
Hoy les traigo el resumen de otro artículo científico interesantísimo, sobre Inteligencia Artificial. Desde el comienzo de este año (2025) empezamos a ver modelos de lenguajes de razonamiento ("Reasoning Language Models", RLMs), con resultados impresionantes. Estos definen la vanguardia de la Inteligencia Artificial, y el camino hacia AGI ("Artificial General Intelligence", Inteligencia General Artificial). Queremos saber qué mecanismos se emplean para hacer esto posible.
El enlace al artículo original, en inglés, es el siguiente, para aquellos interesados en profundizar en el tema:
"Reasoning Language Models: A Blueprint", por Maciej Besta y colegas, publicado en Junio 11 de 2025.
El resumen, la transcripción y la traducción fueron hechas usando herramientas de software de Inteligencia Artificial.
El resumen se presenta en la forma de un diálogo entre dos personajes sintéticos que llamaremos Alicia y Beto.
Resumen
Alicia
Bienvenidos de nuevo a este análisis profundo. Hoy vamos directamente al corazón de lo que viene en IA: los Modelos de Lenguaje de Razonamiento, RLMs ("Reasoning Language Models").
Beto
Sí, son los sistemas de los que la gente habla ahora. Cosas como o1 de OpenAI, quizá o3, DeepSeek-R1, QwQ; representan un cambio bastante significativo.
Alicia
Un cambio respecto a los LLMs ("Large Language Models") estándar a los que nos habíamos acostumbrado.
Beto
Exacto. Estos RLMs están, bueno, diseñados para ser la nueva piedra angular de la IA seria. Integran toma de decisiones complejas y planificación. Ya no se trata solo de lenguaje.
Alicia
Sí. Se está moviendo la IA de solo responder, a resolver activamente problemas.
Beto
Ese es el objetivo: resolución activa de problemas.
Alicia
Bien, deshagamos esto porque aquí hay un gran problema, ¿no? El acceso. Construir estas cosas — estos modelos de razonamiento realmente potentes — es increíblemente caro.
Beto
Oh, enormemente. Costes masivos, necesitan datos muy específicos y a menudo propietarios, y equipos de ingeniería enormes.
Alicia
Lo que lleva a este riesgo, esta brecha entre "IA rica" e "IA pobre" de la que oyes hablar.
Beto
Es una preocupación muy real. Podríamos acabar con un puñado de grandes actores controlando la IA de razonamiento más avanzada. Así que nuestra misión hoy es desglosarlo.
Alicia
Correcto. Entramos en este nuevo plan, una especie de marco unificado para entender y construir RLMs. Es modular.
Beto
Y esa modularidad es clave. Viene con un marco de código abierto llamado x1 que está diseñado para hacer el diseño de RLMs más accesible, para democratizarlo, esencialmente.
Alicia
Sacarlo de las manos de los incumbentes.
Beto
Precisamente.
También hay un cambio conceptual central. Piensa en cómo funcionan los LLMs estándar. Mayormente operan en lo que los psicólogos llaman "pensamiento de sistema uno".
Alicia
Rápido, intuitivo, emparejamiento de patrones, predecir la palabra más probable siguiente.
Beto
Exacto. Genial para fluidez, para escribir texto que suena natural. Pero los RLMs incorporan "pensamiento de sistema dos".
Alicia
El razonamiento lento, deliberado, paso a paso. Como hacer matemáticas frente a reconocer una cara.
Beto
Es una analogía perfecta. El sistema uno reconoce la cara al instante. El sistema dos tiene que trabajar deliberadamente, por ejemplo, calculando una raíz cuadrada. Los RLMs están construidos para ese proceso deliberado.
Alicia
Combinar el conocimiento del LLM con búsqueda y planificación estructuradas.
Beto
Sí. Esa combinación es lo que desbloquea la resolución real de problemas.
Los Pilares
Alicia
¿Cómo llegamos hasta aquí? ¿Qué tuvo que converger para hacer estos RLMs posibles? Vamos a la sección uno: los pilares.
