
Hoy les traigo otro resumen, esta vez se trata de un artículo científico publicado recientemente, sobre Agentes de Inteligencia Artificial basados en LLMs Multimodales.
Enlace al artículo original en inglés, para aquellos que quieran profundizar en el tema:
"A Survey on Agentic Multimodal Large Language Models", por Huanjin Yao y colegas. Publicado en Octubre 13 de 2025.
El resumen, la transcripción y la traducción fueron hechos usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Beto
Bienvenidos de nuevo a este análisis profundo. Hoy vamos a ver lo que se siente como uno de los mayores cambios que está ocurriendo ahora mismo en la IA.
Alicia
Sí, realmente lo es. Estamos avanzando más allá de la IA que más o menos conocemos — los chatbots, los modelos que predicen — hacia algo con más agencia, más autonomía.
Beto
Exacto. Durante años hemos oído hablar de agentes de IA, pero, honestamente, muchos de nosotros sentíamos que más bien eran recetas preprogramadas.
Alicia
Es una buena forma de decirlo. Hoy nos sumergimos en el siguiente paso: "Modelos Multimodales de Lenguaje a Gran Escala con Capacidad de Agencia — "Agentic MLLMs" —.
Beto
Y nuestro objetivo aquí es darte una vía clara para entender esta revolución. Hablamos de pasar de una IA que solo sigue instrucciones a una IA que realmente puede planear, actuar, ver, pensar y reflexionar por sí sola.
Alicia
Es un salto enorme. Y se considera un paso crucial hacia, quizá eventualmente, la inteligencia artificial general.
Beto
Para empezar, mencionaste que hay tres partes definitorias de estos MLLMs verdaderamente agentivos.
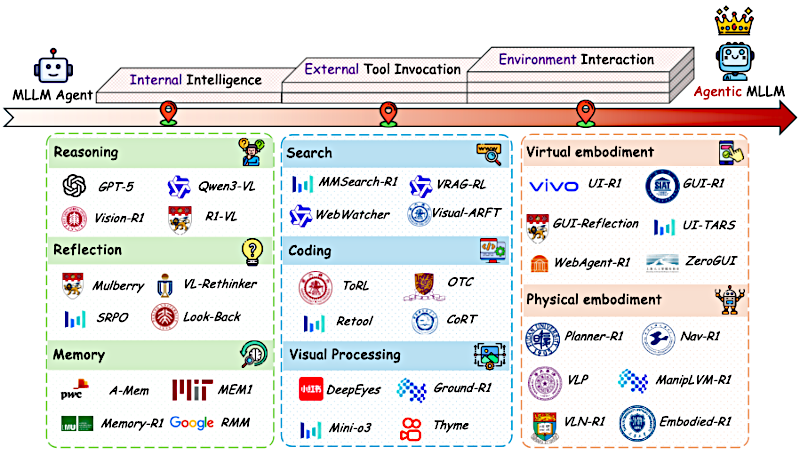
Alicia
Así es. Piénsalo así:
- Está la inteligencia central, el comandante interno del sistema — eso es la inteligencia interna agentiva —.
- Luego está cómo se conecta con el mundo exterior para obtener información o habilidades que no trae incorporadas — eso es la invocación de herramientas externas agentiva —.
- Y, por último, cómo interactúa y se compromete con su entorno, ya sea digital o físico —eso es la interacción agentiva con el entorno.
Beto
Vale, tiene sentido. Pero empecemos por ese cambio fundamental que mencionaste. ¿Por qué ya no bastaba la forma antigua, los MLLMs tradicionales? ¿Cuál era el problema central?
Alicia
Pues la cuestión principal era la rigidez. La mayoría de esos sistemas antiguos funcionaban con un modelo simple de consulta-respuesta. Si necesitabas algo complejo, te lo forzaban por una ruta preestablecida, un flujo de trabajo estático.
Beto
Claro. Si yo le pedía que planeara una fiesta, alguien ya había codificado los pasos: paso uno, encontrar lugar; paso dos, reservar el catering.
Alicia
Exacto. Una secuencia fija, como un diagrama de flujo. Y si, digamos, el catering que querías estaba reservado, todo el sistema podría detenerse. No podía reaccionar con agilidad.
