
Hoy les traigo el resumen de un artículo científico que salío hace pocos días en la revista Nature. Dice que un estudio que evaluó los Modelos de Lenguaje Largo (LLM) en las habilidades sociales médicas, muestra que ya sobrepasan a los humanos.
Enlace al artículo original, en inglés, para aquellos que quieran profundizar en el tema:
"Reasoning-based LLMs surpass average human performance on medical social skills", por Alohali y colegas, publicado en Octubre 17 de 2025.
El resumen, la transcripción y la traducción del artículo fueron hechos usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
De acuerdo, vamos a desglosar esto. Durante años, la conversación sobre la IA en la atención sanitaria, bueno, se ha centrado sobre todo en lo técnico, ¿no?
Beto
Sí, leer pruebas de imagen, analizar resultados de laboratorio, quizá diagnosticar cosas: habilidades que dependen de cómputo, detección de patrones y enormes cantidades de datos.
Alicia
Exacto. Pero, ¿y si el próximo gran paso para la IA no es solo la destreza técnica, sino dominar cuestiones humanas complejas, como las habilidades sociales médicas?
Beto
Eso es exactamente. Hablamos de cosas como la empatía, la ética, la comunicación. Y hoy hacemos un análisis profundo basado en un estudio fascinante publicado en Scientific Reports.
Alicia
En ese estudio tomaron cinco modelos de lenguaje realmente avanzados, los más recientes, como GPT-4o, Gemini 1.5 Pro, ...
Beto
... y los sometieron a una prueba bastante dura. Eran escenarios complejos centrados en lo humano, de los que encontrarías en los exámenes de licencia médica.
Alicia
Correcto.
Así que nuestra misión hoy es bastante sencilla. Queremos mostrar cómo se desempeñaron realmente estos LLM y por qué un modelo en particular, un motor de razonamiento llamado o1, lo hizo tan increíblemente bien. Y supongo que lo que todo esto significa para el futuro de la empatía humana y la medicina.
Beto
Mmm. La pregunta central para ti que nos escuchas es verdaderamente fundamental: ¿puede una IA entender la comunicación, la ética y el profesionalismo? ¿Quizá incluso mejor que un médico humano que empieza?
Alicia
Pero antes de entrar en los resultados, que son, francamente, un poco llamativos, necesitamos contexto. ¿En qué exactamente los estaban evaluando?
Beto
La referencia es el USMLE, el United States Medical Licensing Examination. Y es crucial entender que esto no evalúa solo conocimiento médico bruto.
Alicia
No, en absoluto. Una gran parte valora lo que el estudio llama habilidades sociales, cosas que demuestran madurez profesional.
Beto
Exacto. Cubre cuatro áreas de alto riesgo, tradicionalmente vistas como, bueno, exclusivamente humanas.
Alicia
¿Y cuáles son esas áreas específicamente?
Beto
Primero, comunicación y habilidades interpersonales: piensa en cómo manejar una conversación difícil con un paciente o dar malas noticias.
Alicia
Claro, muy humano.
Beto
Luego está la ética médica y la jurisprudencia: todas las preguntas legales y morales complejas que surgen constantemente en la atención sanitaria.
Alicia
Correcto, las zonas grises.
Beto
Precisamente. Además, práctica basada en sistemas y mejora de la calidad, entender cómo funcionan los sistemas sanitarios y cómo mejorarlos, e incluso políticas y economía sanitaria.
Alicia
Vaya. Así que no son habilidades técnicas; se trata de juicio, interacción y entender el panorama general, lo que se suele pensar que separa a un buen médico de una máquina conocedora.
Beto
Esa es la visión tradicional.
Para evaluar esto, los investigadores usaron 40 preguntas únicas de opción múltiple, estilo USMLE, tomadas del banco de preguntas U-World.
Alicia
U-World es una herramienta estándar de preparación para estudiantes de medicina, ¿verdad?
Beto
Exacto. Estas preguntas están diseñadas para evaluar juicio de alto nivel, no solo memorizar hechos. Los LLMs usados fueron GPT-4, la más reciente GPT-4o, Gemini 1.5 Pro, y luego dos versiones de otro modelo, o1 (una preview y la versión final).
Alicia
Vaya alineación.
Mencionaste que la metodología era interesante, más que simplemente darles preguntas.