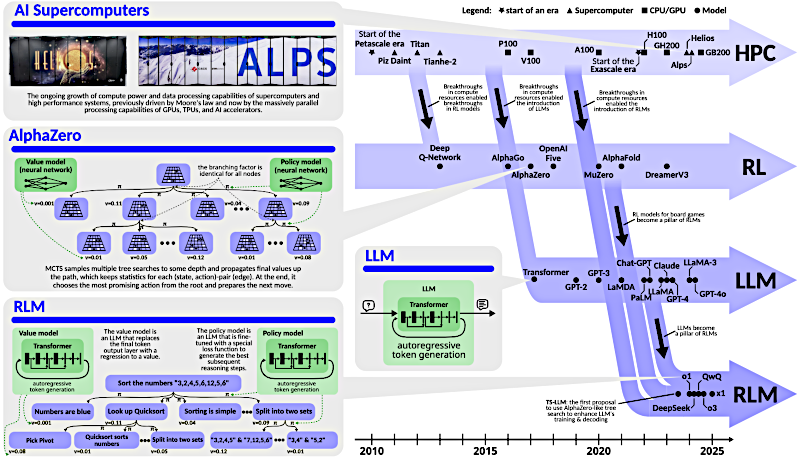
Beto
No fue solo una cosa. Fue la convergencia de tres áreas clave, madurando más o menos al mismo tiempo.
Alicia
Primero, obviamente, necesitas los grandes modelos de lenguaje. Los LLMs tienen el conocimiento, la comprensión del lenguaje.
Beto
Miles de millones de parámetros que codifican conocimiento del mundo. Absolutamente esenciales. Pero su debilidad, como dijimos, es que el razonamiento también es superficial. Es un emparejador estadístico de patrones.
Alicia
Autoregresivos. Siempre prediciendo el siguiente token más probable según los datos de entrenamiento.
Beto
Lo que significa que si un patrón de razonamiento no era común en los datos, tienen problemas. Pueden atascarse. Saben el qué. Pero no necesariamente cómo averiguar algo nuevo.
Alicia
Bien, entonces el LLM es la base de conocimiento.
El pilar 2 introduce el cómo.
Beto
Eso es el aprendizaje por refuerzo, RL ("Reinforcement Learning"). Este es el marco para la toma de decisiones, para aprender mediante ensayo y error, para la exploración.
Alicia
Como AlphaZero aprendiendo Go o Ajedrez.
Beto
Es exactamente como AlphaZero. RL permite a los sistemas descubrir estrategias completamente novedosas. Cosas que los expertos humanos podrían pasar por alto. ¿Recuerdas esa famosa jugada de AlphaZero en Go? Parecía un error al principio, ...
Alicia
... pero resultó ser brillante. Esa capacidad de explorar, de ir más allá de los patrones conocidos, parece crítica.
Beto
Lo es. Es lo que permite la extrapolación, de la que hablaremos. Pero ni la enorme base de conocimiento ni la exploración compleja funcionan a escala sin el tercer pilar:
Alicia
Computación de alto rendimiento, HPC ("High-Performance Computing").
Beto
Sí, esto es crucial y a veces se pasa por alto. La ley de Moore se está desacelerando para los chips tradicionales. Pero los RLMs necesitan combinar la enorme huella de memoria de los LLMs con las intensas demandas computacionales de algoritmos de búsqueda RL como MCTS ("Monte Carlo Tree Search").
Alicia
Así que necesitas hardware serio: GPUs, TPUs.
Beto
Procesamiento masivamente paralelo. Estás buscando potencialmente en árboles enormes de posibilidades mientras consultas constantemente al LLM por conocimiento. HPC proporciona la potencia para realmente fusionar conocimiento con exploración a escala.
Alicia
Esos son los pilares:
- LLMs para el conocimiento,
- RL para la exploración y la toma de decisiones,
- HPC para la escala.
Esto nos lleva a la diferencia clave que mencionaste: interpolación versus extrapolación.
Interpolación (LLMs) vs Extrapolación (RLMs)
Beto
Exacto. Este es el momento “ajá”. Los LLMs estándar en su mayoría hacen interpolación. Son maestros en trabajar dentro de los patrones aprendidos de sus datos de entrenamiento, sintetizando información existente.
Alicia
Básicamente se quedan dentro de las líneas.
Beto
Sí. Pero los RLMs, al combinar ese conocimiento del LLM con una búsqueda RL estructurada, permiten extrapolación. Pueden realmente navegar fuera de los límites de los patrones de entrenamiento.
Alicia
Generar soluciones genuinamente novedosas. Cosas que no han visto explícitamente antes.
Beto
Esa es la idea: pasar de completar patrones, a descubrir activamente nuevas soluciones en territorio inexplorado. Ese es el salto.
Jerarquías de RLMs
Alicia
Dentro de los RLMs parecen existir dos sabores principales según cómo implementen este razonamiento.
Beto
En términos generales, sí. Tienes RLMs implícitos. Piensa en QwQ aquí. La capacidad de razonamiento en esta estructura está integrada directamente en los pesos del modelo durante el entrenamiento.
