
El texto presentado presenta Engram, un novedoso módulo arquitectónico que integra memoria condicional en grandes modelos de lenguaje para mejorar la eficiencia y el razonamiento. A diferencia de los Transformers estándar, que utilizan cálculos costosos para reconstruir información estática, Engram utiliza tablas de búsqueda de N-gramas para recuperar conocimiento fijo en tiempo constante. La investigación revela una ley de escala en forma de U para la escasez, lo que sugiere que los modelos más efectivos equilibran el cálculo dinámico mediante Mezcla de Expertos (MoE) con la recuperación estática de Engram. Los resultados experimentales muestran que este enfoque híbrido mejora significativamente el rendimiento en razonamiento general, matemáticas y codificación, incluso manteniendo los mismos parámetros y presupuestos de cómputo. Mecanísticamente, Engram actúa como un "potenciador de profundidad" al descargar el procesamiento local de patrones en las primeras capas, lo que libera capacidad de atención para un contexto global complejo. Además, su recuperación determinista permite optimizaciones a nivel de sistema, como la descarga de tablas de memoria masivas para alojar DRAM con un impacto mínimo en la velocidad.
Enlace al artículo científico, para aquellos interesados en profundizar en el tema: "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models", por Xin Cheng y colegas. Publicado el 12 de Enero del 2026.
El resumen, la transcripción, y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Permíteme empezar con una pregunta rápida para ti. Cuando digo las palabras "New York City", ¿qué pasa en tu cerebro?
Alicia
Reconocimiento instantáneo. Simplemente está ahí.
Beto
Correcto. Obtienes el skyline, quizá un taxi amarillo, toda la vibra. Pero, ¿tienes que calcularlo? ¿Piensas “ok, New + York + City = …”?
Alicia
Absolutamente no. No lo derivas. Lo recuperas. Es una búsqueda, no un cálculo.
Beto
Exacto. Simplemente lo sabes. Pero aquí está lo que — y lo digo en serio — me dejó flipando mientras preparaba el análisis de hoy: los modelos grandes de lenguaje (LLMs), los transformers de los que hablamos todo el tiempo, no hacen eso realmente. No tienen una función nativa de consulta.
Alicia
Así es. Y probablemente es una de las mayores ineficiencias de toda la arquitectura. Es simplemente una laguna que más o menos hemos aceptado.
Beto
Entonces, para recordar un hecho simple, estos modelos gigantes tienen que pensar hasta llegar a la respuesta. Cada vez. Es como hacer una división larga para recordar tu propio número de teléfono.
Alicia
Lo cual es un desperdicio increíble de potencia computacional.
Beto
Y eso nos lleva al artículo que analizamos hoy. Se llama “Conditional Memory via Scalable Lookup” y es de investigadores de Peking University y DeepSeek AI.
Alicia
Tienes que leer el subtítulo. Es clave: “A new axis of sparsity for large language models”.
Beto
Un nuevo eje de sparsity ("escasez"). Suena muy, muy de ciencia ficción.
Alicia
Lo hace, pero la idea en realidad está bastante anclada. Proponen una nueva arquitectura. La llaman Engram. Y el objetivo es darle a la IA un enorme libro de referencia estático para básicamente separar la memoria de la computación.