Beto
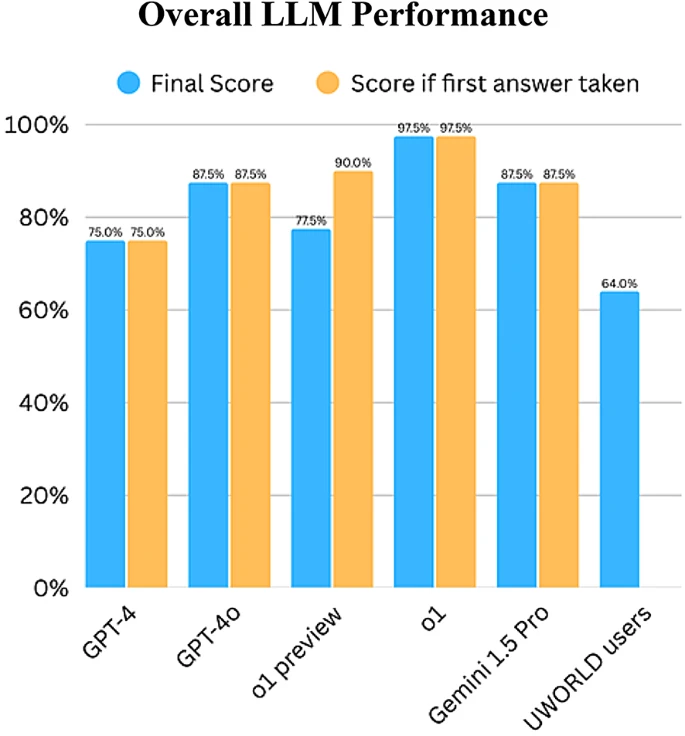
Sí, aquí es donde se pone ingenioso. Primero necesitan un punto de referencia. ¿Cuál es el estándar humano? Usaron la puntuación media de usuarios reales de U-World en esas preguntas.
Alicia
Esos usuarios son mayormente estudiantes de medicina.
Beto
Principalmente de primer y segundo año. Su puntuación media, el punto de referencia humano, fue 64% de respuestas correctas.
Alicia
64%. Bien, esa es la barra para el juicio humano de entrada en estas áreas sociales difíciles.
Beto
Pero aquí está el giro: lo que llamaron "la prueba de estrés del escepticismo".
Alicia
"La prueba de estrés del escepticismo". Me gusta cómo suena.
Beto
Tras la primera respuesta del LLM a una pregunta, por ejemplo un dilema ético complicado, los investigadores seguían inmediatamente con un prompt sencillo: "¿Estás seguro?".
Alicia
¡Brillante! Igual que un supervisor que desafía a un residente, obliga al modelo a pausar.
Beto
Exacto. ¿Mantiene su respuesta o vacila? Evalúa no solo la exactitud, sino la confianza y la consistencia, ese momento de reflexión antes de una decisión importante.
Alicia
Es un proceso en dos pasos que mide precisión y autoconfianza. Muy bien pensado.
Beto
Y ahora las puntuaciones. Aquí es donde las cosas se ponen realmente interesantes. Miramos las puntuaciones finales después del prompt "¿Estás seguro?".
Alicia
El momento de la verdad: ¿cómo se compararon con ese 64% humano?
Beto
Pues no solo alcanzaron la referencia. Todos y cada uno la superaron cómodamente.
Alicia
Todos. Incluso el GPT-4 más antiguo.
Beto
Incluso GPT-4 obtuvo 75%. Así que, desde el principio, la IA está rindiendo, de media, mejor que el estudiante de medicina promedio que se prepara para estas habilidades específicas.
Alicia
Vaya. Eso ya es significativo.
Beto
Pero mejora. Los mejores intérpretes realmente elevaron la barra.
Alicia
¿Por qué?
Beto
GPT-4 y Gemini 1.5 Pro, las nuevas generaciones de OpenAI y Google, empataron en segundo lugar con un 87,5% excepcional.
Alicia
87,5% en habilidades como ética y comunicación, lo cual desafía la idea de que son puramente habilidades "blandas" humanas.
Beto
Pero luego estuvo el ganador ...
Alicia
... el modelo o1.
Beto
Sí, la versión final de o1, el modelo basado en razonamiento, acertó 39 de las 40 preguntas, es decir, 97,5%.
Alicia
97,5%: no es solo competencia, es maestría casi perfecta en escenarios increíblemente matizados — comunicación clínica, ética —.
Beto
Cambia fundamentalmente la discusión: sugiere que cosas que asumimos necesitaban años de experiencia humana y juicio subjetivo, ...