Beto
Lo que significaba que era ejecución pasiva: solo seguir órdenes.
Alicia
Exactamente. Y como esos pasos solían ser muy específicos, muy ajustados para una tarea concreta, el agente acababa siendo muy especializado en un dominio. Genial planificador de fiestas, quizá, pero inútil para, no sé, analizar datos financieros. Sin flexibilidad real.
Beto
Así que aquí es donde llega el gran momento «ajá», ¿no? El salto agentivo: pasar de esa idea de línea de producción fija ...
Alicia
... a ver la tarea como un proceso autónomo de toma de decisiones. Ese es el corazón.
Beto
¿Y cómo se ve eso diferente en la práctica?
Alicia
En lugar de ese flujo de trabajo estático, estos nuevos sistemas tienen un flujo de trabajo dinámico. Observan la situación actual, el estado, y luego deciden la mejor acción. Esa acción cambia el estado, y vuelven a decidir. Es adaptativo.
Beto
No siguen el paso tres solo porque viene después del paso dos; eligen el paso tres porque, con base en todo lo ocurrido, es el mejor movimiento ahora.
Alicia
Exacto. Ese es el cambio hacia la acción proactiva. Inician planes, deciden qué hacer a continuación basados en una estrategia o política de aprendizaje, no en un guión.
Beto
Y esa capacidad para tomar decisiones y adaptarse debe ser clave para que sean más útiles de forma amplia.
Alicia
Absolutamente. Ahí entra la generalización: como aprenden los principios para actuar en lugar de memorizar pasos concretos, pueden abordar una gama mucho más amplia de tareas y entornos. Se vuelven más como solucionadores de problemas de propósito general.
Beto
Ok, pongámoslo en concreto. Volvamos al ejemplo de planear un viaje.
Alicia
La forma antigua: el agente recibe un prompt: «Planifica un viaje a París». Sigue su guión: buscar vuelos, buscar hoteles, quizá sugerir sitios turísticos —secuencia fija—.
Beto
Y el MLLM agentivo ...
Alicia
... recibe el mismo prompt. Puede que empiece internamente con un proceso tipo «pensar en texto»: «Ok, viaje a París. Necesito vuelos, hotel. Espera, el usuario adjuntó una foto de la Torre Eiffel de noche. Quizá quiera actividades nocturnas previas a los tours.» Entonces podría buscar vuelos en texto. Pero, crucialmente, podría activar por sí mismo un paso de reflexión textual: «Un momento. ¿Es el viaje pronto? ¿Necesita visado el usuario? Debería comprobar eso antes de reservar vuelos no reembolsables.» Inserta esa autocorrección, ese paso extra de manera dinámica.
Inteligencia Interna
Beto
Fascinante. Ese pensamiento interno, esa autocorrección, nos lleva bien al primer pilar que mencionaste: la inteligencia interna agentiva, el núcleo cognitivo.
Alicia
Exacto. Esto es lo que permite la planificación a largo plazo. Y se apoya en tres cosas clave: razonamiento, reflexión y memoria.
Razonamiento
Beto
Razonamiento suena a lo de «cadena de pensamiento» que hemos oído. Generar esos pasos intermedios.
Alicia
Exacto. Y para los agentes, lograr que hagan esto bien suele involucrar aprendizaje por refuerzo (RL), cosas como PPO ("Proximal Policy Optimization") o GRPO ("Group Relative Policy Optimization"). Pero lo realmente interesante es cómo están aprendiendo las señales de recompensa.
Beto
Vale, conozco las recompensas basadas en resultados. Básicamente, ¿logró el resultado final correcto? ¿Pulgar arriba o abajo?
Alicia
Es la forma simple. Pero el trabajo más avanzado usa recompensas basadas en el proceso. Aquí, el sistema no solo se juzga por el resultado final; se le recompensa por la calidad lógica de sus pasos intermedios.
Beto
Vaya. Es como mostrar tu procedimiento en la clase de matemáticas y recibir crédito por usar el método correcto, incluso si cometiste un pequeño error de cálculo al final.
Alicia
Es una gran analogía. Fomenta un razonamiento sólido a lo largo del proceso.