Alicia
Es como una caja negra que razona, pero es difícil ver exactamente cómo.
Beto
A menudo, sí. Pueden ser muy eficaces, pero menos transparentes.
Luego tienes RLMs explícitos.
Alicia
Es como LLaMA-Berry.
Beto
Estos modelos usan mecanismos de razonamiento externos identificables. Por ejemplo, acoplar explícitamente un LLM con un módulo separado de "búsqueda en árbol Monte Carlo" (MCTS). Puedes ver el proceso de búsqueda sucediendo.
Alicia
Más interpretable, tal vez más flexible.
Beto
Generalmente, sí. Como siempre, compensaciones (una cosa por otra).
Alicia
Tenemos las bases: la convergencia de los tres pilares, la idea central de extrapolación y los enfoques implícitos versus explícitos. Pero, ¿cómo construimos realmente estas cosas sin necesitar recursos al nivel de Google? ¿Cómo evitamos ese problema de la "IA rica" y "la IA pobre"?
El Blueprint
Beto
Y eso nos lleva a la sección dos: el propio blueprint. Esto no es solo teoría. Es una caja de herramientas modular práctica para diseñar y experimentar con RLMs.
Alicia
Una caja con cuatro partes principales: esquemas, operadores, modelos y pipelines.
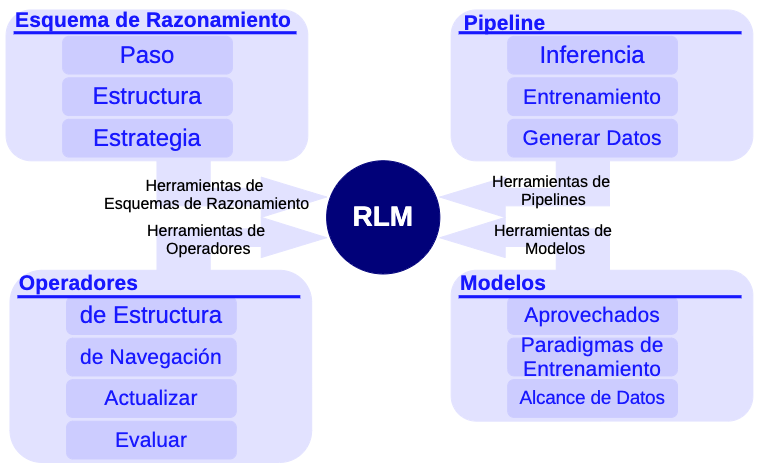
Esquemas de Razonamiento
Empecemos por los esquemas de razonamiento. ¿Qué son?
Beto
Los esquemas definen la estructura del proceso de razonamiento y la estrategia usada para navegar esa estructura.
Alicia
Estructura primero.
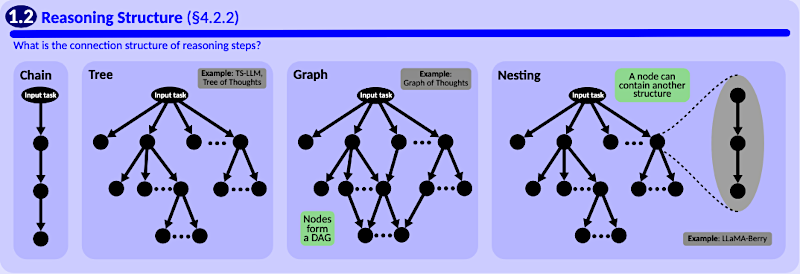
Conocemos las cadenas básicas, ¿no? Como la cadena de pensamiento (CoT, "Chain of Thought"). Paso A conduce a B conduce a C.
Beto
La forma más simple. Pero el razonamiento real es más desordenado. Así que el blueprint soporta árboles ("Trees"). Piensa otra vez en MCTS: ramificación jerárquica. Explorar múltiples posibilidades en paralelo.
Alicia
Como un árbol de decisiones.
Beto
Exacto. Y grafos ("Graphs"). Estos permiten conexiones mucho más complejas. Piensa en un grafo de pensamientos donde un paso de razonamiento puede enlazar de vuelta a múltiples pasos previos, no solo a su padre directo. Crear ciclos, permitir síntesis.
Alicia
Bien. Cadenas, árboles, grafos y luego estructuras anidadas ("Nesting"). Interesante.
Beto
Lo es. Es como si un nodo del árbol principal contuviera a su vez toda una cadena detallada de pensamiento para resolver su propio valor o siguiente paso.