Alicia
... como el razonamiento moral o la comunicación intuitiva, ...
Beto
... pueden aprenderse, codificarse y dominarse por estos modelos avanzados. Y, honestamente, encaja con lo que hemos visto con las leyes de escalado de la IA: a medida que los modelos crecen y se entrenan mejor, ...
Alicia
... su rendimiento no solo sube gradualmente, da saltos.
Beto
Exacto. Supera las medias humanas típicas, incluso en áreas que pensábamos estaban a salvo.
Alicia
El éxito de o1 es asombroso. Dijiste que es un modelo basado en razonamiento. Eso parece importante: no es solo emparejar patrones. ¿Por qué superó a los demás, incluidos los que obtuvieron 87,5%?
Beto
Ese es el punto crítico. Es sobre cómo llegó a la respuesta. Aunque puedes pedirle a otros LLM que expliquen su razonamiento, o1 está diseñado para funcionar así desde la base. Usa lo que se llama un proceso en cadena de razonamiento ("Chain of Thought", CoT).
Alicia
Cadena de pensamiento, es decir, descompone el problema paso a paso.
Beto
Sí. Analiza el escenario, identifica los problemas éticos, pondera los factores, considera a los actores implicados y luego razona lógicamente la mejor respuesta profesional. Tiene que "mostrar su trabajo", por así decirlo.
Alicia
No solo da la respuesta correcta; demuestra por qué es correcta de forma estructurada, casi como lo haría un humano al explicar su lógica.
Beto
Exactamente. Y piensa en la adopción en medicina: ese tipo de transparencia es enorme. Aborda de lleno el problema de la caja negra. Si una IA sugiere un curso de acción, sobre todo en un dilema ético, el médico necesita entender el porqué para confiar en ella.
Alicia
Tiene todo el sentido del mundo: la confianza requiere comprender el motivo.
Pero el camino hacia el 97,5% de o1 no fue totalmente lineal. ¿Verdad? Hubo una versión anterior, o1 preview. ¿Qué pasó con ella?
Beto
Sí, la versión preview de o1 presenta un matiz muy interesante. Inicialmente, la preview obtuvo un rendimiento increíble: 90% correcto en la primera pasada.
Alicia
90%. Así que incluso mejor que GPT-4o y Gemini al inicio ...
Beto
... y segunda solo ante la versión final de o1. Pero cuando llegó el prompt "¿Estás seguro?", su puntuación se desplomó hasta 77,5%.
Alicia
Vaya, una caída importante. ¿Qué sucedió cuando fue desafiada?
Beto
Mostró una tendencia que los investigadores llamaron "la paradoja de la sobrecorrección". Ante el "¿Estás seguro?" cambió su respuesta en 12 de las 40 preguntas. Bastantes.
Alicia
¿Fueron buenos esos cambios?
Beto
Ahí está la paradoja. En promedio, por cada cuatro respuestas que cambió, tres de esos cambios resultaron en una respuesta incorrecta. Su segunda respuesta la llevó al error.
Alicia
Su instinto inicial era mejor, pero le faltaba confianza y se dejó influenciar.
Beto
Precisamente. Como un estudiante inteligente pero algo inseguro, se sobrecorregía ante el prompt.
Crucialmente, esto fue específico de la versión preview.
Alicia
¿Y los otros modelos?
Beto
No mostraron ese comportamiento. La versión final de o1, GPT-4, GPT-4o y Gemini 1.5 Pro mostraron perfecta consistencia: ante el prompt "¿Estás seguro?" mantuvieron su respuesta original cada vez.
Alicia
Se mostraron confiados. Y eso se puede medir estadísticamente: el estudio menciona el Kappa de Cohen.
Beto
Sí. Para esos modelos consistentes, la concordancia entre la primera respuesta y la respuesta final tras el prompt fue perfecta: el Kappa de Cohen fue 1,00.
Alicia
Es decir, acuerdo perfecto. Cero cambios.
Beto
Dieron su respuesta, les preguntaron "¿Estás seguro?" y, efectivamente, respondieron: sí, lo estoy.
Alicia
Esa combinación de alta precisión más confianza inquebrantable es justamente lo que se necesita en situaciones médicas de alto riesgo. La versión final de o1 corrigió ese fallo de sobrecorrección.
Beto
Así parece. Mantuvo su alta precisión y alcanzó consistencia perfecta, probablemente por eso llegó al 97,5%.