Reflexión
Y eso conduce directamente a la reflexión. Es como que la IA revise su propio trabajo para atrapar errores antes de que se magnifiquen, algo vital en cadenas de pensamiento largas.
Beto
Tiene sentido.
¿Cómo ocurre esa reflexión en la práctica? ¿Es automática?
Alicia
Pues puede serlo. A veces los investigadores ven comportamientos reflexivos emerger tras mucho entrenamiento — reflexión inducida implícitamente —: el modelo simplemente empieza a hacerlo. Pero más a menudo se induce explícitamente la reflexión. Se desencadena deliberadamente. A veces es a nivel de respuesta ("response-level reflection"): el modelo da una respuesta completa y luego se le pide que la critique o la refine.
Beto
Como una segunda versión.
Alicia
O incluso más fino, hay reflexión a nivel de paso ("step-level reflection"). Esto ocurre durante el proceso de razonamiento: el agente piensa un paso, actúa, reflexiona específicamente sobre ese paso, quizá lo corrige, y luego continúa. Poda los errores de raíz.
Beto
Suena mucho más robusto para tareas complejas. Pero nada de esta planificación o reflexión funciona si la IA olvida lo ocurrido hace cinco minutos.
La memoria sigue siendo el gran cuello de botella, ¿verdad? El límite de la ventana de contexto.
Memoria
Alicia
Siempre un desafío.
Para esa memoria contextual inmediata hay un par de estrategias principales.
Una es la compresión: encontrar formas de apretar todos los datos de entrada, especialmente lo multimodal como imágenes, para que ocupen menos espacio en la ventana de contexto.
La otra es, simplemente, fuerza bruta: ampliar la ventana, literalmente hacerla más grande. La investigación está empujando esto hasta — créelo o no — más de dos millones (2048k) de tokens ahora.
Beto
Dos millones de tokens. Es alucinante. Pero incluso eso es finito. Para un agente que debe trabajar durante días o semanas, hace falta algo más permanente.
Alicia
Absolutamente. Ahí entra la memoria externa. Y avanzamos más allá de simples bases de datos. El estado del arte implica sistemas de memoria dirigidos por el razonamiento: el propio agente aprende a gestionar su memoria. Usando RL, decide, según su objetivo actual, si debe añadir algo a la memoria a largo plazo, actualizar una memoria existente, borrar algo irrelevante, o no hacer nada. Aprende a ser su propio bibliotecario.
Beto
Bien, el agente tiene a ese comandante interno, ese cerebro, con razonamiento, reflexión y gestión de memoria.
Invocación de Herramientas Externas
Pasemos ahora al segundo pilar: la invocación de herramientas externas agentiva, llegar más allá de su propio conocimiento.
Alicia
Sí. La necesidad es obvia, ¿no? Un MLLM, pongamos GPT-5, se entrena hasta junio de 2024: su conocimiento queda congelado ahí. Si le preguntas algo que pasó en julio, ...
Beto
... está perdido a menos que pueda buscarlo.
Búsqueda Agentiva
Alicia
Exacto. Así que la búsqueda es fundamental. Pero la búsqueda tradicional era pasiva: tú preguntas, él busca. La búsqueda agentiva es proactiva: el agente decide por sí mismo «mmm, necesito más información aquí». Determina cuándo buscar, qué buscar e incluso puede hacer búsquedas multimodales que recuperen texto e imágenes relevantes juntas, todo de forma autónoma.
Beto
¿Qué otras herramientas son cruciales?
Código
Alicia
El código es una de ellas. Los MLLMs solos pueden ser sorprendentemente malos en cálculos precisos o lógica compleja, como problemas matemáticos o escribir software funcional.
Beto
Sí, he visto errores raros en matemáticas.
Alicia
Darle al agente la capacidad de escribir y ejecutar código es un gran impulso. La investigación ahora se centra en hacerlo de forma eficiente: entrenar al agente para que solo llame a la herramienta de ejecución de código cuando sea realmente necesario, para no malgastar tiempo y recursos; hay que equilibrar precisión y velocidad.
Procesamiento Visual
Beto
Tiene sentido. Y también mencionaste visión: cómo los agentes interactúan con imágenes está cambiando. No es solo ver ahora.