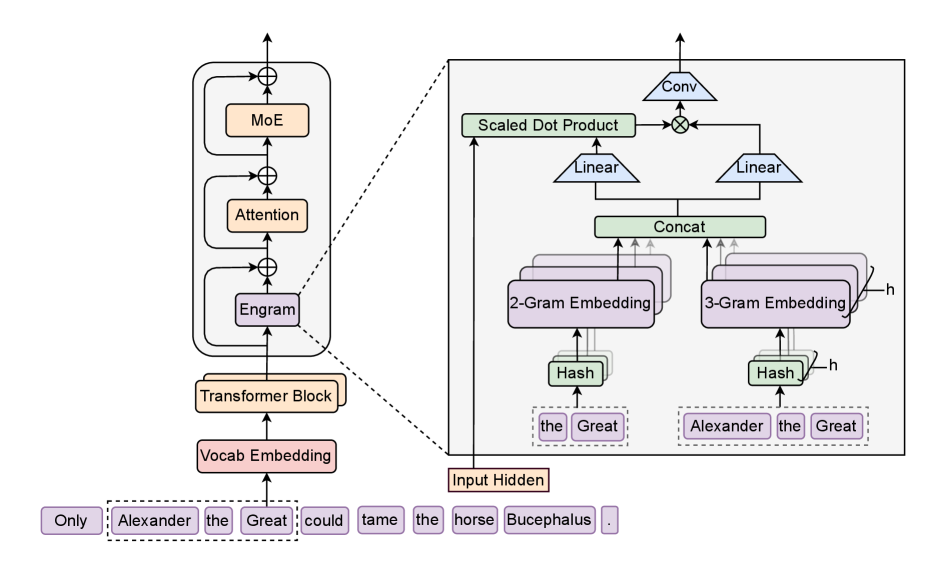
La Arquitectura Engram
Beto
Y lo que afirman es que esto no solo mejora al modelo en trivia, sino que en realidad lo hace más inteligente en razonamiento y en matemáticas.
Alicia
Lo cual es la parte sorprendente.
Beto
Esa es la parte que suena contraintuitiva. Piensas que una trampa barata solo ayuda con hechos, no con lógica. Darme un diccionario no significa que de pronto pueda hacer cálculo.
Alicia
Correcto. Para entender por qué funciona, tenemos que empezar con esta idea central que en el artículo llaman "dualidad lingüística".
Beto
OK, dualidad lingüística.
Alicia
Argumentan que el lenguaje no es una sola cosa. Está realmente compuesto por dos tipos muy diferentes de señales.
Beto
Desgranémoslas.
Alicia
Primero, tienes el razonamiento composicional. Esto es lo difícil, la lógica dinámica. Si te pido que analices un documento legal, tienes que pensar. Tienes que parsearlo. Tienes que sintetizar una respuesta.
Beto
Ese es el trabajo pesado, el verdadero pensar.
Alicia
Exacto.
Pero luego está la segunda parte: la recuperación de conocimiento. Todo lo estático: entidades nombradas como la "Estatua de la Libertad" o expresiones idiomáticas como “están lloviendo gatos y perros”.
Beto
Correcto. Cuando escucho eso, no empiezo a analizar la probabilidad de que animales caigan del cielo. Simplemente recupero el significado: "está lloviendo mucho".
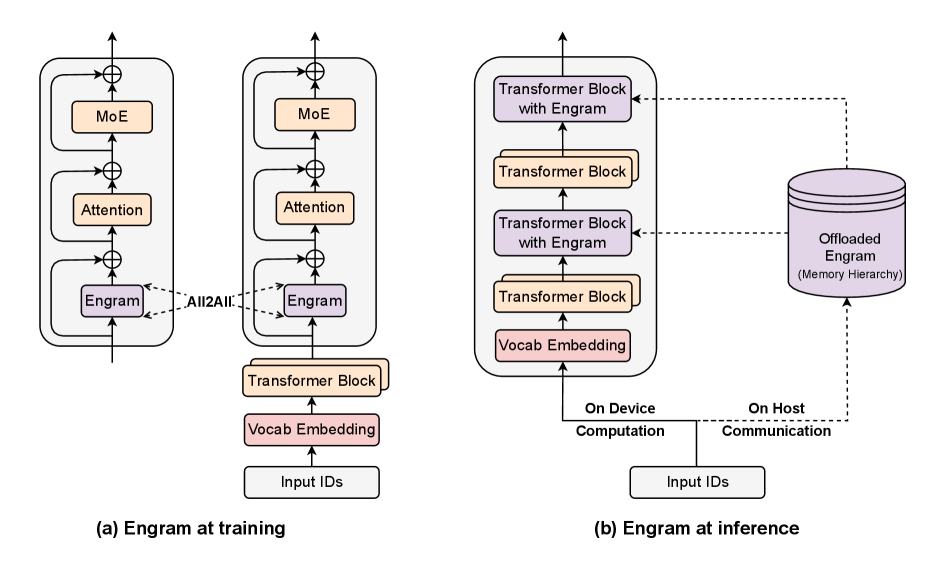
Implementacion de Engram: (a) Fase de Entrenamiento. (b) Fase de Inferencia.
