la recursión en vez de quizá seis pasos totales en una pasada hacia adelante.
Alicia
Ah. Así que en lugar de calcular el error a través de los seis pasos, solo hacían los dos últimos, lo que ahorra muchísima memoria y cómputo, me imagino.
Beto
Una cantidad enorme.
Alicia
Pero dependía de que la suposición del punto fijo fuera cierta. Cambiaron el rigor teórico por ahorros prácticos, construyendo sobre una base potencialmente inestable.
Beto
Precisamente. Y las fuentes señalan que análisis independientes sugirieron que ese punto fijo rara vez, si es que alguna vez, se alcanzaba en la práctica.
Alicia
Oh. Así que toda la justificación teórica estaba tambaleante.
Beto
Muy tambaleante. Y, de forma algo irónica, estudios posteriores encontraron que la parte realmente complicada —la estructura recursiva inspirada biológicamente de dos frecuencias— ni siquiera era la razón principal de que funcionara bien.
Alicia
¿En serio?
Beto
Sí. El éxito vino casi enteramente del otro concepto: la supervisión profunda. Eso de la memoria autorreferencial que comentamos.
Alicia
Vaya. Así que toda esa complejidad extra —las dos redes, la justificación biológica— era básicamente lastre. Una lección enorme ahí.
Beto
Absolutamente. Pero la complejidad no se quedó solo en la teoría; también se filtró en el coste práctico de entrenamiento, ¿verdad?
Alicia
Lo hizo. HRM usó algo llamado tiempo computacional adaptativo (Adaptive Computational Time, ACT) para intentar ser más rápido.
Beto
ACT. Significa que el modelo podía aprender a detenerse temprano.
Alicia
Exacto. Aprendía a parar la recursión si pensaba que ya tenía la respuesta, típicamente gastando menos de dos pasos en promedio en lugar de ir los 16 pasos supervisados completos. Suena bien para la velocidad. Pero la forma en que implementaron ACT requirió un objetivo complejo de aprendizaje por refuerzo tipo Q-learning para decidir si detenerse o continuar.
Beto
Q-learning, ¿vale? Aprendizaje por refuerzo.
Alicia
Sí. Y ese cálculo de Q-learning necesitaba una pasada hacia adelante completamente separada por la red solo para averiguar el valor de "continuar o parar".
Beto
Espera, ¿dos pasadas hacia adelante por cada actualización de entrenamiento?
Alicia
Sí. Una pasada para la predicción real y una segunda pasada solo para la decisión de ACT. Efectivamente duplicaba el coste de cómputo por paso de optimización.
Beto
Duele! Así que HRM era teóricamente frágil y caro de entrenar. No ideal.
Alicia
Para nada.
Y esto prepara el terreno perfectamente para el Modelo de Recursión Diminuto, TRM. Porque TRM básicamente mira a HRM, ve esos fallos y consigue mejores resultados simplificando de forma implacable.
Beto
Aplicando la navaja de Occam.
Alicia
Totalmente. En vez de andarse con muletas teóricas y analogías biológicas, TRM es la prueba de que a veces la simplicidad es la jugada ganadora.
Beto
Entonces, ¿cuál fue la primera gran simplificación?
Alicia
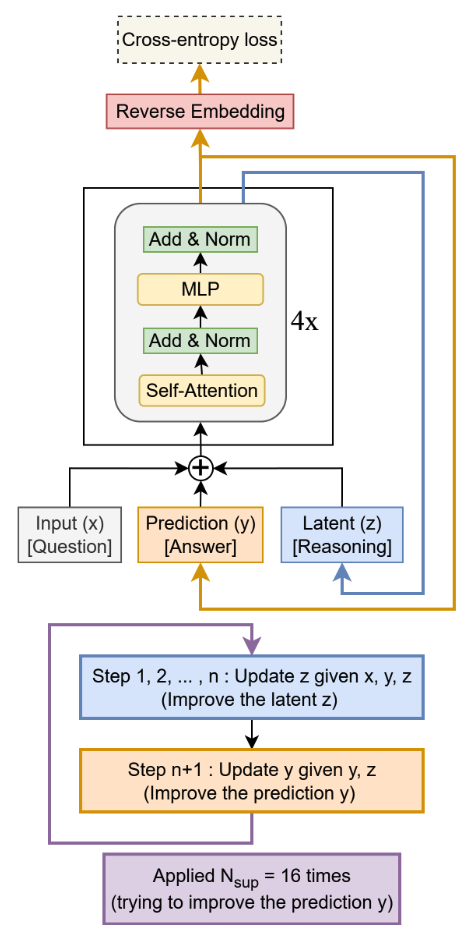
La red neuronal misma. TRM elimina completamente las dos redes de cuatro capas de HRM y las reemplaza con una única red de dos capas.