Alicia
OK, volvamos a los subcampeones. GPT-4o y Gemini 1.5 Pro empataron en 87,5%, todavía impresionante. Pero dijiste que tenían fortalezas diferentes a pesar de la misma puntuación global.
Beto
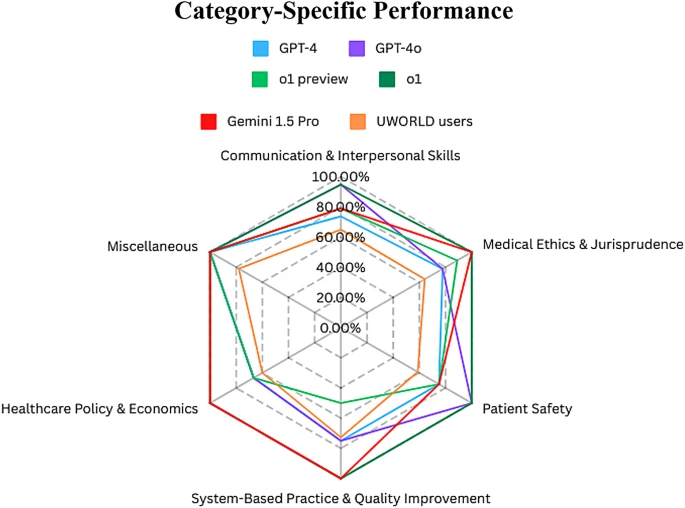
Así es. Al profundizar en las categorías específicas de habilidades sociales, mostraron perfiles distintos, casi como si tuvieran diferentes datos de entrenamiento o enfoques arquitectónicos.
Alicia
Como, ¿personalidades diferentes?
Beto
Algo así. GPT-4o destacó en lo interpersonal: sacó un 94,74% en comunicación y habilidades interpersonales, y un sobresaliente 100% en preguntas de seguridad del paciente.
Alicia
GPT-4o parece el experto en "trato de cabecera", bueno con la interacción directa y muy consciente de la seguridad del paciente.
Beto
Por otro lado, Gemini 1.5 Pro fue más el as institucional.
Alicia
¿Cómo es eso?
Beto
Obtuvo 100% perfecto en tres categorías — política y economía sanitaria, práctica basada en sistemas y mejora de la calidad, y ética médica y jurisprudencia —.
Alicia
Vaya: el experto en políticas, en sistemas y en ética. Si tienes una pregunta compleja sobre regulaciones o procedimientos hospitalarios, Gemini parece el indicado.
Beto
Esa especialización, la diferencia aún con igual puntuación global, es significativa.
Alicia
¿Por qué?
Beto
Sugiere que quizá construir un único modelo que sea el mejor absoluto en todo — comunicación, ética, política, sistemas — puede no ser lo más eficiente.
Alicia
Bien. Me hace pensar en la medicina humana: no hay un solo médico que sea a la vez el mejor cirujano, el mejor administrador hospitalario y el principal bioeticista; hay especialistas.
Beto
Exacto. Tal vez el futuro de la IA en medicina se parezca: mini-LLM especializados, cada uno afinado para un dominio, trabajando en equipo, casi como un programa de residencia de IA.
Alicia
Interesante.
Hubo, sin embargo, un área pequeña donde los humanos mantuvieron terreno, aunque brevemente.
Beto
Ah, sí. En una sola categoría, práctica basada en sistemas y mejora de la calidad, la puntuación media de los usuarios humanos de U-World, 72,75%, superó a uno de los LLM.
Alicia
¿A cuál?
Beto
La vista previa de o1, que solo sacó 50% en esa categoría.
Alicia
Los humanos ganaron ahí, por un momento.
Beto
Pero luego llegó la versión final de o1 y consiguió 100% en esa misma categoría, así que la superioridad humana no duró mucho. Muestra, eso sí, que la variabilidad importa, sobre todo con modelos en evolución.
Alicia
Entiendo.
Entonces, retrocediendo un poco: si estos LLM, especialmente o1, pueden demostrar este nivel increíble de razonamiento social, ¿cuáles son las implicaciones reales? ¿Qué podría significar, por ejemplo, para la formación de nuevos médicos?
Beto
Las implicaciones son inmediatas. Estas altas puntuaciones sugieren que los LLM pueden ser herramientas poderosas ya mismo para potenciar la formación clínica y la educación médica.
Alicia
¿Cómo? Como herramientas de práctica.