Alicia
Precisamente. Es una definición prealmacenada. El problema es que los modelos actuales, tus GPT-4s, tus Claude, tratan ambas cosas exactamente igual.
Beto
Todo es un problema de razonamiento para ellos.
Alicia
Todo. Y el artículo usa este ejemplo perfecto: el problema “Diana Princess of Wales”.
Beto
Me encanta esta parte. Cuéntanos qué pasa dentro de una IA normal cuando ve ese nombre.
Alicia
OK, imagina que el modelo tiene, digamos, 40 capas. La frase “Diana Princess of Wales” entra. Las primeras capas solo ven las palabras crudas. Pueden deducir, OK, "Wales" es un lugar en el Reino Unido.
Beto
Está jugando a detective.
Alicia
La capa tres quizá diga, OK, "Princess" implica realeza en Europa. Y pasa hasta quizá la capa seis o siete antes de que el modelo finalmente lo junte todo y diga, "ah, esa figura histórica específica".
Beto
Así que acaba de gastar seis capas de su costoso y hambriento cerebro solo para recordar quién es alguien.
Alicia
Correcto. El artículo lo llama "un desperdicio de profundidad secuencial". Literalmente el modelo está reconstruyendo una tabla de consulta desde cero cada vez.
Beto
Eso es tremendamente ineficiente cuando lo pones así.
Alicia
Lo es. Y ahí es exactamente donde entra Engram.
Beto
Entonces, ¿cómo arregla Engram este problema Diana?
Alicia
Engram es un módulo especial diseñado solo para estos patrones estáticos. Y está basado en una idea muy clásica, el N-gram.
Beto
OK, ese es un término de la vieja escuela. Es como lingüística pre-chatGPT, ¿no?
Alicia
Muy de la vieja escuela. Un N-gram es simplemente una secuencia de N palabras. Así, un 2-gram es "New York". Un 3-gram es "Princess of Wales".
Beto
Así que están rescatando tecnología de los 90 para un modelo de IA de 2026.
Alicia
En cierto modo, sí, pero con un giro muy moderno: el módulo Engram es básicamente un enorme banco de memoria. Entonces, en lugar de procesar “Princess of Wales” a través de seis capas de operaciones, ...
Beto
... simplemente ve la frase ...
Alicia
... y no la calcula. Esencialmente hace clic derecho y pulsa “definir”.
Beto
Y toma un pequeño paquete precomputado de significado y lo inyecta en el proceso.
Alicia
Exacto. Reconocimiento instantáneo, sin trabajo detectivesco.
Beto
Y esta búsqueda es, ¿cuál era el término?
Alicia
O(1), tiempo constante. Significa que toma exactamente la misma cantidad de tiempo buscar “cat” que buscar “United Kingdom of Great Britain and Northern Ireland”. El tamaño de la biblioteca no lo ralentiza.
Beto
OK, veo el atractivo. Pero aquí es donde me pongo un poco escéptico. El lenguaje es desordenado. Es ambiguo. Si digo “apple”, ¿me refiero a la fruta o a la compañía? ¿Es Engram solo un diccionario tonto? ¿Cómo demonios sabe cuál quiero decir?
Alicia
Esa es la pregunta del millón. Y aquí está la parte moderna. No solo pegaron un diccionario al modelo. Construyeron un mecanismo de compuerta sensible al contexto.
Beto
Un portero.
Alicia
Precisamente. El módulo Engram encuentra una coincidencia y dice: eh, tengo una memoria para “apple”. Pero antes de que esa memoria entre, tiene que pasar una prueba. El modelo mira su estado oculto actual, en qué está pensando ahora mismo.
Beto
Si el modelo está escribiendo una receta de torta, ...
Alicia
... su estado oculto está lleno de contexto culinario. La compuerta hace un poco de matemáticas, un producto punto entre ese contexto y la memoria recuperada. Si la memoria es sobre fruta y el contexto es sobre torta, hacen match. La compuerta se abre.