Beto
¿Dos capas? Vaya, eso es una reducción radical.
Alicia
Lo es. Reduce el recuento de parámetros de los 27 millones de HRM hasta apenas 7 millones, o incluso 5 millones en algunas versiones.
Beto
Espera, menos capas. ¿No perjudicó el rendimiento? Es decir, eso va en contra de todo lo que oímos sobre las leyes de escalado, la necesidad de profundidad.
Alicia
Ese es el núcleo de la idea “menos es más” aquí, y es muy importante. Porque los conjuntos de datos para estos rompecabezas realmente difíciles, como Sudoku-Extreme, solo tienen 1.000 ejemplos de entrenamiento. Son minúsculos. Con conjuntos de datos tan pequeños, si intentas entrenar una red grande y profunda, el modelo simplemente se sobreajusta. Memoriza las respuestas en lugar de aprender las reglas subyacentes.
Beto
Ya veo. Demasiada capacidad para la cantidad de datos.
Alicia
Exacto. Al usar solo dos capas, TRM restringe esa capacidad lo suficiente para forzar la generalización. Dos capas resultaron ser el punto óptimo; con más, el rendimiento bajaba por sobreajuste.
Beto
Es un resultado de escalado fascinante. No se trata solo de profundidad, sino de profundidad efectiva mediante recursión, equilibrada con el ancho físico justo para no morir de inanición de datos. Increíble.
Alicia
Totalmente.
Bien. La simplificación número dos: limpiaron cómo se pensaba sobre las características internas, lo latente.
Beto
Se deshicieron del argot confuso.
Alicia
Básicamente. Eliminaron la complicada etiqueta jerárquica basada en frecuencias. ¿Recuerdas lo de alta y baja frecuencia?
Beto
Sí, lo de alta y baja frecuencia.
Alicia
En TRM, lo antiguo que era “answer” ahora es simplemente la respuesta predicha; lo llamaremos "y". Y lo antiguo que era “scratch” es simplemente la característica latente de razonamiento, el proceso interno de pensamiento; lo llamaremos "z". Así de simple.
Beto
Entonces "y" para la respuesta, "z" para el razonamiento. Mucho más claro.
Alicia
Y esta clarificación conduce directamente al momento “ajá” sobre por qué realmente necesitas dos características, pero probablemente no más.
Beto
Bueno. ¿Por qué dos?
Alicia
Porque "y" es como la hoja de respuestas, y "z" es como el bloc de notas donde sucede el trabajo.
Beto
Tiene sentido.
Alicia
Si quitas "z", el bloc de notas, el modelo no tiene memoria de cómo llegó a la respuesta; solo tiene la respuesta en bruto y se olvida de los pasos, cometiendo más errores.
Beto
Bien. Y si quitas la hoja de respuestas, ...
Alicia
... entonces el modelo se ve forzado a intentar meter la solución final dentro del bloc de notas — tiene que almacenar la respuesta dentro de los pasos de razonamiento — lo que también empeora la precisión.
Beto
Entiendo. Así que necesitas roles distintos: un sitio para mantener la solución y otro para mantener la cadena de pensamiento. Simple y elegante.
Alicia
Exacto.
Ahora, la simplificación número tres quizá sea el mayor cambio de juego de toda la historia. TRM elimina por completo esa endeble aproximación teórica del IFT, la aproximación de gradiente de un paso que mencionamos antes.
Beto
Ese atajo teórico. Lo tiran. Simplemente lo quitan.