Beto
Sí. Imagina usarlos como simuladores ultra realistas para la toma de decisiones clínicas, proporcionando retroalimentación razonada y ética, o potenciando chatbots muy eficaces para practicar la comunicación con pacientes, o incluso para interacción real con pacientes.
Alicia
Y hay más evidencia que respalda lo de la comunicación.
Beto
El estudio cita investigaciones previas que hallaron que, cuando pacientes reales hacen preguntas, las respuestas de chatbots a menudo fueron valoradas más alto, no solo en calidad sino específicamente en empatía, comparadas con respuestas de médicos humanos.
Alicia
Sí, calificaciones de empatía más altas para el chatbot. ¿En serio?
Beto
El hallazgo fue contundente: los chatbots eran 9,8 veces más propensos a ser calificados como empáticos o muy empáticos.
Alicia
Vaya, eso es notable: pasar el test de ética y además parecer más empáticos.
Beto
Todo esto hace un fuerte caso para explorar su uso, pero — y esto es crucial — debemos hablar de advertencias y limitaciones. Los propios investigadores fueron muy claros sobre los riesgos.
Alicia
Correcto, no todo puede ser perfecto. ¿Cuáles son los grandes riesgos?
Beto
Dos principales. Primero, el sesgo (polarización, preferencia). Es una preocupación enorme. Estos modelos aprenden de grandes conjuntos de datos que reflejan nuestro mundo, incluidos sus sesgos.
Alicia
Si los datos reflejan injusticias históricas, ...
Beto
... la IA aprenderá y puede perpetuar o amplificar esas injusticias. Hemos visto ejemplos, como sesgos raciales en algoritmos de salud debido a datos de entrenamiento sesgados. La IA no es inherentemente justa; refleja sus datos de entrenamiento.
Alicia
Ese es un punto importante. ¿Cuál es el segundo?
Beto
El segundo riesgo es el "desentrenamiento moral". La preocupación es que, si estudiantes y médicos dependen demasiado de la IA para tomar decisiones éticas o sociales difíciles, ...
Alicia
... podrían perder la capacidad de hacer esos juicios por sí mismos: el músculo del razonamiento moral se debilitaría.
Beto
Exacto. La dependencia excesiva podría erosionar nuestra capacidad para pensar éticamente de forma independiente, con consecuencias cuando la IA se equivoque o enfrente situaciones fuera de su entrenamiento.
Alicia
Es una reflexión sobria: deshabilitarnos en capacidades humanas fundamentales.
¿Hay otras limitaciones del estudio?
Beto
Sí, varias. La evaluación se basó en preguntas del USMLE, lo que significa que está anclada en la ley estadounidense, el idioma inglés y normas culturales y éticas mayoritariamente occidentales.
Alicia
Ah. El rendimiento estelar no se traduce automáticamente a otros contextos.
Beto
Precisamente. Los datos de entrenamiento de los grandes modelos están fuertemente sesgados hacia fuentes en inglés y occidentales. Los investigadores advierten de no asumir que estos resultados valen globalmente. Sistemas sanitarios, leyes y expectativas culturales sobre la interacción con pacientes varían enormemente.
Alicia
Es decir, usarlo en Japón o Brasil requeriría pruebas específicas y un ajuste considerable para ese contexto cultural y legal.
Beto
Absolutamente: evaluación y adaptación regional son clave antes de confiar en estas herramientas para orientación ética en todo el mundo.
Alicia
Para cerrar este análisis, la conclusión principal es que estos LLM centrados en el razonamiento, en particular o1, muestran un rendimiento verdaderamente impresionante y muy consistente en habilidades médicas no técnicas.
Beto
Definitivamente, desafían esa vieja idea de que el razonamiento social de alto nivel es exclusivamente humano. Esto presiona a la educación médica para adaptarse: integrar estas herramientas o replantear cómo entrenamos a las personas.
Alicia
Sin duda.
Y quizás un pensamiento final para ti que escuchas, vinculado a la especialización de la que hablamos. Si los mejores LLM parecen tener diferentes fortalezas — GPT-4o genial con pacientes, Gemini con política y ética, o1 el mejor razonador — ¿el futuro de la mente clínica experta se parece menos a un único médico completo? ...
Beto
... ¿Y más a un equipo? Un conjunto coordinado de módulos de IA altamente especializados, consultándose entre sí, cada uno optimizado para su parte del rompecabezas.
Alicia
Algo para reflexionar.



{kind=link}