Beto
Y si el contexto es sobre precios de acciones en el NASDAQ, ...
Alicia
... entonces el contexto y la memoria de fruta apuntan en direcciones totalmente diferentes. Las matemáticas no cuadran. La compuerta se cierra de golpe.
Beto
Es como el portero de un club: "No, no estás en la lista. Fuera."
Alicia
Es una analogía perfecta.
Y el artículo tiene esos mapas de calor que lo muestran. Para “Alexander the Great”, la compuerta está bien abierta, rojo brillante. Sabe que eso es algo específico. Pero para términos aleatorios intermedios, la compuerta se mantiene oscura. Filtra el ruido.
Beto
OK, así que tenemos un sistema que puede memorizar cosas y sabe cuándo usarlas. Pero siempre hay un compromiso. Los modelos Engram tienen un tamaño fijo, un presupuesto de parámetros, de células cerebrales. No puedes añadir esta memoria gratis. Así que tuvieron que tomar una decisión.
Alicia
Exacto. Esto es lo que llaman "el problema de asignación de escasez". Si tienes un presupuesto fijo de células cerebrales, ¿a cuántas asignas a los expertos? Las partes que hacen el razonamiento pesado.
Beto
¿Y a cuántas las asignas al Engram, a la memoria?
Alicia
Es como: ¿quieres un compañero de equipo que sea un genio que pueda resolver cualquier rompecabezas o un compañero que se haya memorizado toda la enciclopedia pero que no sea bueno en lógica?
Beto
Y la tendencia con los modelos tipo "mixture of experts" (MoE) ha sido apostar todo al genio. Casi 100% en los expertos.
Alicia
Pero este artículo dice que eso es subóptimo. Hicieron pruebas moviendo el presupuesto y encontraron una ley de escalado en forma de U.
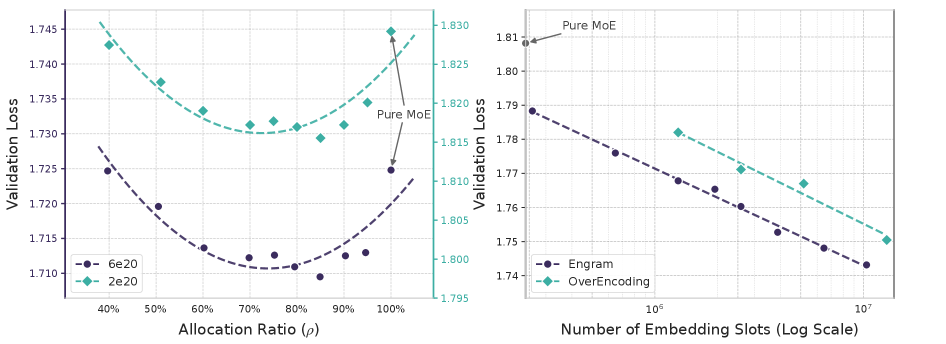
Asignación de escasez y escalamiento de engramas.
Beto
¿Una U? Así que hay un punto óptimo en el medio.
Alicia
Exacto.
- Todo expertos, mucha memoria desperdiciada: pierdes tiempo redescubriendo hechos.
- Todo memoria, sin expertos: tienes un loro que no puede pensar.
Beto
¿Cuál es el número mágico?
Alicia
Encontraron que el mejor rendimiento venía al reasignar alrededor del 20% al 25% de ese presupuesto de Sparcity hacia Engram.
Beto
Así que, ceder una cuarta parte del poder de pensamiento por memorizar, en realidad hace que todo el sistema sea más inteligente.
Alicia
Significativamente más inteligente. Y lo demostraron. Construyeron dos modelos de 27 mil millones de parámetros: un MoE 27b estándar y un nuevo Engram 27b.
Beto
Y tenían Iso-parámetros e Iso-FLOPS.
Alicia
Significa que costaban exactamente lo mismo entrenar y ejecutar, sin trampa.
Beto
OK.