Alicia
Evitan todo el problema del punto fijo al no asumirlo. En lugar de confiar en ese atajo teórico que quizá sea falso, TRM retropropaga el error a través de todo el proceso recursivo. Todos los 16 pasos fijos en la pasada hacia adelante. Sin aproximaciones. Simplemente calculan el gradiente completo.
Beto
Vaya! OK. Así que abrazan el cómputo en vez de esconderse detrás de una teoría potencialmente defectuosa sobre ese cómputo.
Alicia
Me gusta eso. Y la mejora en rendimiento solo por este cambio fue asombrosa. La fuente señala que en Sudoku-Extreme, simplemente descartando esa aproximación y usando retropropagación completa, su precisión en test subió de 56.5% —que estaba bien pero no era gran cosa— a un increíble 87.4%.
Beto
Whoa. De mediados de los cincuenta a casi el 90% solo calculando bien el gradiente.
Alicia
Sí. Ese único cambio desbloqueó ganancias masivas. Simplemente, haz las matemáticas correctamente.
Beto
Increíble.
Beto
Y la simplificación final es el coste de entrenamiento.
Alicia
Obviamente. Simplificaron ACT, el tiempo computacional adaptativo: se deshicieron del objetivo complejo de Q-learning.
Beto
Eso significa que eliminaron esa segunda pasada hacia adelante tan cara.
Alicia
Exacto. Ya no más duplicar el cómputo por paso. Encontraron que podían simplemente aprender una probabilidad de detenerse usando la entropía cruzada binaria estándar, mucho más sencilla y barata.
Beto
¿Y esa simplificación perjudicó el rendimiento? Normalmente lo simple significa menos capaz.
Alicia
Aquí no. Mostró una precisión casi idéntica: 86.1% frente al 87.4% con la retropropagación completa, mientras hacía el entrenamiento significativamente más rápido y barato.
Beto
Así se realiza la eficiencia sin pérdida de rendimiento, ese el sueño.
Alicia
Eso es realmente.
Bien, miremos la tarjeta final. ¿Qué consiguió esta combinación —simplificación implacable, foco en la supervisión profunda, recursión honesta y completa— en términos de resultados?
Beto
Las comparaciones son bastante contundentes, especialmente dado el tamaño relativo entre TRM y los grandes LLMs. Es casi embarazoso para la filosofía estándar de escalado.
Alicia
El benchmark más duro, ARC-AGI-2.
Cuéntanos sobre el resultado.
Beto
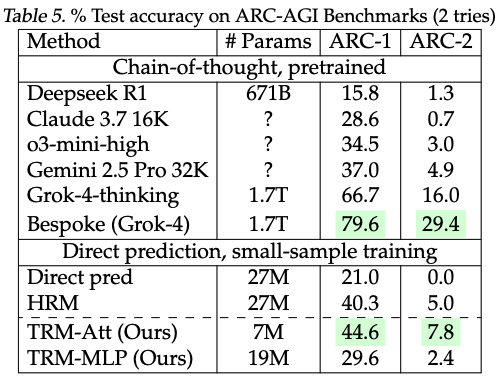
TRM con self-attention — y recuerda, esto tiene solo 7 millones de parámetros — consigue 7.8% de precisión. 7.8. Nosotros mencionamos que Gemini 2.5 Pro solo obtiene 4.9%.
Alicia
Mejor precisión con muchísimos menos parámetros. Muy por debajo en parámetros.
Beto
Con mucho menos. Y si comparas los 7 millones de parámetros de TRM con algo como, digamos, Grok-4-thinking, que supuestamente tiene 1.7 billones de parámetros, TRM opera con menos del 0.01% de los parámetros, menos de 1/110.000, y obtiene mejores resultados de razonamiento en ese benchmark.
Alicia
Eso es una locura. La eficiencia en parámetros está fuera de serie.
Beto
Completamente.
Y los resultados en los rompecabezas dedicados, Sudoku y Maze, son igual de dramáticos.
Alicia
Sí.