Alicia
Razonamiento meta.
Beto
Más o menos. LLaMA-Berry aparentemente usa algo así. Permite distintos niveles de detalle deliberativo.
Alicia
Esas son las estructuras.
¿Y las estrategias para construir y explorarlas?
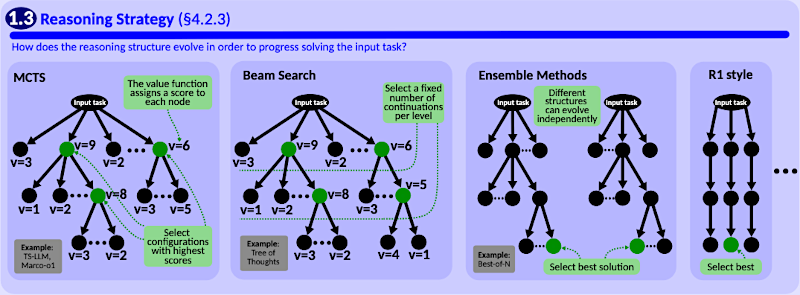
Beto
Esa es la otra parte del esquema. Estrategias comunes incluyen la "búsqueda en árbol Monte Carlo", MCTS ("Monte Carlo Tree Search"), muy popular por equilibrar exploración de rutas nuevas versus explotación de las prometedoras.
Alicia
También está la "búsqueda por haces" ("Beam Search").
Beto
De acuerdo, que es más agresiva: mantiene solo las mejores rutas en cada paso, descartando el resto más rápido, pero puede perder la solución óptima a veces.
Alicia
Y métodos ensemble, como FoT ("Forest of Thought"), y BoN ("Best-of-N").
Beto
Correcto. Ejecutar múltiples procesos de razonamiento quizá con parámetros o prompts distintos y luego escoger el mejor resultado o agregarlos de alguna forma para mayor robustez.
Alicia
Entonces, los esquemas nos dan la estructura y la estrategia de navegación.
Operadores
El siguiente elemento en la caja de herramientas son los operadores: los verbos de acción.
Beto
Exacto. Son las acciones específicas que el sistema realiza para manipular la estructura de razonamiento definida por el esquema. Aquí es donde sucede la deliberación dinámica.
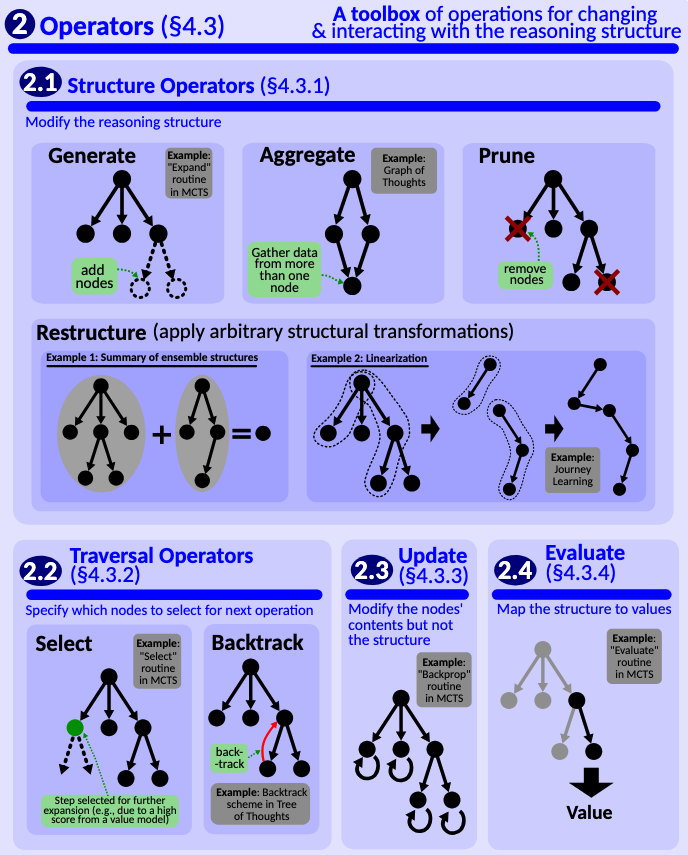
Alicia
Obvio: generate, añadir un nuevo paso.
Beto
Normalmente hecho por el LLM principal, el modelo de política. Pero los más interesantes imitan cómo pensamos críticamente.
Alicia
Como prune, que suena a organizar.