Alicia
Y Engram 27b superó consistentemente la línea base. Pero aquí es donde se pone realmente raro. Y esta es la parte que, honestamente, me sorprendió. Esperarías que el modelo de memoria fuera mejor en trivia, ¿no?
Beto
Claro, capitales, fechas históricas, ese tipo de cosas.
Alicia
Y lo fue. MMLU, la gran prueba de conocimiento general, subió 3.4 puntos.
Beto
Bien. Eso es esperado. Compro un diccionario. Espero mejorar en ortografía.
Alicia
Pero las ganancias fueron mayores en razonamiento abstracto, en BIG-bench-hard (BBH), que trata de lógica compleja y de múltiples pasos. Subió 5.0 puntos.
Beto
Espera, espera. El modelo con diccionario mejoró en razonamiento más que el modelo puro de razonamiento.
Alicia
Sí. Y se pone más extraño. En tareas de programación, subió 3.0 puntos. En la prueba de matemáticas, subió 2.4 puntos.
Beto
¿Cómo? ¿Cómo ayuda una tabla de consulta para “Diana, Princess of Wales” a escribir código en Python o resolver un problema de cálculo? Eso no tiene sentido.
Alicia
Vuelve a la idea de "profundidad efectiva". Piensa en esas primeras seis capas que estaban ocupadas averiguando quién era Diana.
Beto
Correcto. Estaban distraídas.
Alicia
Totalmente ocupadas con trabajo de bajo nivel. Al descargar todo ese emparejamiento de patrones en Engram, que sucede al instante, esas capas quedan libres.
Beto
Así que la parte “cerebro” puede empezar a pensar en la lógica real del problema desde la capa 1, en vez de esperar hasta la capa 7.
Alicia
Exactamente.
Usaron una herramienta para mirar dentro de las capas del modelo. Encontraron que el modelo Engram alcanza un estado listo para predecir mucho, mucho antes en la red.
Beto
Así que no estás añadiendo capas; simplemente haces que las capas existentes sean más eficaces. Porque no tuviste que buscar la fórmula, tienes más potencia cerebral para realmente resolver la ecuación.
Alicia
Es la analogía perfecta. Su análisis mostró literalmente que la capa 5 en el modelo Engram estaba haciendo el mismo trabajo de calidad que la capa 12 en el modelo base. Es un atajo que permite que todo el sistema se concentre en lo difícil.
Beto
Fascinante. No se trata de saber más. Se trata de despejar el desorden mental para que puedas pensar.
Alicia
Y despejar ese desorden tiene otro gran beneficio: contexto largo.
Beto
Esta es la prueba “aguja en un pajar”, ¿no? Esconder un hecho en un documento enorme y ver si la IA puede encontrarlo.
Alicia
Sí. Normalmente, los documentos largos aplastan el mecanismo de atención de un modelo. Se pierde por el camino.
Beto
Pero Engram ayuda con esto.
Alicia
Es un cambio radical. Al delegar todo lo local, los nombres, las frases cortas, a la tabla de consulta, el mecanismo de atención queda liberado para concentrarse solo en el contexto global.
Beto
Así que no tiene que desperdiciar energía rastreando los pequeños detalles. Puede seguir la trama principal de la historia.
Alicia
Precisamente. Y los resultados son contundentes. El modelo estándar sacó 84.2 en la prueba. El modelo Engram, 97.0.
Beto
Un salto masivo. Es la diferencia entre un 7 y un 9, por decirlo de forma escolar.
Quiero cambiar de marcha hacia algo más técnico, pero creo que es muy importante para el futuro práctico de usar esto: el hardware.
Alicia
La parte de infraestructura, sí. Esto es una de las piezas más prácticas del artículo.
Beto
Todos sabemos que las GPUs son caras. Esa memoria rápida en ellas, la HPM, es el cuello de botella.
Alicia
Es superrápida, pero no obtienes mucha y cuesta una fortuna.
Beto
Pero la memoria normal del ordenador, la RAM, eso es barato y puedes tener montones.
Alicia
Pero es lenta, demasiado lenta para una IA normalmente. La GPU acaba esperando a que la RAM le entregue los datos.