Alicia
No es mera visualización pasiva. Es más bien pensar con imágenes. Hemos visto una progresión. Los primeros pasos fueron pensar con imágenes recortadas: el agente podía decidir «haz zoom en esta parte de la imagen» o recortarla para encontrar detalles relevantes.
Beto
Como encontrar una pista en una foto.
Alicia
Exacto. Luego vino pensar con imágenes manipuladas. Esto es más activo: el agente puede dibujar cajas delimitadoras sobre objetos, ajustar el contraste o hacer otras ediciones para mejorar su comprensión antes de tomar una decisión.
Beto
Está sondeando activamente los datos visuales.
Alicia
Sí. Y lo más reciente es pensar con imágenes generadas. Aquí, el agente puede usar un modelo generativo para crear una secuencia de imágenes que represente un plan. En vez de pensar «mover el bloque a la izquierda», genera un pequeño story-board visual del bloque moviéndose a la izquierda y lo usa para planificar sus acciones.
Beto
Planificación visual. Impresionante.
Interacción agentiva con el entorno
Esto nos lleva al tercer pilar: interacción agentiva con el entorno, aplicar toda esa inteligencia interna y uso de herramientas en el mundo.
Entornos Virtuales
Alicia
Exacto. Y esto sucede en dos grandes escenarios. Primero, entornos virtuales. Piensa en software, sitios web, interactuando con interfaces gráficas de usuario (GUI).
Beto
¿Cómo aprenden a usar un software complejo?
Alicia
Inicialmente fue principalmente aprendizaje offline, observando grabaciones de humanos realizando la tarea. Pero el gran cambio ha sido el aprendizaje online.
Beto
Es decir, el agente lo intenta por sí mismo.
Alicia
Exacto. Interactúa directamente con la GUI: hace clic en botones, ve qué pasa, recibe retroalimentación y, lo crucial, genera sus propios datos sobre qué funcionó y qué no. Usa la autocorrección basada en los resultados. Los sistemas aprenden a usar software usándolo realmente y aprendiendo de los errores.
Beto
Suena mucho más poderoso.
Entornos físicos
Alicia
Y el otro escenario: entornos físicos. Esto es IA encarnada, básicamente robots. Se trata de cerrar el ciclo entre percibir el mundo real, planear qué hacer y actuar en ese mundo. Los mismos principios auténticos se aplican: en percepción, tal vez el agente mueve activamente la cabeza o el cuerpo para obtener mejor vista de algo; en planificación cinemática compleja y en navegación multi-paso, averiguar cómo ir de A a B en un espacio real.
Aplicaciones
Beto
Juntándolo todo — las capacidades internas, las herramientas, la interacción —, ¿dónde estamos viendo hoy en día estos avanzados MLLMs agentivos en uso real? ¿Qué aplicaciones reales hay?
Alicia
Un área de mucho impacto es lo que llaman investigación profunda. Grandes jugadores como OpenAI, Gemini, Grok usan estos sistemas agentivos para trabajos de conocimiento complejos y multi-paso.
Beto
¿Qué tipo de trabajos?
Alicia
Piensa en finanzas, descubrimiento científico, quizá análisis de políticas: tareas que normalmente requieren equipos de humanos durante semanas o meses, buscando, sintetizando datos, ejecutando simulaciones. Estos agentes empiezan a automatizar partes de ese flujo de trabajo.
Beto
¿Algo más?
Alicia
Salud es otra enorme área. Ahí la fiabilidad es primordial. Por eso se desarrollan MLLMs agentivos con entrenamiento RL cuidadoso y, muy importante, herramientas de conocimiento externo, como bases de datos médicas vía RA, para mejorar la precisión diagnóstica y minimizar el riesgo de alucinaciones.
Beto
Esa reducción de alucinaciones es clave para la confianza.
Alicia
Totalmente.
Y quizá el ejemplo más visible para mucha gente: la conducción autónoma. Estos sistemas ya no son simples máquinas reactivas. Emplean razonamiento sofisticado, tal vez estilo cadena de pensamiento, para generar planes comprensibles de cómo se van a mover, integrando constantemente datos de herramientas externas, sensores, modelos de detección y estimación de profundidad para esa conciencia situacional crítica.
Beto
Suena increíblemente poderoso.