Beto
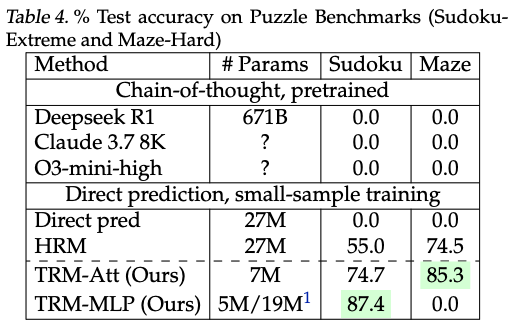
En Sudoku Extreme, la versión aún más pequeña de 5 millones de parámetros de TRM, la que no tiene self-attention, sube a ese 87.4% de precisión en test. Recuerda que HRM, el predecesor, estaba estancado en 55.0%.
Alicia
Un salto de "apenas aprobando", a "casi perfecto".
Beto
Y en Maze Hard, el TRM de 7 millones con atención consigue 85.3%, nuevamente muy por encima del HRM con 74.5%.
Alicia
Bien, esa diferencia es interesante. ¿Por qué atención para Maze pero no para Sudoku?
Beto
Eso conecta con la visión más amplia: la elección arquitectónica debe ajustarse al problema. La fuente destacó esto. La efectividad de TRM depende realmente de la estructura de la tarea.
Alicia
Así que la variante MLP más simple, sin self-attention, funciona mejor para contextos fijos y pequeños como una cuadrícula de Sudoku 9x9.
Beto
Exacto. Las relaciones entre celdas son bastante locales y predecibles. Pero para la gran complejidad y la naturaleza variable de las tareas ARC-AGI, o para cuadrículas más grandes como laberintos 30x30, ...
Alicia
... necesitas ese mecanismo de self-attention para que el modelo encuentre dinámicamente las dependencias a larga distancia importantes.
Beto
Precisamente. Muestra que puedes obtener resultados de vanguardia combinando estratégicamente componentes mínimos pero potentes — solo dos capas, una característica de memoria dedicada, quizá self-attention si hace falta — en vez de escalarlo todo sin discriminación.
Alicia
Bien, cerremos esto. ¿Qué significa todo esto para ti, el oyente?
Creo que la idea principal aquí es bastante profunda. El futuro del razonamiento fiable y de alto nivel en IA puede no estar en construir modelos cada vez más anchos con trillones más de parámetros. Podría estar en construir modelos recursivos más inteligentes que realmente adopten la profundidad efectiva.
Beto
Profundidad a través de la recursión, no solo capas.
Alicia
Exacto. Los elementos cruciales que TRM clavó parecen ser la supervisión profunda — esa memoria interna — y la recursión transparente y completa, calculando todo el proceso honestamente. Demuestra que una profundidad efectiva extrema, como las ~42 capas efectivas que consiguieron con solo dos capas físicas en TRM, puede ser mucho más potente que la mera amplitud masiva, especialmente cuando los datos de entrenamiento son limitados, que a menudo lo son para razonamiento complejo.
Beto
Lo cual plantea una gran pregunta sobre lo que viene después, ¿no?
Alicia
Sí que la plantea.
Beto
Ahora mismo, estos modelos de razonamiento recursivo, TRM y HRM, son métodos de aprendizaje supervisado, ¿cierto? Están entrenados para encontrar una única respuesta determinista.
Alicia
Encuentra la solución del Sudoku; encuentra el camino por el laberinto.
Beto
Correcto. Pero muchos problemas del mundo real, quizá la mayoría de los interesantes, no tienen una única respuesta correcta. Pueden tener múltiples soluciones válidas o requerir salidas abiertas y creativas, ...
Alicia
... como generar diferentes estrategias o escribir distintas explicaciones.
Beto
Exacto. El siguiente paso importante para los investigadores es averiguar cómo tomar esta arquitectura recursiva increíblemente eficiente y poderosa que TRM ha pionero y extenderla con éxito a tareas generativas.
¿Cómo lograr que ese razonamiento recursivo riguroso produzca salidas diversas, creativas, pero aún lógicamente sólidas? Esa parece ser la próxima frontera.



{kind=link}