Beto
Lo es. Prune elimina activamente ramas o nodos en la estructura de razonamiento que parecen poco prometedores o irrelevantes. Como tachar callejones sin salida en tus notas.
Alicia
Es principalmente para enfocar la búsqueda.
Beto
Sí. Y, críticamente, como destaca la fuente, a menudo se usa para reducir el coste en tokens. Menos tokens procesados significa inferencia más rápida y barata. La eficiencia importa.
Alicia
Todos podríamos usar un operador prune a veces.
Luego restructure. ¿Qué hace?
Beto
Aplica transformaciones más complejas a la estructura de razonamiento. El ejemplo viene de Journey Learning. Imagina que exploraste un gran árbol frondoso de ideas. El operador restructure puede luego linearizar las ideas clave de ese árbol en una sola cadena coherente de pensamiento como salida. Sintetiza la exploración en un plan final o una explicación.
Alicia
Convertir una lluvia de ideas desordenada en un informe claro, me gusta eso.
Y finalmente backtrack.
Beto
Crucial para el pensamiento riguroso. Backtrack significa volver explícitamente a un punto anterior en el proceso de razonamiento para explorar una ruta alternativa que antes descartaste o ignoraste.
Alicia
La IA se da cuenta de “espera, quizá esa suposición que hice hace tres pasos estaba mal; vamos a revisarla”.
Beto
Precisamente. Permite que el sistema corrija su curso. Y, curiosamente, el análisis sugiere que incluso modelos implícitos como QwQ muestran comportamientos en sus trazas de entrenamiento consistentes con haber aprendido una capacidad interna de retroceso (backtracking).
Alicia
Con esquemas y operadores, este blueprint realmente se siente como una receta para construir máquinas que piensan, no solo predictores de texto.
Pasemos a la sección tres: ¿cómo enseñas a estos sistemas a usar estas herramientas eficazmente?
Señales de entrenamiento, modelos, eficiencia
Beto
Bien. Debido a que los datos de entrenamiento tienen que reflejar la complejidad del razonamiento que quieres que el modelo aprenda. El blueprint discute tres niveles de supervisión.
Alicia
Empieza con la más simple: supervisión basada en el resultado (OBS, "Outcome-Based Supervision").
Beto
OBS es muy escasa. Es como calificar un examen de matemáticas mirando solo la respuesta final: correcto o incorrecto. Eso es todo.
Alicia
El modelo recibe muy poco feedback sobre cómo llegó allí.
Beto
Exacto. Sabe si falló, pero no dónde estuvo el error. Fácil de recopilar, pero no bueno para aprender razonamiento complejo.
Alicia
Ok. Subimos un nivel: supervisión basada en el proceso (PBS, "Process-Based Supervision").
Beto
PBS es mucho más densa. Es como tener a un experto calificando cada paso de la resolución matemática. Cada paso intermedio recibe una puntuación de calidad.
Alicia
Ah, entonces el modelo aprende qué pasos individuales son buenos o malos.
Beto
Sí. Mucho mejor para aprender razonamiento fino. Pero, como te puedes imaginar, conseguir esas anotaciones detalladas de expertos es muy difícil y caro.
Alicia
Ok. OBS es demasiado escasa. PBS es cara. El blueprint introduce una tercera vía: supervisión basada en trazas (TBS, "Trace-Based Supervision").
Beto
Esto es clave. Si PBS se centra en la calidad de cada paso, TBS añade información sobre el propio proceso: la secuencia de operadores usados.
Alicia
Así que: No solo “este paso fue bueno”, sino “aquí el modelo generó, luego podó esta rama, luego retrocedió”.
Beto
Exacto. Trata de enseñar al modelo la dinámica del razonamiento, cómo navegar y manipular su propio proceso de pensamiento usando operadores como prune y restructure.
Alicia
La meta es entrenar RLMs implícitos para internalizar esas dinámicas explícitas de razonamiento sin depender del andamiaje externo durante la inferencia.
Beto
Esa parece ser la ambición: Enseñar el flujo de trabajo del pensamiento, no solo el contenido. Es una idea fascinante para construir razonadores más potentes y autosuficientes.
Alicia
Brevemente sobre los modelos involucrados en el entrenamiento de valor y recompensa: el artículo sugiere un tipo específico para RLMs.
Beto
Sí, sobre todo cuando se enfrentan a recompensas escasas. Recomiendan modelos de valor Q basados en procesos, PQVMs ("Process-based Q-Value Models").
Alicia
¿Qué hace un PQVM?