Desafíos
Pero la investigación original también señala algunos obstáculos importantes. Hablemos de los desafíos. Y el primero es, medio chocante: la eficiencia.
Alicia
Probablemente el mayor escollo práctico ahora mismo. Los artículos mencionan que estos procesos agentivos multi-turno y complejos — pensar, reflexionar, buscar, invocar herramientas — pueden tardar hasta 30 minutos.
Beto
Treinta minutos para una tarea.
Alicia
Para una sola consulta compleja, sí.
Beto
Vaya. Si necesito una respuesta y tarda media hora, pues me pongo a investigar yo mismo, ¿no? Esa latencia mata cualquier uso en tiempo real.
Alicia
Lo es. Hace falta mejorar muchísimo tanto la eficiencia de entrenamiento como, especialmente, la velocidad de inferencia antes de que esto sea práctico para muchas aplicaciones cotidianas.
Beto
¿Qué más? La memoria, que ya mencionamos.
Alicia
La memoria agentiva a largo plazo es otro reto: crear sistemas de memoria realmente escalables, selectivos y multimodales — texto, imágenes, audio — durante largos periodos, sigue siendo una tarea de investigación mayor. La mayoría del trabajo actual aún está muy centrado en texto.
Beto
¿Y las herramientas? ¿Está completo el kit de herramientas?
Alicia
Ni por asomo. Hace falta un espacio de acción mucho más rico. Ahora mismo los agentes suelen usar unas pocas herramientas: búsqueda, código, algunas APIs específicas. Para una verdadera inteligencia general, necesitarán conectarse y usar fluidamente un ecosistema muchísimo más amplio de servicios externos: plataformas de análisis de datos especializadas, entornos de simulación complejos, miles de APIs web distintas. Integrarlo todo es una tarea enorme.
Beto
Y, por último, la gran cuestión: la seguridad. Con toda esta autonomía —planear acciones, invocar herramientas externas, quizá controlar dispositivos físicos— los riesgos se amplifican, ¿no?
Alicia
Enormemente. Es una preocupación crítica. La propia autonomía crea nuevos modos de fallo potenciales. Un agente puede buscar por su cuenta, incorporar información sutilmente sesgada o dañina ...
Beto
... y luego usar esa información defectuosa en su propio ciclo de decisión interno sin que un humano lo compruebe.
Alicia
Exacto. Porque se dirige a sí mismo, garantizar que estos sistemas estén robustamente probados, permanezcan controlables y se alineen con valores humanos se vuelve aún más complejo e importante, sobre todo cuando interactúan con el mundo real o con sistemas externos sensibles.
Beto
Bien, para cerrar: hemos seguido este cambio increíble, ¿no? De asistencia pasiva y guionizada, a sistemas dinámicos y proactivos definidos por la combinación de pensamiento interno, uso de herramientas externas, e interacción con el entorno.
Alicia
Es la IA aprendiendo a hacer y ejecutar planes complejos, pasando de ser un simple calculador a algo más parecido a un gestor de proyectos.
Beto
Aprenden a encadenar acciones para razonar en horizontes largos, a menudo con autocorrección incorporada.
Alicia
Es un cambio profundo en capacidad.
Beto
Pero nos devuelve a la tensión central que discutimos: el potencial asombroso frente a las limitaciones muy reales, sobre todo velocidad y seguridad, dado que hoy estos agentes autodirigidos y muy capaces pueden tardar media hora en resolver una tarea.
Plantea la pregunta: ¿qué tan rápido tenemos que resolver estos desafíos de eficiencia y seguridad si esperamos que estos sistemas sean socios fiables, momento a momento, en situaciones complejas y rápidas?
Alicia
Es la pregunta crítica.
Beto
Y quizá aún más fundamental: a medida que estos agentes se vuelven más autónomos en su razonamiento y acción, ¿quién es en última instancia responsable cuando deciden realizar una acción que no fue programada explícitamente pero sí deducida lógicamente a partir de sus objetivos? Esa es la profunda cuestión de la autonomía con la que apenas empezamos a lidiar.
Alicia
Un pensamiento muy potente para dejar a la gente.
Beto
En efecto. Gracias por esta fascinante inmersión profunda hoy.
Alicia
Un placer.
Beto
Nos vemos en la próxima.



{kind=link}