Beto
Pero Engram tiene un truco.
Alicia
Sí. Recuerda que dijimos que la búsqueda es determinística.
Beto
Quiere decir que sabes qué necesitas consultar antes de tiempo.
Alicia
Lo sabes solo mirando el texto de entrada. No tienes que ejecutar la IA para saber qué buscar. Entonces, como lo sabes por adelantado, el sistema puede pre-cargarlo. Mientras la GPU está ocupada en la capa 5, la CPU ya está yendo a la RAM lenta y barata, agarrando la memoria Engram necesaria para la capa 6 y entregándosela a la GPU justo a tiempo.
Beto
Está enmascarando la latencia. Es como pedir una pizza una hora antes de que te dé hambre, para que llegue justo cuando quieres comer.
Alicia
Eso es, exactamente.
Desplazaron una tabla de 100 mil millones de parámetros a la RAM barata del host, y la pérdida de rendimiento fue menor al 3%.
Beto
100 mil millones de parámetros. Sentados en RAM barata. Eso es una locura. Eso significa que podríamos escalar la memoria de estos modelos casi indefinidamente sin necesitar más GPUs.
Alicia
Esa es la implicación. Nos estamos alejando de la idea de un cerebro gigante que lo hace todo y hacia partes especializadas. Tienes a los expertos para pensar — a costa de hardware — y tienes Engram para recordar en almacenamiento masivo barato.
Beto
Simplemente tiene sentido. La biología funciona un poco así. Tenemos diferentes sistemas de memoria.
Alicia
Y respetando esa distinción, esa dualidad, Engram hace que el modelo sea tanto más eficiente como paradójicamente más profundo.
Beto
Para resumir: las IAs han estado fingiendo su memoria haciendo cálculos. Engram les da una memoria real. Eso libera al cerebro para lo difícil, lo que los hace mejores en lógica y código. Les ayuda a leer documentos largos. Y funciona sobre hardware más barato.
Alicia
Esa es una suma perfecta. Trata la memoria como una primera clase separada de la computación pura.
Beto
Realmente da la sensación de que la arquitectura está madurando. Ya no es solo “hazlo más grande”. Es “hazlo más inteligente”. Hazlo más estructurado.
Alicia
La optimización estructural es absolutamente la siguiente frontera.
Beto
Quiero dejar a nuestros oyentes con un pensamiento final. Y me encantaría tu opinión sobre esto. Hablan de descargar 100 mil millones de parámetros. Pero la RAM es barata. Podríamos tener terabytes, petabytes de esta memoria estática.
Alicia
El techo es muy, muy alto. Técnicamente, sí, el límite es simplemente cuánto almacenamiento puedas enchufar.
Beto
¿Vamos hacia un futuro donde un modelo tiene, a efectos prácticos, memoria estática infinita? Lee y recuerda perfectamente cada libro, cada artículo, cada documento legal, cada escrito. Y su cerebro GPU queda libre para no hacer otra cosa que conectar los puntos. ¿Cómo sería ese mundo?
Alicia
Esa es la pregunta. Si el conocimiento se vuelve una mercancía infinita e instantáneamente accesible, entonces la inteligencia cambia fundamentalmente. Ya no es sobre lo que sabes — porque el modelo lo sabe todo —.
Beto
Se convierte en todo sobre la síntesis.
Alicia
Se convierte en la novedad de las conexiones que puedes hacer, no en la recuperación de los hechos en sí.
Beto
Una máquina que lo sabe todo y que dedica el 100% de su energía a entender qué significa todo eso. Es una imagen realmente poderosa.
Alicia
Sugiere que el futuro de la IA no es solo un cerebro más grande. Es una biblioteca mejor.
Beto
Me encanta eso. Una biblioteca mejor para un cerebro más agudo. Pondremos el artículo completo en las notas del programa. Si quieres profundizar en las matemáticas, vale totalmente la pena leerlo.
Alicia
Es denso, pero muy gratificante.
Beto
Gracias por profundizar con nosotros hoy. Nos vemos en el próximo análisis profundo.



{kind=link}