Beto
Un Q-value estándar predice la recompensa total futura. Un PQVM intenta estimar el valor o la calidad de estados o pasos intermedios del razonamiento, incluso cuando la recompensa final está lejos. Proporciona esa señal más densa necesaria para guiar búsquedas como MCTS de forma efectiva.
Alicia
Tiene sentido. Necesitas saber si vas por buen camino, paso a paso.
Volviendo a la meta de democratización: todo este blueprint está implementado en un marco de código abierto llamado x-1. ¿Cómo ayuda x-1 a equipos más pequeños?
Beto
Aborda la complejidad y las barreras de infraestructura. No necesitas reinventar la rueda — codificar MCTS, los distintos operadores o los pipelines de entrenamiento. x-1 provee estos como bloques modulares.
Alicia
Así los equipos pueden centrarse en su problema específico, sus datos, sus modelos de política y valor, y cambiar rápidamente esquemas u operadores para experimentar.
Beto
Esa es la idea: bajar la barrera de entrada para RLMs sofisticados.
Alicia
Dentro de este marco hay una idea crucial sobre eficiencia: el cómputo en tiempo de prueba, TTC (Test-Time Compute). Encontré esto fascinante. Optimizar el TTC puede ser hasta cuatro veces más efectivo que simplemente agrandar el modelo. ¿Cómo?
Beto
Es una poderosa constatación que contradice la tendencia “más grande siempre es mejor”. TTC trata de asignar más cómputo durante la inferencia a problemas más difíciles, dinámicamente.
Alicia
Como hacen los humanos: pensamos más intensamente sobre preguntas complicadas.
Beto
Exacto. No creces un cerebro más grande de repente; gastas más energía mental, más tiempo deliberando. Los RLMs pueden hacer esto usando los operadores.
Alicia
Para un problema duro, el sistema puede usar más el operador generate, explorar más ramas, o usar refine para iterar en un paso varias veces.
Beto
Preciso. Escala el esfuerzo según la dificultad del problema, en lugar de depender solo del tamaño estático del modelo. Y esa asignación dinámica, ese pensamiento dirigido, puede dar ganancias mucho mayores que añadir parámetros.
Alicia
Tiene sentido intuitivo, y hay un consejo práctico más del estudio sobre entrenamiento.
Beto
Sí, recomiendan una estrategia de entrenamiento en dos fases. Primero, fine-tuning supervisado (SFT, "Supervised Fine-Tuning") usando datos basados en procesos o incluso basados en trazas ...
Alicia
... para enseñar al modelo los patrones básicos y el flujo de trabajo del razonamiento.
Beto
Correcto. Construir una base sólida. Luego, afinar con aprendizaje por refuerzo en escenarios más dinámicos y complejos. Empezar directamente con RL puede ser inestable; SFT primero da robustez.
Alicia
En resumen, este blueprint — con esquemas, operadores, señales de entrenamiento como TBS, el marco x-1 y el foco en TTC — es una guía integral.
Beto
Lo es. Busca desmitificar la construcción de RLMs, quitarles el carácter de arte oscura y, con suerte, mitigar esa brecha entre "IA rica" e "IA pobre" de la que hablamos.
Alicia
Provee las herramientas y el entendimiento para que más gente construya y experimente con estos sistemas avanzados de razonamiento.
Beto
Exactamente. Articula un camino desde la predicción intuitiva hacia una resolución de problemas más deliberada y estructurada por parte de la IA. El desglose detallado es un regalo para la comunidad investigadora.
Alicia
Pensando en las implicaciones, sobre todo la idea de la supervisión basada en trazas — enseñar a los modelos no solo los pasos, sino cómo gestionar dinámicamente su propio razonamiento.
Beto
Si ese enfoque realmente funciona y conseguimos que los RLMs implícitos internalicen efectivamente estas dinámicas complejas, surge una pregunta provocadora para ti, oyente:
Alicia
¿Qué tipos de problemas, hoy considerados demasiado difíciles para la IA sin muchas herramientas externas o guía humana, podrían estos agentes de próxima generación resolver enteramente por sí mismos? Si llegan a manejar verdaderamente su propio proceso de pensamiento, ¿qué se vuelve posible?
Beto
Responder eso probablemente definirá el próximo gran salto en capacidades de IA. Es, sin duda, la dirección hacia la que apunta todo.
Alicia
Un lugar fascinante para dejarlo. Gracias por acompañarnos en este análisis profundo hoy.
Beto
Un placer.
Alicia
Nos vemos la próxima vez.



{kind=link}